




引言
也许很多人还在为租房而困扰,因为每当打开第三方app,都会被各式各样的房东或者是中介看得蒙蔽了双眼,我曾经也看过很多篇文章叙说在大城市租房的血泪史,很多人都有那么几次,就像找吃的,找用的,甚至是找另一半,经历过后才有更多经验面临下一次。最近正好在实验楼看到了一个租房教程,自我实验了一下很不错,结合另外的一个开源项目,在这里一起整理成博文分享一下。
页面分析与爬取信息
本篇爬取的网站是位于58同城的一个内部公寓网,我们首先需要分析页面才能得到一个具体的结果,我们可以从该网页中获取到相关的信息,分析的网页如下:
https://sz.58.com/pinpaigongyu/
然后我们可以看到该网站有挂出的租房信息:
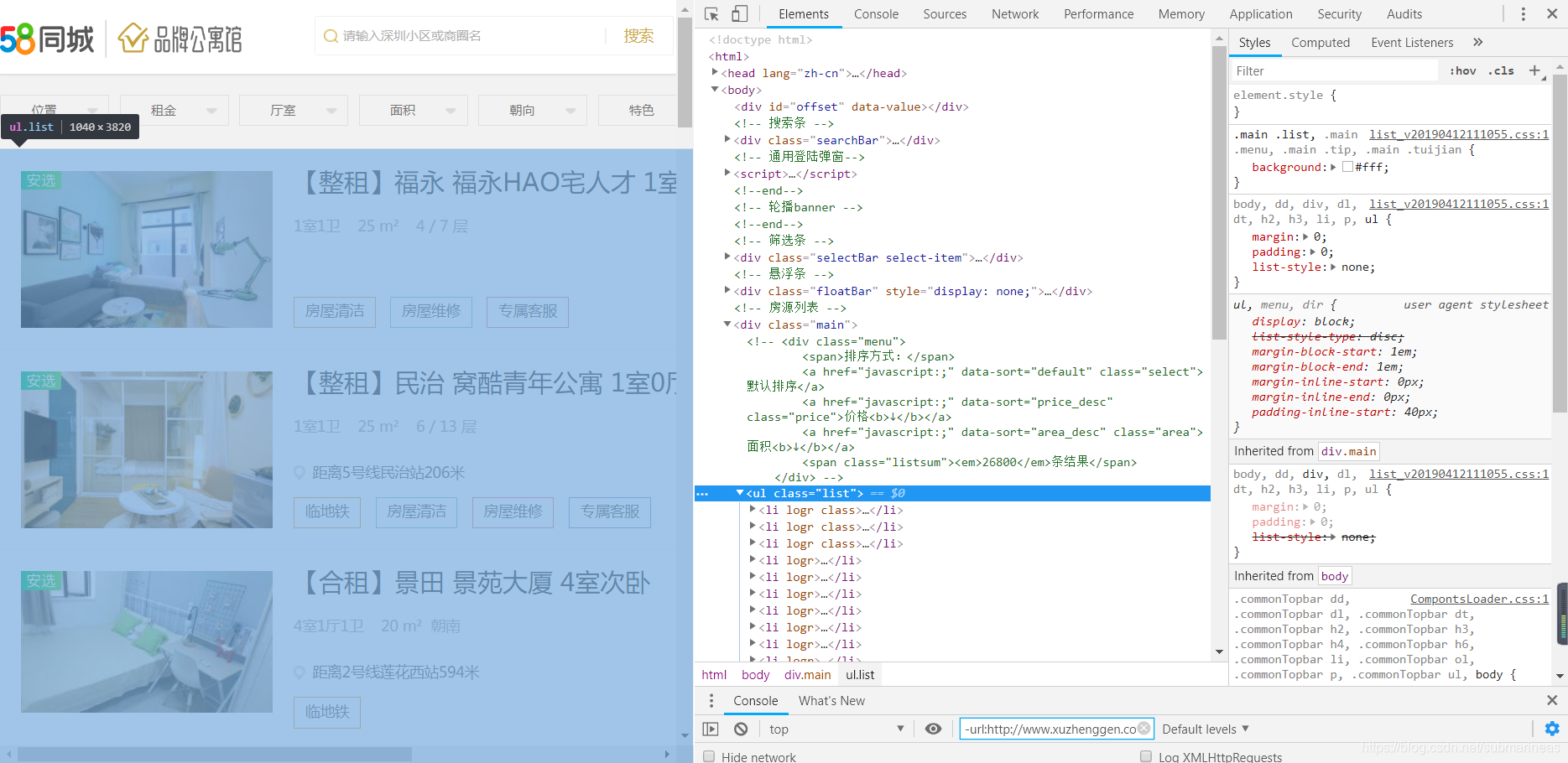
我们发现所有的租房信息都是一个li标签,并且都位于ul标签下,当我们往下移的时候,相应的标签也会越来越多,所以我们便可以利用有无list类来判定是否为租房请求。当然,这是在没有任何条件获取到的全部信息,但很多信息我们是不会看的,既然有租房的意愿,那么我们就有一个大致的心理承受价格,因此我们可以来分析一下该网站的url构造形式,为:
/pingpaigongyu/pn/{
page}/minprice={
min_rent}_{
max_rent}
我这里的心理承受范围是2000——4000,因为有考虑和别人合租,假如一个人的话就是2000以内了,所以加上这段url后,租房信息发生了改变:
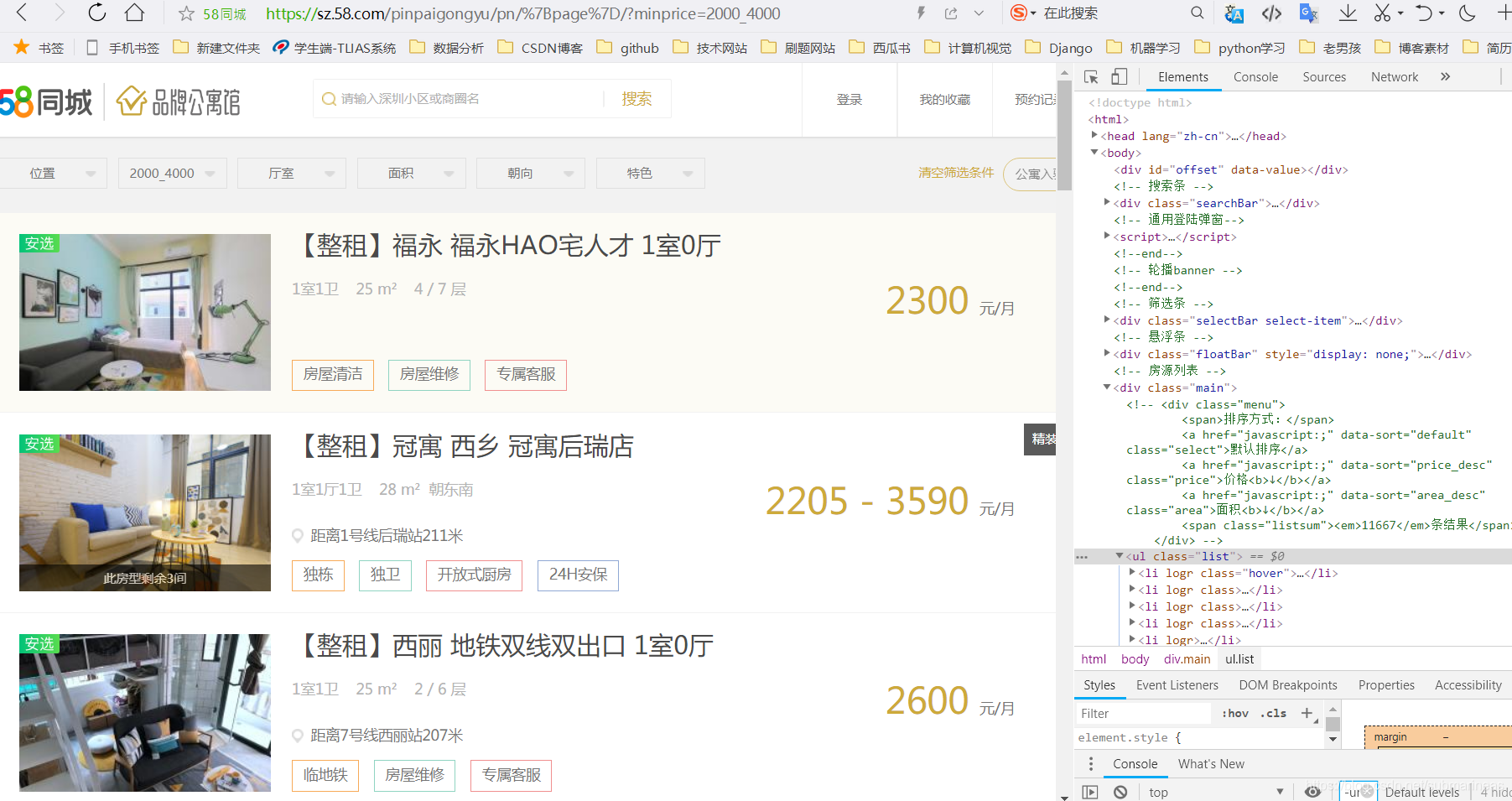
然后我们可以看到需要的信息为房子的位置与价格,就是上图中的:

点进去后还可以查看相关的经纬度,以及其它的各类信息:
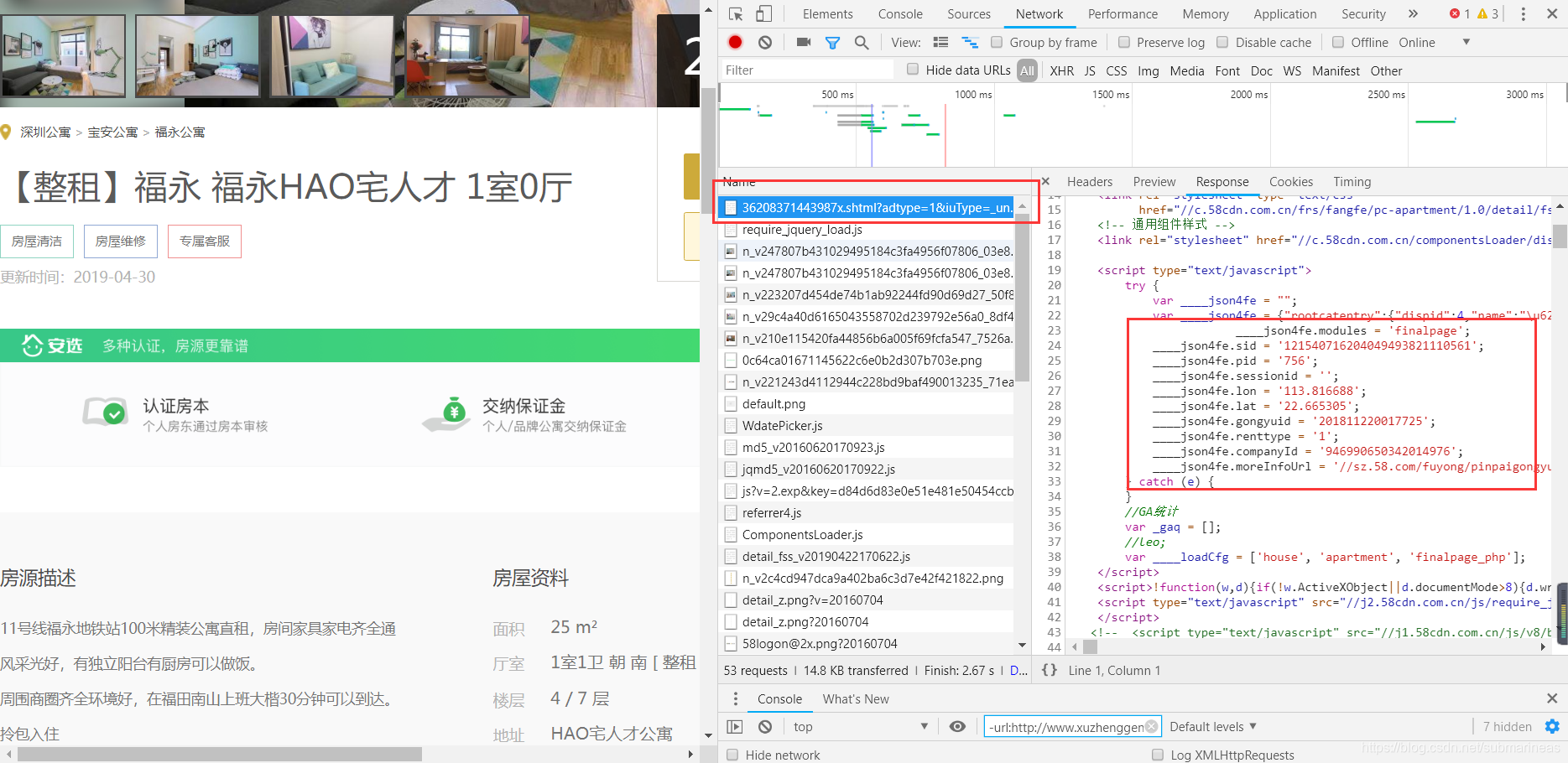
这些信息有些是经过了加密,并不一定准确,然后我们就可以根据以上信息来写一个小的爬虫程序:
from bs4 import BeautifulSoup
import requests
import csv
import time
import lxml
url = "https://sz.58.com/pinpaigongyu/pn/{page}/?minprice=2000_4000"
#已完成的页数序号,初时为0
page = 0
