







引言
本篇主要想总结一下最近打的GISLR比赛,本来是没想写的,比赛前期感觉赛题很有意思,做了eda以及根据一些base改了改自己的方案,取得了还不错的结果,但因为中途被各种琐事缠身,发生了很多变故,也同时在思考很多东西,结果就是五一劳动节发现还剩两天了,急急忙忙再重新上号开始整理,那结果很显然,蛙佬的实验报告没有看完整,我搞错了方向,以为是不能过拟合,最后两天根据best public 加一些我自己理解的策略去降拟合,结果打铁了。。。事实证明,这次又被Google坑了,真是过拟合赛,emmm,但最终让我想写的原因是,有个大佬对最开始前排的方案做了非常详细的中文注释,让我看得太爽了,所以想在这里记录一下。
赛题分析
这道赛题还是很有意思的。
The goal of this competition is to classify isolated American Sign Language (ASL) signs. You will create a TensorFlow Lite model trained on labeled landmark data extracted using the MediaPipe Holistic Solution.
Your work may improve the ability of PopSign* to help relatives of deaf children learn basic signs and communicate better with their loved ones.^
赛题理解就是最终需要上传一个tflite,这个模型是基于视频坐标信号的手势标志分类。手势种类有大概有200多种,比较常用的如下图形式:
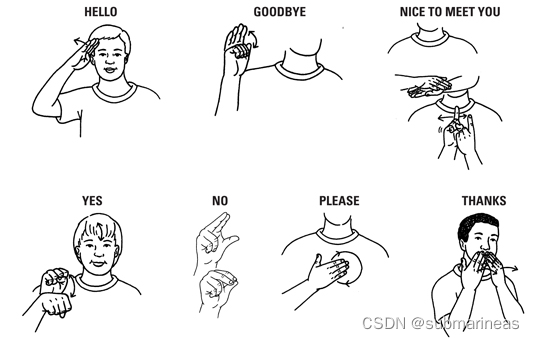
但赛题的数据集并不是基于视频流的形式,而是官方已经提取好了人的上半身的特征点,做成了train_landmark_files/[participant_id]/[sequence_id].parquet 形式,这些landmark都是使用 MediaPipe 整体模型从原始视频中提取出来的,提取的类型分为了[‘face’, ‘left_hand’, ‘pose’, ‘right_hand’],总共543个points,具体可以看如下GIF:

把背景人像去除后,就类似于火柴人的形式:

有点抽象,emmm,这是我从前排大佬的eda里找到的图,这个手势代表着airplane,这个可视化相当于脸部的landmark没动,但把身子和手部连起来了(PS:这里再贴出有大佬做的长视频,需要梯子:https://www.youtube.com/embed/LIT8zOhnIxs),从图中很明显可以看出,不是所有的landmark都是有用的,可以从中提取关键点,做了一下统计后,发现共有115个landmark被用于手、姿势和嘴唇。
这里再贴一下对手部特征点做的可视化:

以及总的543个特征点的分布:
FRAME_TYPE_IDX_MAP = {
"face" : np.arange(0, 468),
"left_hand" : np.arange(468, 489),
"pose" : np.arange(489, 522),
"right_hand" : np.arange(522, 543),
}
叙述完特征点,最终还得需要提交结果,这次比赛提交的是一个tflite的模型,它支持的转换格式如下:
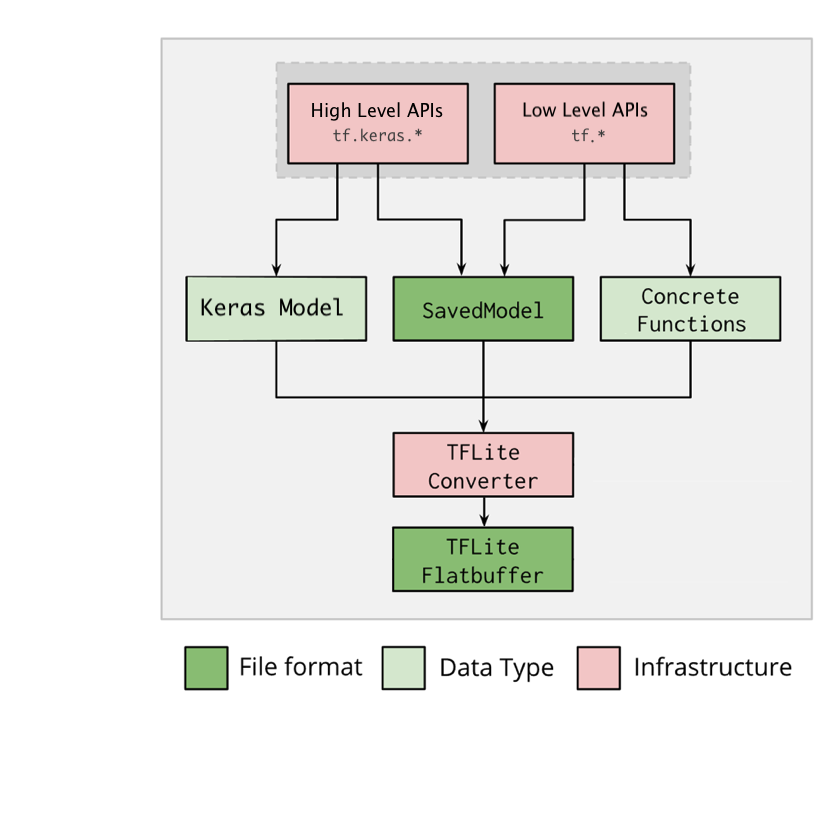
当然,比赛前期就有人尝试用pytorch来转成tflite,但是这种相对会麻烦些,我看到discussion是有的,只不过有些限制,比如说torch的 GRU单元在这里就用不了,transformer却是可以,所以蛙佬的方案中是torch模型转onnx,再将onnx转tflite,这种理论上比tensorflow多一层,会有所精度损失,但在实践下来后发现也没啥问题。
数据分析
上述的介绍是针对parquet 格式文件,还有一个meta csv为这些的汇总,字段说明为:
- path - The path to the landmark file.
- participant_id - A unique identifier for the data contributor.
- sequence_id - A unique identifier for the landmark sequence.
- sign - The label for the landmark sequence.
格式为:
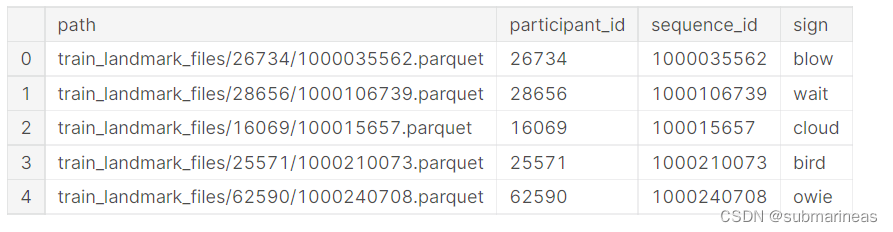
那我们便可以针对该数据进行分析,比如说查看participant_id 字段的一些分布情况:
print("\n... BASICS OF THE PARTICIPANT ID COLUMN:\n")
display(train_df["participant_id"].astype(str).describe().to_frame().T)
print("\n... WE GET THE COUNT MAP AND GET BASIC STATISTICS:")
participant_count_map = train_df["participant_id"].value_counts().to_dict()
print("\t1. Number of Unique Participants -->", len(participant_count_map))
print("\t2. Average Number of Rows Per Participant -->", np.array(list(participant_count_map.values())).mean())
print("\t3. Standard Deviation in Counts Per Participant -->", np.array(list(participant_count_map.values())).std())
print("\t4. Minimum Number of Examples For One Participant -->", np.array(list(participant_count_map.values())).min())
print("\t5. Maximum Number of Examples For One Participant -->", np.array(list(participant_count_map.values())).max())
print("\n... GOING FORWARD WE SET THIS COLUMN TO BE A STRING")
train_df["participant_id"] = train_df["participant_id"].astype(str)
subsample_train_df["participant_id"] = subsample_train_df["participant_id"].astype(str)
打印结果为:
count unique top freq
participant_id 94477 21 49445 4968
... WE GET THE COUNT MAP AND GET BASIC STATISTICS:
1. Number of Unique Participants --> 21
2. Average Number of Rows Per Participant --> 4498.9047619047615
3. Standard Deviation in Counts Per Participant --> 490.7731417304649
4. Minimum Number of Examples For One Participant --> 3338
5. Maximum Number of Examples For One Participant --> 4968
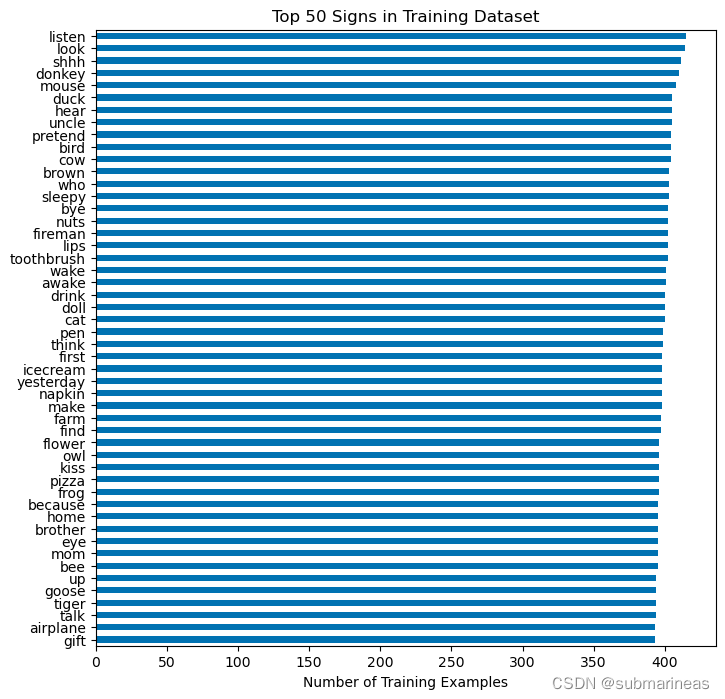
以及可以查看top 50的sign:
fig, ax = plt.subplots(figsize=(8, 8))
train["sign"].value_counts().head(50).sort_values(ascending=True).plot(
kind="barh", ax=ax, title="Top 50 Signs in Training Dataset"
)
ax.set_xlabel("Number of Training Examples")
plt.show()
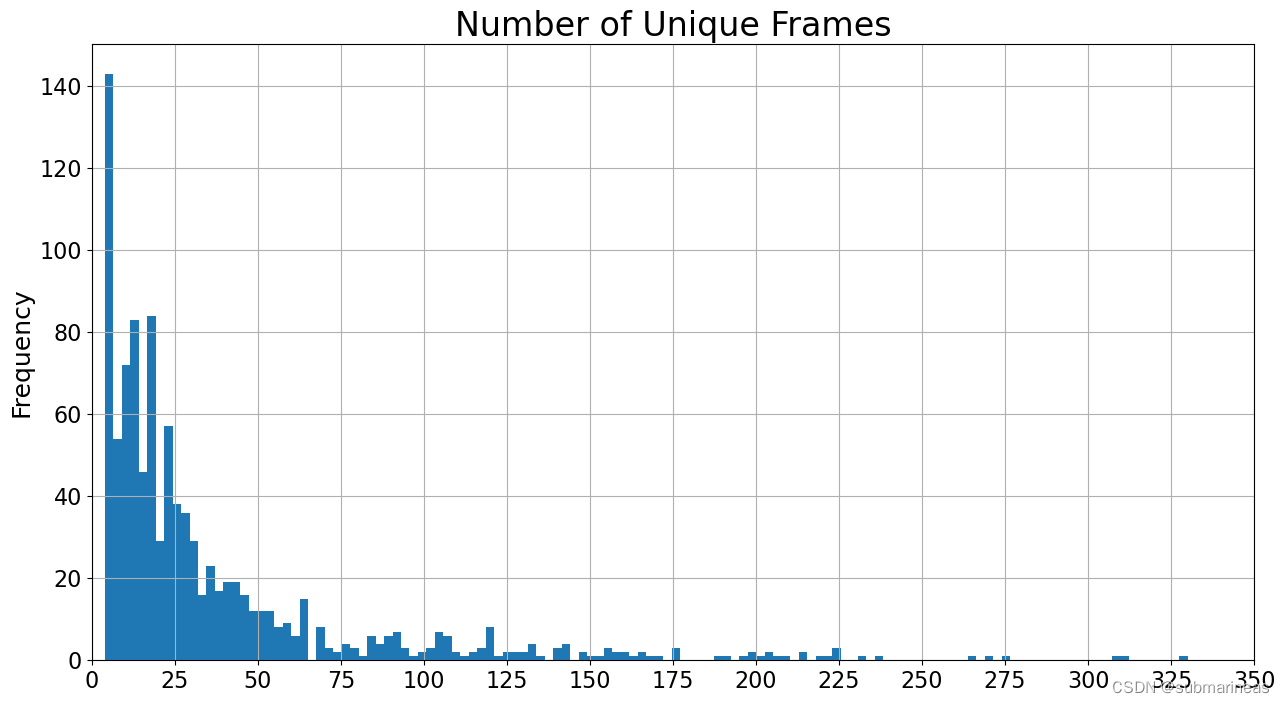
以及统计视频数据集中每个视频的缺失帧数以及不同帧数:
N = int(1e3) if (IS_INTERACTIVE or not PREPROCESS_DATA) else int(10e3) # 根据条件设置 N 的值
N_UNIQUE_FRAMES = np.zeros(N, dtype=np.uint16) # 初始化 N_UNIQUE_FRAMES 数组
N_MISSING_FRAMES = np.zeros(N, dtype=np.uint16) # 初始化 N_MISSING_FRAMES 数组
MAX_FRAME = np.zeros(N, dtype=np.uint16) # 初始化 MAX_FRAME 数组
PERCENTILES = [0.01, 0.05, 0.25, 0.50, 0.75, 0.95, 0.99, 0.999] # 定义 PERCENTILES 列表
for idx, file_path in enumerate(tqdm(train['file_path'].sample(N, random_state=SEED))): # 遍历 train['file_path'] 中的文件路径
df = pd.read_parquet(file_path) # 读取文件
N_UNIQUE_FRAMES[idx] = df['frame'].nunique() # 计算每个文件中不同帧的数量
N_MISSING_FRAMES[idx] = (df['frame'].max() - df['frame'].min()) - df['frame'].nunique() + 1 # 计算每个文件中缺失帧的数量
MAX_FRAME[idx] = df['frame'].max() # 计算每个文件中最大帧数
# Number of unique frames in each video
display(pd.Series(N_UNIQUE_FRAMES).describe(percentiles=PERCENTILES).to_frame('N_UNIQUE_FRAMES'))
plt.figure(figsize=(15,8))
plt.title('Number of Unique Frames', size=24)
pd.Series(N_UNIQUE_FRAMES).plot(kind='hist', bins=128)
plt.grid()
xlim = math.ceil(plt.xlim()[1])
plt.xlim(0, xlim)