csv_file = open("rent.csv","w")
csv_writer = csv.writer(csv_file, delimiter=',')
while True:
page += 1
print("fetch: ", url.format(page=page))
time.sleep(1)
response = requests.get(url.format(page=page))
html = BeautifulSoup(response.text,features="lxml")
house_list = html.select(".list > li")
# 循环在读不到新的房源时结束
if not house_list:
break
for house in house_list:
house_title = house.select("h2")[0].string
house_url = house.select("a")[0]["href"]
house_info_list = house_title.split()
# 如果第二列是公寓名则取第一列作为地址
if "公寓" in house_info_list[1] or "青年社区" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string
csv_writer.writerow([house_title, house_location, house_money, house_url])
csv_file.close()
这里用了requests+beautifulsoup+csv来进行对爬取的数据进行存储,其实也可以xpath,看熟悉哪个用哪个就行,另外关于beautifulsoup美丽汤的用法,我最近很多篇博客都是用的它,之前应该也有介绍过,这里就不再提了。
然后这里就会有一个小bug,更准确的来说,其实是58同城这个网址的反爬措施,当我们爬取了一页到两页的数据后,可能并没有爬取到任何数据,程序运行就结束了。这种情况发生时,一般就要考虑是否代码有问题,或者对方的反爬策略了,果不其然,我们在PC端再一次进入租房网:
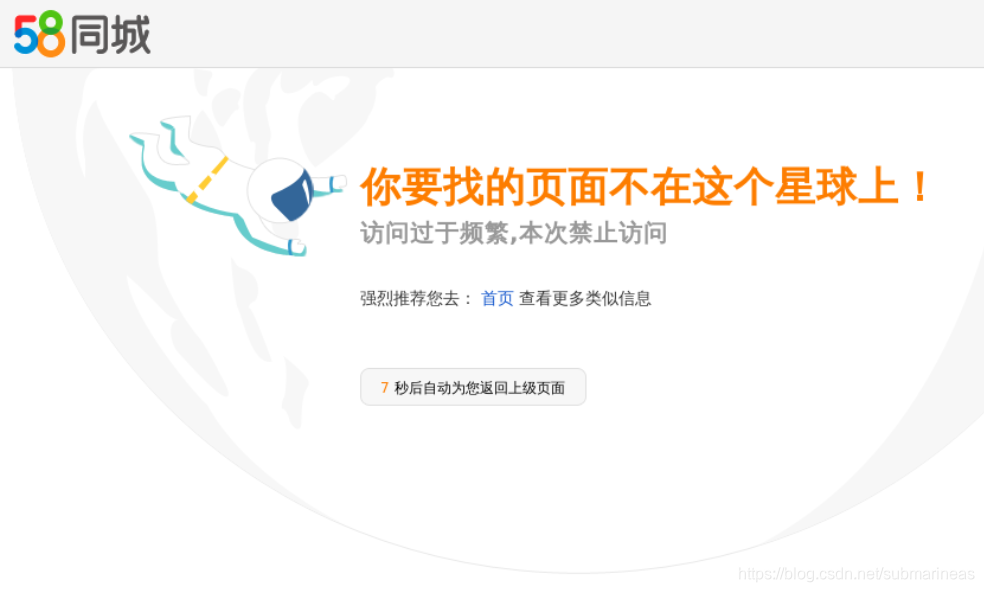