plt.xticks(np.arange(0, xlim+25, 25))
plt.show()
"""
N_UNIQUE_FRAMES
count 1000.000000
mean 37.676000
std 46.188184
min 4.000000
1% 6.000000
5% 6.000000
25% 11.000000
50% 21.000000
75% 43.000000
95% 139.050000
99% 224.000000
99.9% 312.018000
max 330.000000
"""
baseline
Landmark Indices 关键点索引
在机器学习中,Landmark Indices通常指的是人脸关键点的索引。人脸关键点是人脸上的一些特定点,例如眼睛、鼻子、嘴巴等,它们可以用于人脸识别、表情识别等任务。在机器学习中,我们可以使用这些关键点来训练模型,从而实现人脸识别等任务。
# 定义三种数据类型:左手、姿态和右手
USE_TYPES = ['left_hand', 'pose', 'right_hand']
# 定义原始数据中的起始索引
START_IDX = 468
# 定义原始数据中的嘴唇关键点索引,共40个
LIPS_IDXS0 = np.array([
61, 185, 40, 39, 37, 0, 267, 269, 270, 409,
291, 146, 91, 181, 84, 17, 314, 405, 321, 375,
78, 191, 80, 81, 82, 13, 312, 311, 310, 415,
95, 88, 178, 87, 14, 317, 402, 318, 324, 308,
])
# 定义原始数据中的左手关键点索引,共21个
LEFT_HAND_IDXS0 = np.arange(468,489)
# 定义原始数据中的右手关键点索引,共21个
RIGHT_HAND_IDXS0 = np.arange(522,543)
# 定义原始数据中的左侧姿态关键点索引,共5个
LEFT_POSE_IDXS0 = np.array([502, 504, 506, 508, 510])
# 定义原始数据中的右侧姿态关键点索引,共5个
RIGHT_POSE_IDXS0 = np.array([503, 505, 507, 509, 511])
# 定义左手优先的关键点索引,包括嘴唇、左手和左侧姿态,共66个
LANDMARK_IDXS_LEFT_DOMINANT0 = np.concatenate((LIPS_IDXS0, LEFT_HAND_IDXS0, LEFT_POSE_IDXS0))
# 定义右手优先的关键点索引,包括嘴唇、右手和右侧姿态,共66个
LANDMARK_IDXS_RIGHT_DOMINANT0 = np.concatenate((LIPS_IDXS0, RIGHT_HAND_IDXS0, RIGHT_POSE_IDXS0))
# 定义所有手部关键点索引,包括左手和右手,共42个
HAND_IDXS0 = np.concatenate((LEFT_HAND_IDXS0, RIGHT_HAND_IDXS0), axis=0)
# 定义处理后数据的列数,等于66
N_COLS = LANDMARK_IDXS_LEFT_DOMINANT0.size
# 定义处理后数据中的嘴唇关键点索引,从0到39
LIPS_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, LIPS_IDXS0)).squeeze()
# 定义处理后数据中的左手关键点索引,从40到60
LEFT_HAND_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, LEFT_HAND_IDXS0)).squeeze()
# 定义处理后数据中的右手关键点索引,从40到60
RIGHT_HAND_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, RIGHT_HAND_IDXS0)).squeeze()
# 定义处理后数据中的所有手部关键点索引,从40到81
HAND_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, HAND_IDXS0)).squeeze()
# 定义处理后数据中的姿态关键点索引,从61到65
POSE_IDXS = np.argwhere(np.isin(LANDMARK_IDXS_LEFT_DOMINANT0, LEFT_POSE_IDXS0)).squeeze()
# 打印出手部关键点索引的长度和处理后数据的列数
print(f'# HAND_IDXS: {len(HAND_IDXS)}, N_COLS: {N_COLS}')
#这段代码是用于定义处理后数据中不同部位的关键点的起始位置,以便于后续的切片或索引操作
# 定义嘴唇关键点的起始位置,为0
LIPS_START = 0
# 定义左手关键点的起始位置,为嘴唇关键点的数量
LEFT_HAND_START = LIPS_IDXS.size
# 定义右手关键点的起始位置,为左手关键点的起始位置加上左手关键点的数量
RIGHT_HAND_START = LEFT_HAND_START + LEFT_HAND_IDXS.size
# 定义姿态关键点的起始位置,为右手关键点的起始位置加上右手关键点的数量
POSE_START = RIGHT_HAND_START + RIGHT_HAND_IDXS.size
# 打印出不同部位的关键点的起始位置
print(f'LIPS_START: {LIPS_START}, LEFT_HAND_START: {LEFT_HAND_START}, RIGHT_HAND_START: {RIGHT_HAND_START}, POSE_START: {POSE_START}')
"""
HAND_IDXS: 21, N_COLS: 66
LIPS_START: 0, LEFT_HAND_START: 40, RIGHT_HAND_START: 61, POSE_START: 61
"""
Process Data Tensorflow
ROWS_PER_FRAME = 543 # number of landmarks per frame每帧的标记数量
#`load_relevant_data_subset 加载相关数据子集
#提取数据集中的x、y、z三列数据,将数据集按照每帧的地标数量进行切分,返回一个三维数组。
#其中第一维表示帧数,第二维表示每帧的地标数量,第三维表示x、y、z三个坐标轴。
def load_relevant_data_subset(pq_path):
data_columns = ['x', 'y', 'z']