显示如上页面说明,对方的反爬措施将我们识别成了爬虫,那么我们就需要通过上级页面再重新进入该页面验证,验证这就是我的手速:
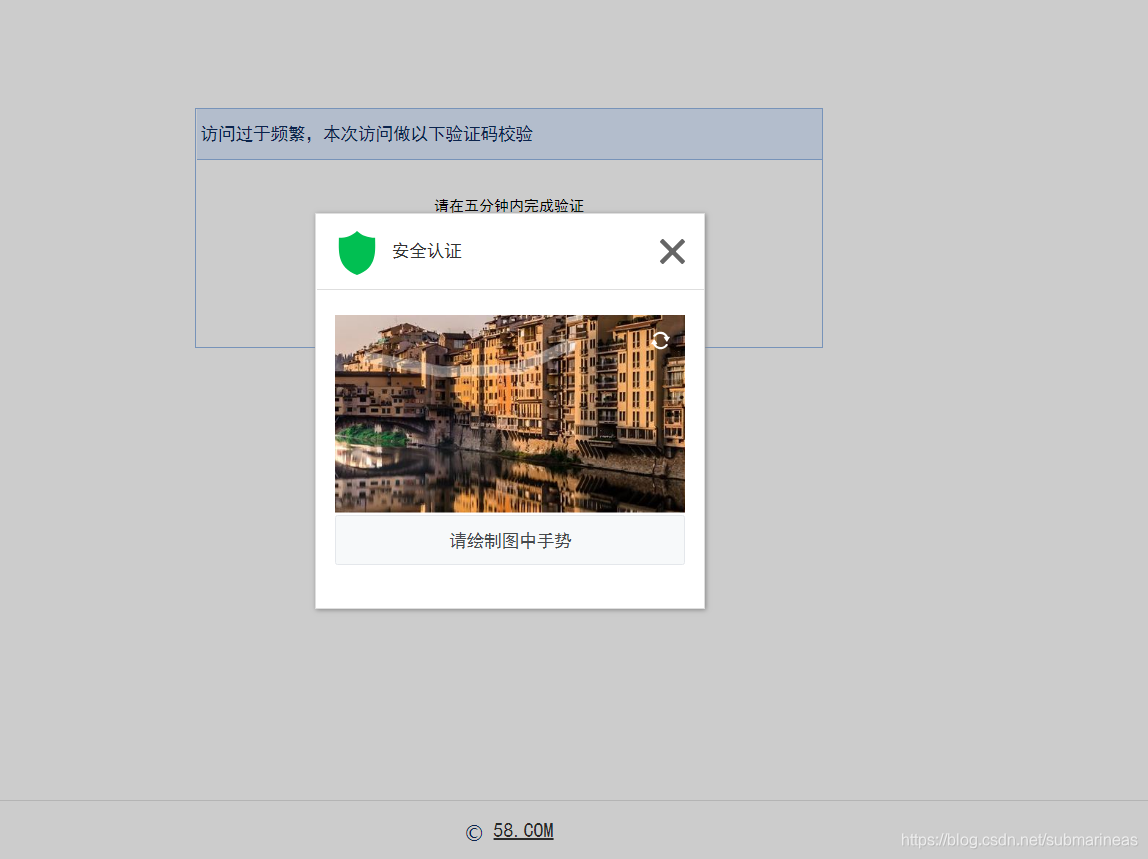
验证成功后,我们就可以无止境的爬咯,大概是两分钟左右,170多页的数据,然后生成了相应的csv文件,但当我们打开来时,却是有乱码的情况,这里就要分情况讨论了。
由于时间还有效率原因,这份代码我是在windows上跑的,根据windows的编码格式,出现乱码我需要定义成gb18030才能进行正确显示,即上面的代码我会改这一句:
csv_file = open("rent.csv","w",encoding="gb18030")
然后除了数字,其它所有信息都能正常显示:
但建议还是utf-8,因为后面前端的代码是适配utf8的,所以在windows下,文件格式乱码,并不影响程序对其的读取,gb18030编码会导致后面调用高德api的租房信息无法导入。
前端显示
<html>
<head>
<meta charset="utf-8" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