data = pd.read_parquet(pq_path, columns=data_columns)
n_frames = int(len(data) / ROWS_PER_FRAME)
data = data.values.reshape(n_frames, ROWS_PER_FRAME, len(data_columns))
return data.astype(np.float32)
这段代码定义了一个名为ROWS_PER_FRAME的常量,它的值为543,表示每帧的地标数量。函数load_relevant_data_subset(pq_path)读取指定路径下的parquet文件,提取数据集中的x、y、z三列数据,将数据集按照每帧的地标数量进行切分,返回一个三维数组。其中第一维表示帧数,第二维表示每帧的地标数量,第三维表示x、y、z三个坐标轴。函数返回值类型为numpy.ndarray,数据类型为np.float32。
自定义一个使用TF的数据预处理层
首先,该层在 _init_ 方法中创建了一个名为 normalisation_correction 的常量。该常量是一个矩阵,其行数等于数据中特定类型的标志点的数量,列数是 3(即 x、y 和 z 坐标)。这个矩阵用于校正相机的拍摄方向,将左手调整为右手,右手调整为左手。
该层还定义了一个名为 pad_edge 的方法,用于在给定张量的左侧或右侧填充一定数量的重复元素。接下来,该层使用 @tf.function 装饰器装饰了一个 _call_ 方法,用于处理输入数据。
该方法首先计算了输入数据的帧数(N_FRAMES0),然后通过计算左右手各自在数据中的坐标之和,找到了数据中支配性手的标志点。接下来,该方法计算了每个帧的支配性手中非 NaN 值的数量,以确定哪些帧需要保留。然后,它使用这些索引从输入数据中收集标志点数据。
该方法接下来将帧索引的数据类型从整数转换为浮点数,然后将其规范化为以 0 开始。接下来,它再次计算了经过筛选的数据的帧数(N_FRAMES),然后从这些数据中收集了特定类型的标志点数据。如果数据的帧数小于指定的输入大小(INPUT_SIZE),则使用 -1 进行填充,将数据的帧数扩展到指定的输入大小,并将 NaN 值替换为 0。如果数据的帧数大于指定的输入大小,则使用重复数据将其缩小到指定的输入大小,并填充任何缺失的数据。
最后,该方法返回经过处理的数据和相应的帧索引。
"""
Tensorflow layer to process data in TFLite
Data needs to be processed in the model itself, so we can not use Python
"""
class PreprocessLayer(tf.keras.layers.Layer):
def __init__(self):
super(PreprocessLayer, self).__init__()
normalisation_correction = tf.constant([
# Add 0.50 to left hand (original right hand) and substract 0.50 of right hand (original left hand)
[0] * len(LIPS_IDXS) + [0.50] * len(LEFT_HAND_IDXS) + [0.50] * len(POSE_IDXS),
# Y coordinates stay intact
[0] * len(LANDMARK_IDXS_LEFT_DOMINANT0),
# Z coordinates stay intact
[0] * len(LANDMARK_IDXS_LEFT_DOMINANT0),
],
dtype=tf.float32,
)
self.normalisation_correction = tf.transpose(normalisation_correction, [1,0])
def pad_edge(self, t, repeats, side):
if side == 'LEFT':
return tf.concat((tf.repeat(t[:1], repeats=repeats, axis=0), t), axis=0)
elif side == 'RIGHT':
return tf.concat((t, tf.repeat(t[-1:], repeats=repeats, axis=0)), axis=0)
@tf.function(
input_signature=(tf.TensorSpec(shape=[None,N_ROWS,N_DIMS], dtype=tf.float32),),
)
def call(self, data0):
# Number of Frames in Video
N_FRAMES0 = tf.shape(data0)[0]
# Find dominant hand by comparing summed absolute coordinates
left_hand_sum = tf.math.reduce_sum(tf.where(tf.math.is_nan(tf.gather(data0, LEFT_HAND_IDXS0, axis=1)), 0, 1))
right_hand_sum = tf.math.reduce_sum(tf.where(tf.math.is_nan(tf.gather(data0, RIGHT_HAND_IDXS0, axis=1)), 0, 1))
left_dominant = left_hand_sum >= right_hand_sum
# Count non NaN Hand values in each frame for the dominant hand
if left_dominant:
frames_hands_non_nan_sum = tf.math.reduce_sum(
tf.where(tf.math.is_nan(tf.gather(data0, LEFT_HAND_IDXS0, axis=1)), 0, 1),
axis=[1, 2],
)
else:
frames_hands_non_nan_sum = tf.math.reduce_sum(
tf.where(tf.math.is_nan(tf.gather(data0, RIGHT_HAND_IDXS0, axis=1)), 0, 1),
axis=[1, 2],
)
# Find frames indices with coordinates of dominant hand
non_empty_frames_idxs = tf.where(frames_hands_non_nan_sum > 0)
non_empty_frames_idxs = tf.squeeze(non_empty_frames_idxs, axis=1)
# Filter frames
data = tf.gather(data0, non_empty_frames_idxs, axis=0)
# Cast Indices in float32 to be compatible with Tensorflow Lite
non_empty_frames_idxs = tf.cast(non_empty_frames_idxs, tf.float32)
# Normalize to start with 0
non_empty_frames_idxs -= tf.reduce_min(non_empty_frames_idxs)
# Number of Frames in Filtered Video
N_FRAMES = tf.shape(data)[0]
# Gather Relevant Landmark Columns
if left_dominant:
data = tf.gather(data, LANDMARK_IDXS_LEFT_DOMINANT0, axis=1)
else:
data = tf.gather(data, LANDMARK_IDXS_RIGHT_DOMINANT0, axis=1)
data = (
self.normalisation_correction + (
(data - self.normalisation_correction) * tf.where(self.normalisation_correction != 0, -1.0, 1.0))
)
# Video fits in INPUT_SIZE
if N_FRAMES < INPUT_SIZE:
# Pad With -1 to indicate padding
non_empty_frames_idxs = tf.pad(non_empty_frames_idxs, [[0, INPUT_SIZE-N_FRAMES]], constant_values=-1)
# Pad Data With Zeros
data = tf.pad(data, [[0, INPUT_SIZE-N_FRAMES], [0,0], [0,0]], constant_values=0)
# Fill NaN Values With 0
data = tf.where(tf.math.is_nan(data), 0.0, data)
return data, non_empty_frames_idxs
# Video needs to be downsampled to INPUT_SIZE
else:
# Repeat
if N_FRAMES < INPUT_SIZE**2:
repeats = tf.math.floordiv(INPUT_SIZE * INPUT_SIZE, N_FRAMES0)
data = tf.repeat(data, repeats=repeats, axis=0)
non_empty_frames_idxs = tf.repeat(non_empty_frames_idxs, repeats=repeats, axis=0)
# Pad To Multiple Of Input Size
pool_size = tf.math.floordiv(len(data), INPUT_SIZE)
if tf.math.mod(len(data), INPUT_SIZE) > 0:
pool_size += 1
if pool_size == 1:
pad_size = (pool_size * INPUT_SIZE) - len(data)
else:
pad_size = (pool_size * INPUT_SIZE) % len(data)
# Pad Start/End with Start/End value
pad_left = tf.math.floordiv(pad_size, 2) + tf.math.floordiv(INPUT_SIZE, 2)
pad_right = tf.math.floordiv(pad_size, 2) + tf.math.floordiv(INPUT_SIZE, 2)
if tf.math.mod(pad_size, 2) > 0:
pad_right += 1
# Pad By Concatenating Left/Right Edge Values
data = self.pad_edge(data, pad_left, 'LEFT')
data = self.pad_edge(data, pad_right, 'RIGHT')
# Pad Non Empty Frame Indices
non_empty_frames_idxs = self.pad_edge(non_empty_frames_idxs, pad_left, 'LEFT')
non_empty_frames_idxs = self.pad_edge(non_empty_frames_idxs, pad_right, 'RIGHT')
# Reshape to Mean Pool
data = tf.reshape(data, [INPUT_SIZE, -1, N_COLS, N_DIMS])
non_empty_frames_idxs = tf.reshape(non_empty_frames_idxs, [INPUT_SIZE, -1])
# Mean Pool
data = tf.experimental.numpy.nanmean(data, axis=1)
non_empty_frames_idxs = tf.experimental.numpy.nanmean(non_empty_frames_idxs, axis=1)
# Fill NaN Values With 0
data = tf.where(tf.math.is_nan(data), 0.0, data)
return data, non_empty_frames_idxs
preprocess_layer = PreprocessLayer()
这段代码是一个 TensorFlow Keras 自定义层,命名为 PreprocessLayer。它用于对输入数据进行预处理,包括对手部关键点数据进行处理、填充和归一化等操作。
该层的主要功能包括:
初始化操作:在 __init__ 方法中,通过调用父类 tf.keras.layers.Layer 的 __init__ 方法进行初始化,并定义了一个名为 normalisation_correction 的常量张量,并将其转置存储在 self.normalisation_correction 中。
pad_edge 方法:用于在输入数据的边缘填充数据,根据指定的填充方向(‘LEFT’ 或 ‘RIGHT’)和填充的重复次数。
call 方法:通过使用 @tf.function 装饰器,定义了一个计算图(Graph)的操作,用于对输入数据进行处理。具体步骤如下:
-
获取输入数据的第一个维度(帧数)并存储在 N_FRAMES0 变量中。
-
判断左手或右手哪只手是主导手,并根据主导手的结果,计算每一帧中手部关键点非 NaN(非空)值的和,并存储在
left_hand_sum和right_hand_sum中。 -
根据主导手的结果,计算每一帧中主导手的手部关键点非 NaN(非空)值的和,并存储在
frames_hands_non_nan_sum中。 -
根据
frames_hands_non_nan_sum中的结果,找到非空帧的索引,并存储在non_empty_frames_idxs中。 -
根据
non_empty_frames_idxs过滤输入数据,并进行一系列归一化和填充操作,最终返回处理后的数据和填充后的帧索引。
总体而言,PreprocessLayer 自定义层主要用于对输入数据进行预处理,包括对手部关键点数据的处理、填充和归一化等操作,以满足后续模型的输入要求。
Interpolate NaN Values(插值)
Interpolate NaN Values是指使用插值法填充数据中的NaN值。NaN是计算机科学中数值数据类型的一类值,表示未定义或不可表示的值。NaN是Not a Number的缩写,理解为不是一个数值。在计算机中,NaN通常用于表示无效的或未定义的操作结果,如0/0、∞-∞等1。
"""
face: 0:468
left_hand: 468:489
pose: 489:522
right_hand: 522:544
从file_path get data
第一行代码调用了load_relevant_data_subset函数,从文件路径中加载原始数据。
第二行代码调用了preprocess_layer函数,该函数使用Tensorflow处理数据。
最后返回处理后的数据。
"""
def get_data(file_path):
# Load Raw Data
data = load_relevant_data_subset(file_path)
# Process Data Using Tensorflow
data = preprocess_layer(data)
return data
MultiHeadAttention
Need to implement transformer from scratch as TFLite does not support the native TF implementation of MultiHeadAttention.由于TFLite(TensorFlow Lite,一种针对移动和嵌入式设备进行优化的TensorFlow版本)不支持TensorFlow原生的MultiHeadAttention层实现,因此需要从头开始实现Transformer模型(一种在自然语言处理任务中使用的神经网络架构),其中包括MultiHeadAttention层。由于MultiHeadAttention层是Transformer模型的关键组成部分,因此如果TFLite不支持其实现,则可能无法在TFLite中使用TensorFlow中预先存在的Transformer实现。因此,需要自己编写Transformer的实现代码,而不依赖于TensorFlow中的MultiHeadAttention层的实现。
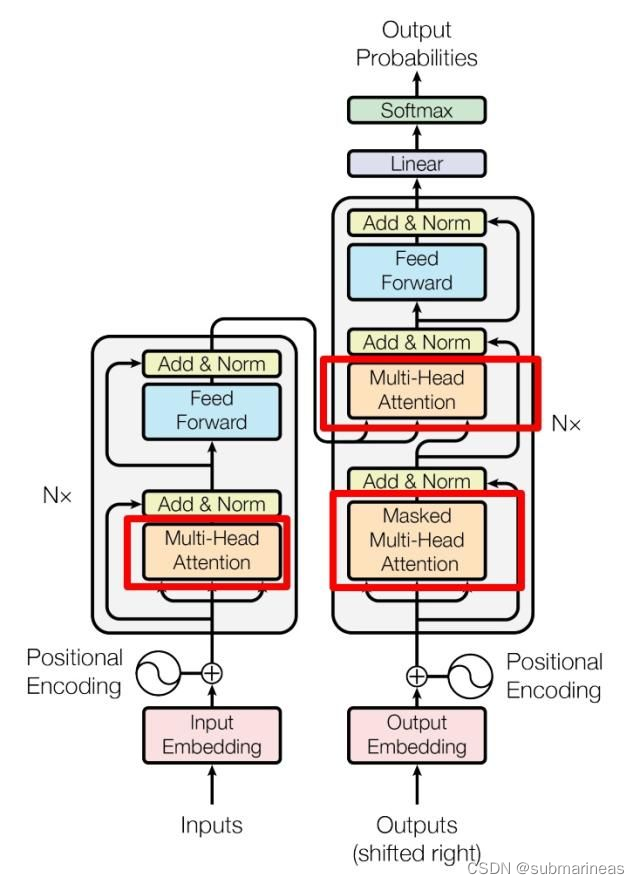
其中:
- Encoder:输入是单词的Embedding,再加上位置编码,然后进入一个统一的结构,这个结构可以循环很多次(N次),也就是说有很多层(N层)。每一层又可以分成Attention层和全连接层,再额外加了一些处理,比如Skip Connection,做跳跃连接,然后还加了Normalization层。其实它本身的模型还是很简单的。
- Decoder:第一次输入是前缀信息,之后的就是上一次产出的Embedding,加入位置编码,然后进入一个可以重复很多次的模块。该模块可以分成三块来看,第一块也是Attention层,第二块是cross Attention,不是Self-Attention,第三块是全连接层。也用了跳跃连接和Normalization。 输出:最后的输出要通过Linear层(全连接层),再通过softmax做预测。
Encoder部分是N个相同结构的堆叠,每个结构中又可以细分为如下结构:
- 对输入 one-hot 编码的样本进行 embedding(词嵌入)
- 加入位置编码
- 引入多头机制的 Self-Attention
- 将 self-attention 的输入和输出相加(残差网络结构)
- Layer Normalization(层标准化),对所有时刻的数据进行标准化
- 前馈型神经网络(Feedforword)结构
- 将 Feedforword 的输入和输出相加(残差网络结构)
- Layer Normalization,对所有时刻的数据进行标准化
- 重复N层3-8的结构
Decoder部分同样也是N个相同结构的堆叠,每个结构中又可以细分为如下结构:
- 对输入 one-hot 编码的样本进行 embedding(词嵌入)
- 加入位置编码
- 引入多头机制的 Self-Attention
- 将 self-attention 的输入和输出相加(残差网络结构)
- Layer Normalization(层标准化)
- 对所有时刻的数据进行标准化将上一步得到的只作为value,并和编码器端得到 q和k进行Self-Attenton
- 将 self-attention 的输入和输出相加(残差网络结构)
- Layer Normalization(层标准化),对所有时刻的数据进行标准化
- 前馈型神经网络(Feedforword) 结构
- 将 Feedforword 的输入和输出相加(残差网络结构)
- Layer Normalization,对所有时刻的数据进行标准化
- 重复N层3-11的结构
#scaled dot-product attention是Transformer模型中的一种Attention机制,它是一种计算Attention权重的方法。
#在这种方法中,Query和Key的点积被除以一个缩放因子,然后通过softmax函数进行归一化处理,最后与Value相乘得到Attention输出
def scaled_dot_product(q,k,v, softmax, attention_mask):
#calculates Q . K(transpose)
qkt = tf.matmul(q,k,transpose_b=True)
#caculates scaling factor
dk = tf.math.sqrt(tf.cast(q.shape[-1],dtype=tf.float32))
scaled_qkt = qkt/dk
softmax = softmax(scaled_qkt, mask=attention_mask)
z = tf.matmul(softmax,v)
#shape: (m,Tx,depth), same shape as q,k,v
return z
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self,d_model,num_of_heads):
super(MultiHeadAttention,self).__init__()
self.d_model = d_model
self.num_of_heads = num_of_heads
self.depth = d_model//num_of_heads
self.wq = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wk = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wv = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)]
self.wo = tf.keras.layers.Dense(d_model)
self.softmax = tf.keras.layers.Softmax()
def call(self,x, attention_mask):
multi_attn = []
for i in range(self.num_of_heads):
Q = self.wq[i](x)
K = self.wk[i](x)
V = self.wv[i](x)
multi_attn.append(scaled_dot_product(Q,K,V, self.softmax, attention_mask))
multi_head = tf.concat(multi_attn,axis=-1)
multi_head_attention = self.wo(multi_head)
return multi_head_attention
这段代码是一个MultiHeadAttention的实现。它将输入张量x分别通过多个Dense层进行线性变换,然后将变换后的张量分别作为Q,K,V传入scaled_dot_product函数中,计算出多头注意力机制的输出。最后将多头注意力机制的输出拼接起来,再通过一个Dense层进行线性变换,得到最终的输出multi_head_attention。scaled_dot_product函数是计算Q.K^T的函数,其中Q,K,V分别为query,key,value矩阵,attention_mask是用于掩码的张量。softmax函数是用于计算softmax值的函数。
transformer
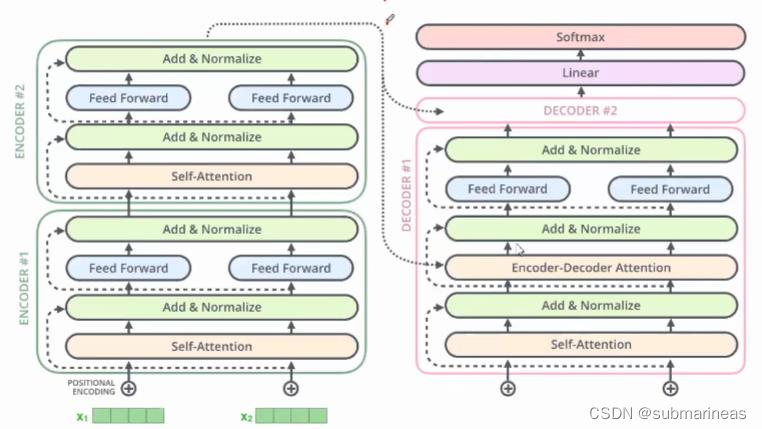
# Full Transformer
class Transformer(tf.keras.Model):
def __init__(self, num_blocks):
super(Transformer, self).__init__(name='transformer')
self.num_blocks = num_blocks
def build(self, input_shape):
self.ln_1s = []
self.mhas = []
self.ln_2s = []
self.mlps = []
# Make Transformer Blocks
for i in range(self.num_blocks):
# Multi Head Attention
self.mhas.append(MultiHeadAttention(UNITS, 8))
# Multi Layer Perception
self.mlps.append(tf.keras.Sequential([
tf.keras.layers.Dense(UNITS * MLP_RATIO, activation=GELU, kernel_initializer=INIT_GLOROT_UNIFORM),
tf.keras.layers.Dropout(MLP_DROPOUT_RATIO),
tf.keras.layers.Dense(UNITS, kernel_initializer=INIT_HE_UNIFORM),
]))
def call(self, x, attention_mask):
# Iterate input over transformer blocks
for mha, mlp in zip(self.mhas, self.mlps):
x = x + mha(x, attention_mask)
x = x + mlp(x)
return x
Landmark Embedding
关键点嵌入,其中"Landmark"表示人脸的关键点,"Embedding"表示将这些关键点信息映射到低维向量空间的过程。因此,“Landmark Embedding"的中文意思可以理解为"将人脸关键点信息嵌入到低维向量空间中”。
Landmark Embedding是一种将人脸关键点信息转换为低维向量表示的方法。在人脸识别和人脸表情识别等任务中,Landmark Embedding通常用于提取人脸特征表示。
具体来说,Landmark Embedding通过对人脸图像中的关键点坐标进行处理,将其映射到一个低维空间中的向量表示。这个向量表示可以包含关于人脸形状、姿态和表情等信息,可以用于比较不同人脸之间的相似性或差异性。相比于直接使用像素信息或高维特征向量表示,Landmark Embedding可以提高人脸识别和表情识别的准确度和鲁棒性。
class LandmarkEmbedding(tf.keras.Model):
def __init__(self, units, name):
super(LandmarkEmbedding, self).__init__(name=f'{name}_embedding')
self.units = units
def build(self, input_shape):
# Embedding for missing landmark in frame, initizlied with zeros
self.empty_embedding = self.add_weight(
name=f'{self.name}_empty_embedding',
shape=[self.units],
initializer=INIT_ZEROS,
)
# Embedding
self.dense = tf.keras.Sequential([
tf.keras.layers.Dense(self.units, name=f'{self.name}_dense_1', use_bias=False, kernel_initializer=INIT_GLOROT_UNIFORM),
tf.keras.layers.Activation(GELU),
tf.keras.layers.Dense(self.units, name=f'{self.name}_dense_2', use_bias=False, kernel_initializer=INIT_HE_UNIFORM),
], name=f'{self.name}_dense')
def call(self, x):
return tf.where(
# Checks whether landmark is missing in frame
tf.reduce_sum(x, axis=2, keepdims=True) == 0,
# If so, the empty embedding is used
self.empty_embedding,
# Otherwise the landmark data is embedded
self.dense(x),
)
train后
train这里回归了常规操作,没上面做特征工程以及建模那么需要业务,还是三板斧,就不再展示代码,这里直接贴出一些训练后的参数可视化,首先可视化一下整个模型构建:
tf.keras.utils.plot_model(model, show_shapes=True, show_dtype=True, show_layer_names=True, expand_nested=True, show_layer_activations=True)

以及学习率,我这里是以60 epochs算的:
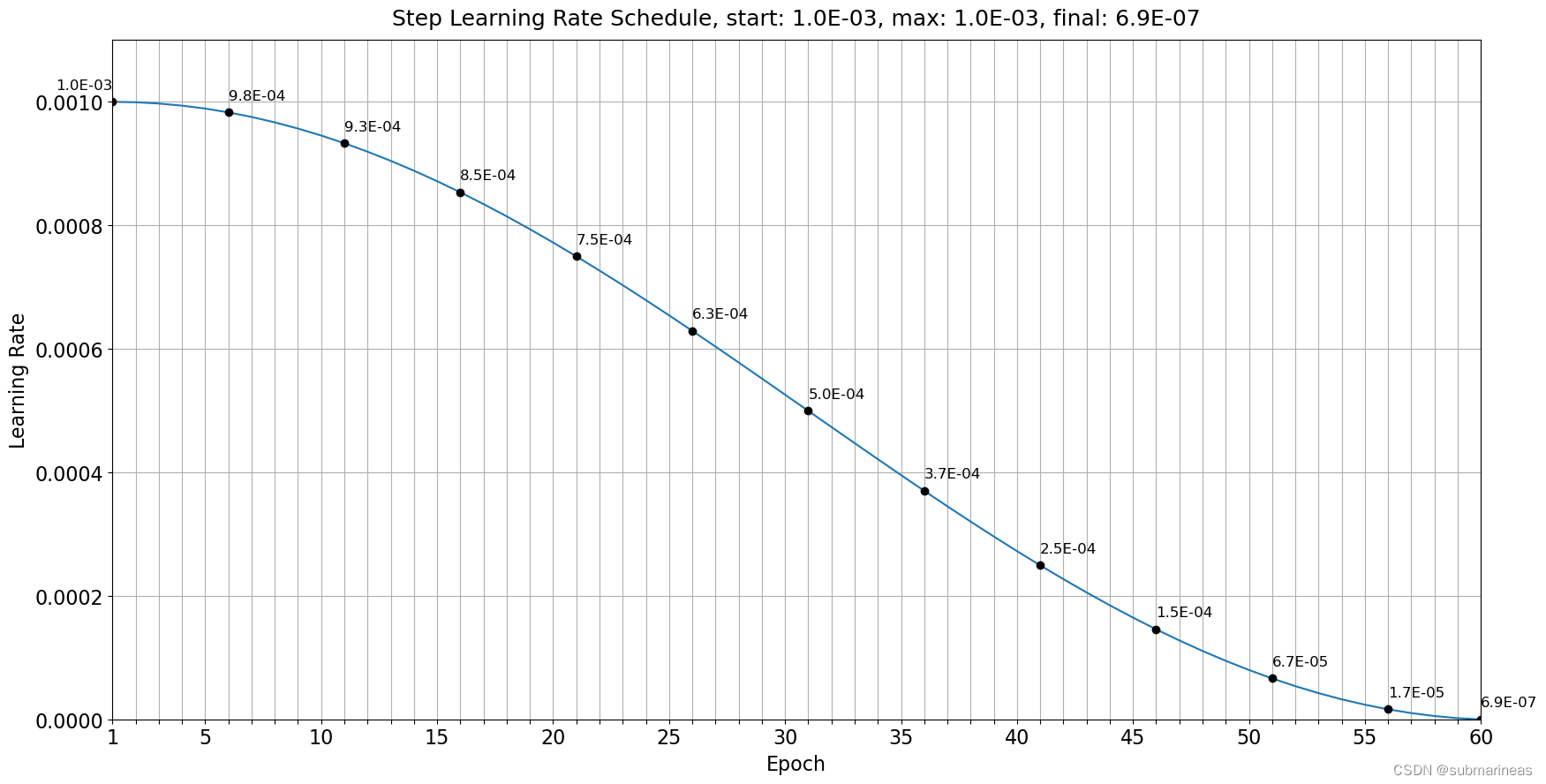
以及画出训练曲线图:
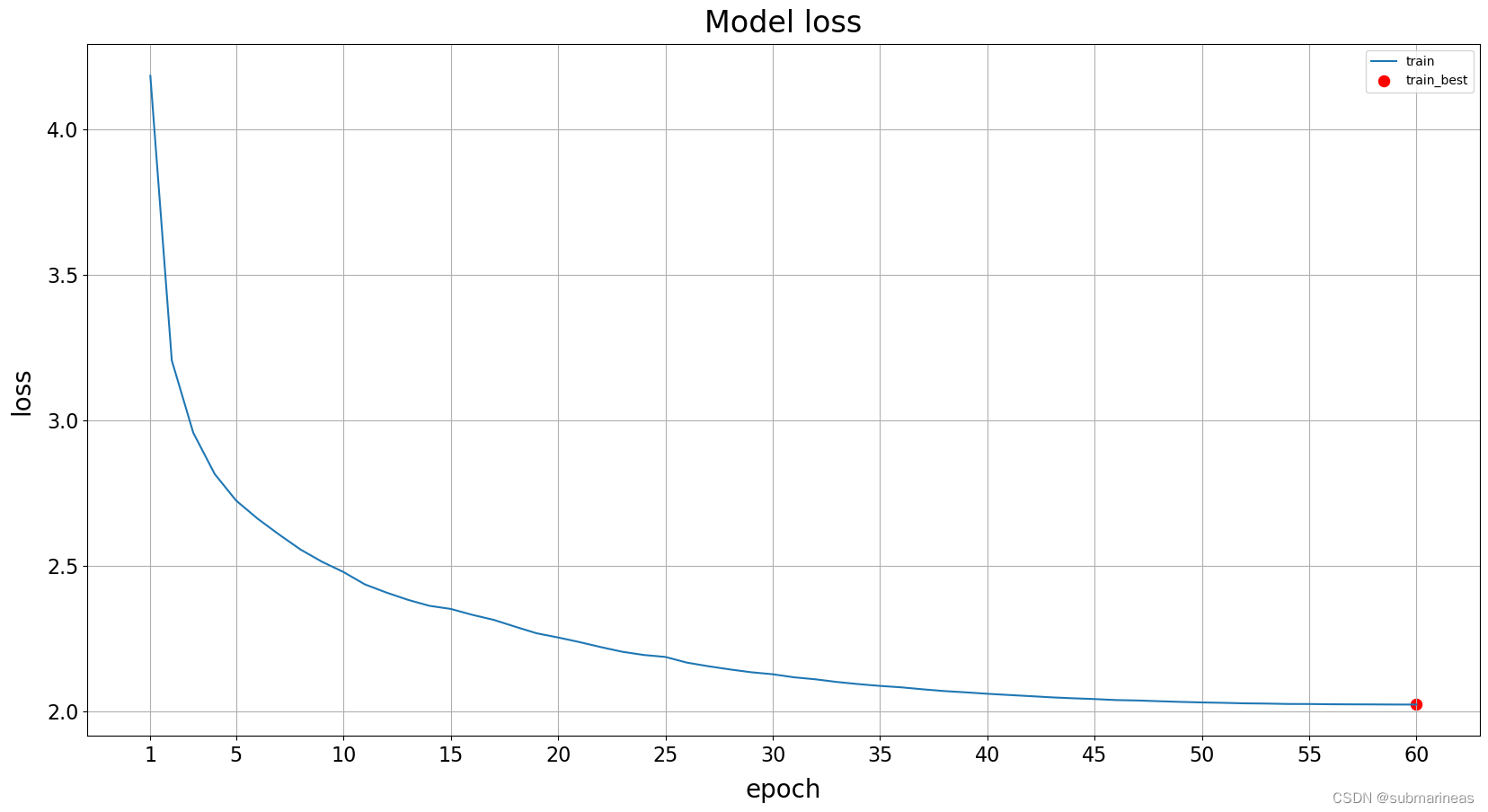
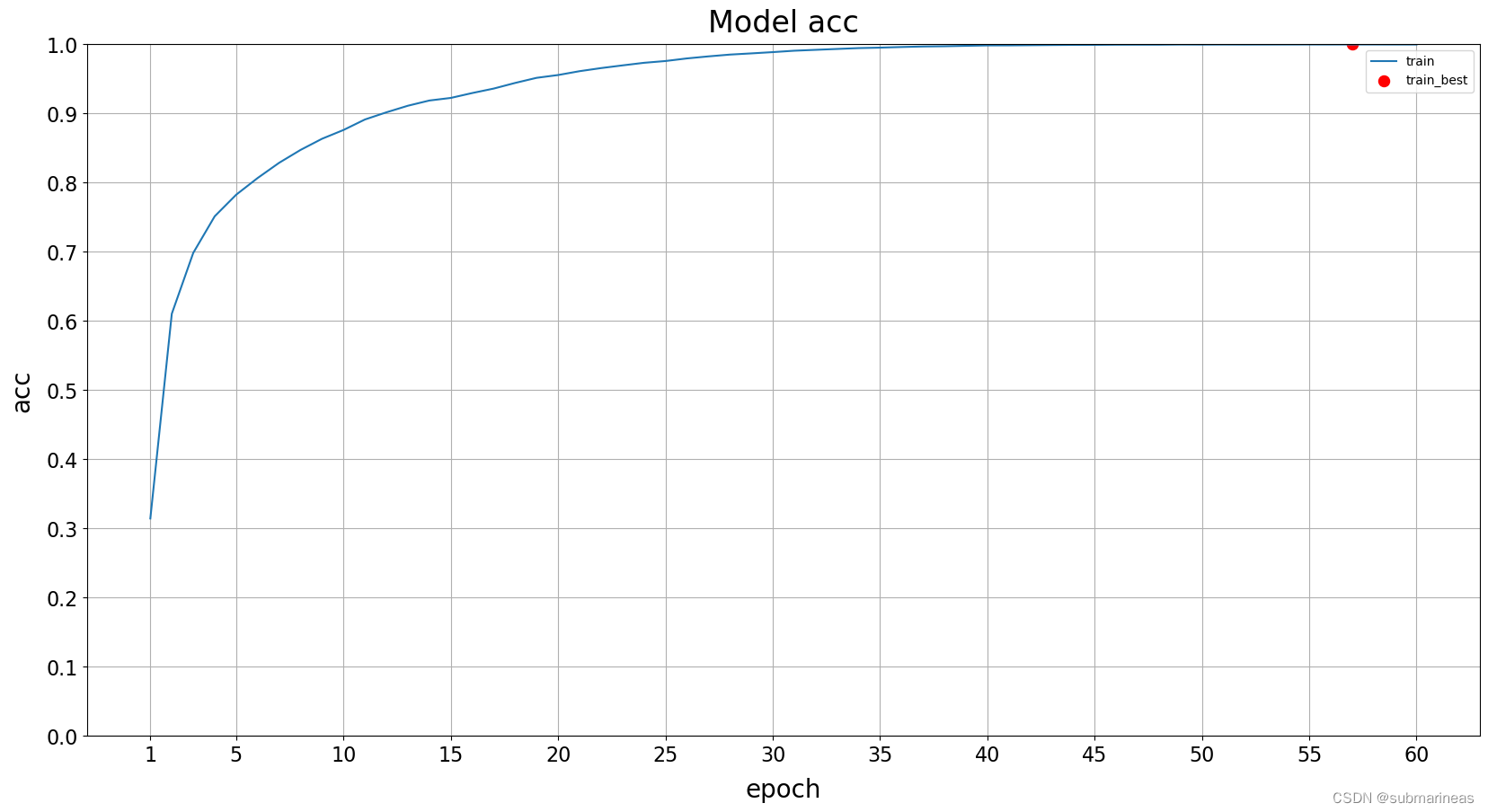
最后,给大家表演一个后空翻
ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ
( ̄▽ ̄) ~*( ̄▽ ̄)/
公开的各种trick
因为前面感觉篇幅过长,而且前排方案很多冗余了,这里就大致举几个我觉得对我很有启发的,不会跟之前那篇rsna一样介绍得那么详细,毕竟也不会真有人说照着我这个trick复现。那肯定看更详细的notebook了。
44th方案
为啥介绍44th,是因为该方案就是完全照着我上面的best public来的,它主要修改的地方在于:
- Train 1 model => Train 4 models
- Add Time Scale augmentation
- Ensemble and apply TFLite FP16 quantization
- Change the following parameters:
- INPUT_SIZE, 64 => 12
- BATCH_ALL_SIGNS_N, 4 => 1
- N_EPOCHS, 250 => 120
- LANDMARK_UNITS, 384 => 224
- UNITS, 512 => 376
- NUM_BLOCKS, 2 => 3
- MLP_RATIO, 4 => 3
- MLP_DROPOUT_RATIO, 0.40 => 0.30
- remove random frame masking
哎,除了前两个我没想到外,其它基本都想到了,不过就是搞错了方向,它这开始250 epochs跑过来,差不多90就已经接近acc为0了,即使是去做数据增强,以及一些batch_size的改变,我感觉过拟合严重,外加4 fold,那更是跑得离谱,但事实上手势没有那么多过拟合,毕竟看下面的1th就知道了。
1th方案
1th方案对当前transformer和1d CNN做了一下探讨,就是用一维的cnn去训练模型,结果效果要比单纯transformer的更好,加上一些cnn的策略,比如说AWP等等,我现在发现也好理解,其实手势这东西虽然可以考虑三维,但是本质上就是点和线,可以看成一维的。那CNN跑得又快,当然可能会效果好些,但最终的方案还是在CNN后加入了transformer,这里作者的解释是一维 CNN 模型采用深度卷积和因果填充。transformer使用 BatchNorm + Swish 代替典型的 LayerNorm + GELU,这是微调后的结果,那CNN的代码为:
def get_model(max_len=64, dropout_step=0, dim=192):
inp = tf.keras.Input((max_len,CHANNELS))
x = tf.keras.layers.Masking(mask_value=PAD,input_shape=(max_len,CHANNELS))(inp)
ksize = 17
x = tf.keras.layers.Dense(dim, use_bias=False,name='stem_conv')(x)
x = tf.keras.layers.BatchNormalization(momentum=0.95,name='stem_bn')(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
if dim == 384: #for the 4x sized model
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
x = tf.keras.layers.Dense(dim*2,activation=None,name='top_conv')(x)
x = tf.keras.layers.GlobalAveragePooling1D()(x)
x = LateDropout(0.8, start_step=dropout_step)(x)
x = tf.keras.layers.Dense(NUM_CLASSES,name='classifier')(x)
return tf.keras.Model(inp, x)
4th方案
到这里,其实前排方案基本最终都是以 1D CNN为主,第四方案还画了个流程图,我觉得挺强的:
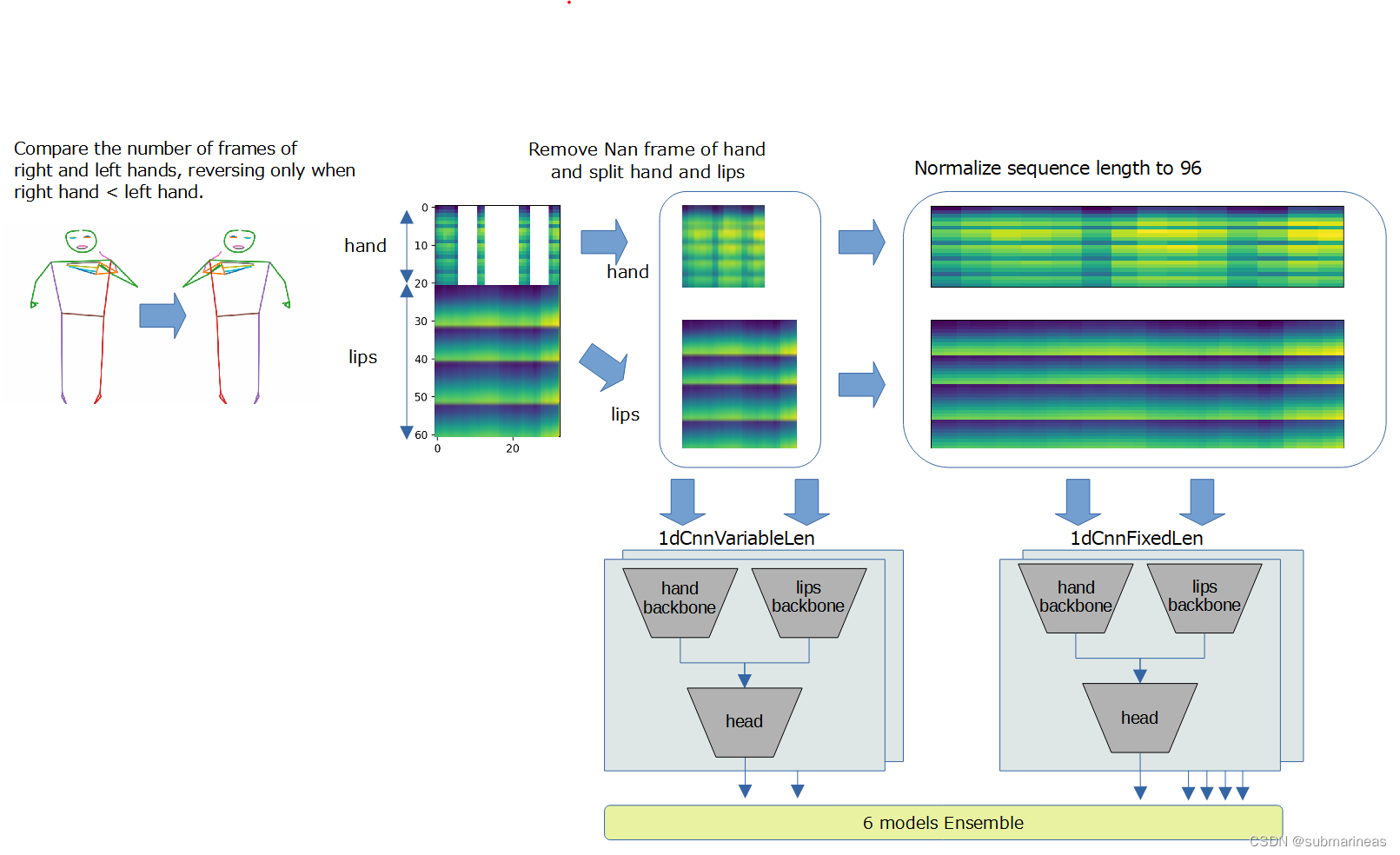
那其它就不再介绍了,这次比赛真的也还是挺遗憾的,希望之后有个好结果。















 5982
5982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











