







引言
上一节重点介绍了gstreamer架构图与各部分组成原理说明,并且针对deepstream-test1介绍了它的整体功能和画出了管道图,本篇博文将详细介绍deepstream-imagedata-multistream与接入适配yolov5模型测试。
deepstream插件简单介绍
DeepStream 以 GStreamer 插件的形式提供构建块,可用于构建高效的视频分析管道。有超过 20 个插件为各种任务进行了硬件加速,核心 SDK 由几个硬件加速器插件组成,这些插件使用 VIC、GPU、DLA、NVDEC 和 NVENC 等加速器。它本身构建就是由多插件构成,而这些插件在官方文档中,有部分开源插件也能在源码中看到,可以通过GitHub进行查阅,但作为一般使用者而言,它已经将插件配置实例化,即写成了一个个配置参数,我们需要改的,也仅仅是deepstream-app下面的config配置文件,如下表所示:
| 组 | 配置组 |
|---|---|
| Application Group | 与指定组件无关的配置 |
| Tiled-display Group | 平铺显示 |
| Source Group | 源配置。多个源时,命名:[source0] ,[source1] .... |
| Streammux Group | streammux(混流)组件的配置和更改,sui |
| Primary GIE | streammux(混流)组件的配置和更改,俗称 |
| Tracker Group | GIE推理引擎的相关配置 |
| OSD Group | 次级推理引擎的相关配置。多个次级推理命名:[secondary-gie0] , [secondary-gie1] ,... |
| Sink Group | 目标跟组的相关配置 |
| Tests Group | 组件相关配置。包括每一帧上显示的文本和矩形框 |
| Preprocess Group | 预处理 |
针对这些配置文件,sdk中创建了相应deepstream-test1到test5的例程进行测试,如下图:

当然本篇博客并不讲test1到test5,因为我看到很多人都讲了test1源码,我感觉基本差不多了,本篇博文只是大致说明功能与代码,第一是很多东西其实不看源码不了解根本讲不了,最多也是去官方文档复制理解sdk原话,第二就是它的很多测试参数我调试不多,如果对C有一定了解和感冒,建议是直接看C的代码会比较顺畅,因为有些配置在python里其实是没有的,都被定义默认值了,或者写进代码里不如txt直观,而C全部丢在config配置文件夹下,比如说source30_1080p_dec_infer-resnet_tiled_display_int8.txt,或者其它配置文件,上述表格中所有的配置参数都有涉及,这里有人对deepstream官方配置参数进行了翻译,为:deepstream配置文件解析 ,英文原版链接如下:NVIDIA DeepStream SDK Developer Guide
说回重点,博客主要以python为主进行阐述,虽然说C的版本我也调试了很久,但感觉上还是差点,C的deepstream-app的测试历程实在是太长了,不得不说相比于python,C的那一千来行代码外加配置文件,详细的功能调用与边界条件,本身调试成功就能直接上生产了,我也只是小修了一些参数,大部分时间都在更改source_xxx.txt文件配置并成功调通。python的会麻烦些,它的测试用例比较简单,如果要根据自己的意愿来进行,还是需要修改代码的,这里以deepstream-imagedata-multistream为例,首先列举出我之后适配yolov5的配置文件以及一些我的注释:
[property]
# 配置插件的一般行为,这是唯一的强制(必须有的)组
gpu-id=0
#net-scale-factor=0.0039215697906911373 # 图像归一化参数
net-scale-factor=1
model-color-format=1 # #0=RGB, 1=BGR
# custom-network-config=yolov5s.cfg
# model-file=/home/test/yolov5/yolov5s.weights
#model-engine-file=model_b1_gpu0_fp32.engine
model-engine-file=model_trt.engine # 加载engine模型路径
#int8-calib-file=calib.table
labelfile-path=labels.txt # labels模型类别文件,该参数未读取
batch-size=2 # 输入模型图像批次
network-mode=0 # 网络运行精度设置,0为FP32,1为int8
num-detected-classes=10 # 模型检测类别个数
interval=0 # 增加主检测器推断输入帧的间隔,即推理间隔,1为每隔一帧推断一次,2为每三帧推理一次
gie-unique-id=1 # 检测器等级?默认为1,当成主检测器
process-mode=1 # NvOSD processing mode. 0: CPU 1: GPU (dGPU only) 2: Hardware (Jetson only)
network-type=0 # 细分网络?
cluster-mode=1 # ## 0=Group Rectangles, 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
maintain-aspect-ratio=1 # 表示resize过程是否保存输入宽高比
parse-bbox-func-name=NvDsInferParseCustomYolox # bbox解析入口函数
custom-lib-path=/opt/nvidia/deepstream/deepstream-5.1/sources/apps/sample_apps/yolox_deepstream-main/nvdsinfer_custom_impl_yolox/libnvdsinfer_custom_impl_yolox.so # bbox解析链接共享库
engine-create-func-name=NvDsInferYoloCudaEngineGet # 生成当前进程入口函数
[class-attrs-all] # 所有类配置检测参数
pre-cluster-threshold=0.2
eps=0.7
minBoxes=1
#Use the config params below for dbscan clustering mode
[class-attrs-all] # 所有类配置检测参数
detected-min-w=4
detected-min-h=4
minBoxes=3
## Per class configurations
[class-attrs-0] # (class-attrs-int),指定的类配置检测参数
pre-cluster-threshold=0.05
eps=0.7
dbscan-min-score=0.95
[class-attrs-1]
pre-cluster-threshold=0.05
eps=0.7
dbscan-min-score=0.5
[class-attrs-2]
pre-cluster-threshold=0.1
eps=0.6
dbscan-min-score=0.95
[class-attrs-3]
pre-cluster-threshold=0.05
eps=0.7
dbscan-min-score=0.5
就像注释写得那样,property是python唯一必要的组,其它的比如说osd,sources组等都写成了默认参数,这里想重点介绍下的是deepstream的数据传输方式,因为这也算deepstream接入的核心。具体的与它里面的方法可以看下图:

上述图出现了5种Meta数据,黄框代表对象名,方框里的是此对象的方法,黑体的名字如freame_meta_list、user_meta_list 等等的,都是存储了图像数据保存的buffer,相当于使用了python中的迭代器,经过l_frame.next可以取出,具体的在下一节具体案例讲,这里只做介绍,但实际上目前deepstream 6.1版本后,并非还是只有这几个对象,上图也很老了,从源码调用上可以看到(筛选了后缀为info和Meta的类):
from .NvDsAnalyticsFrameMeta import NvDsAnalyticsFrameMeta
from .NvDsAnalyticsObjInfo import NvDsAnalyticsObjInfo
from .NvDsBaseMeta import NvDsBaseMeta
from .NvDsBatchMeta import NvDsBatchMeta
from .NvDsClassifierMeta import NvDsClassifierMeta
from .NvDsComp_BboxInfo import NvDsComp_BboxInfo
from .NvDsDisplayMeta import NvDsDisplayMeta
from .NvDsEventMsgMeta import NvDsEventMsgMeta
from .NvDsFrameMeta import NvDsFrameMeta
from .NvDsInferLayerInfo import NvDsInferLayerInfo
from .NvDsInferNetworkInfo import NvDsInferNetworkInfo
from .NvDsInferObjectDetectionInfo import NvDsInferObjectDetectionInfo
from .NvDsInferSegmentationMeta import NvDsInferSegmentationMeta
from .NvDsInferTensorMeta import NvDsInferTensorMeta
from .NvDsMeta import NvDsMeta
from .NvDsObjectMeta import NvDsObjectMeta
from .NvDsOpticalFlowMeta import NvDsOpticalFlowMeta
from .NvDsUserMeta import NvDsUserMeta
以NvDsEventMsgMeta举例,这个应该是6.1才出现的对象,nvidia官网并没有对这个类的解释,但是直接help能看到它已经全写在注释里了,顺便总结了它所使用方式的模板:
$ from pyds import NvDsEventMsgMeta
$ help(NvDsEventMsgMeta)
"""
Holds event message meta data. You can attach various types of objects (vehicle, person, face, etc.) to an event by setting a pointer to the object in :py:attr:`extMsg`.
Similarly, you can attach a custom object to an event by setting a pointer to the object in :py:attr:`extMsg`.
A custom object must be handled by the metadata parsing module accordingly.
:ivar type: :class:`NvDsEventType`, Type of event.
:ivar objType: :class:`NvDsObjectType`, Type of object.
:ivar bbox: :class:`NvDsRect`, Bounding box of object.
:ivar location: :class:`NvDsGeoLocation`, Geo-location of object.
:ivar coordinate: :class:`NvDsCoordinate`, Coordinate of object.
:ivar objSignature: :class:`NvDsObjectSignature`, Signature of object.
:ivar objClassId: *int*, Class id of object.
:ivar sensorId: *int*, ID of sensor that generated the event.
:ivar moduleId: *int*, ID of analytics module that generated the event.
:ivar placeId: *int*, ID of place related to the object.
:ivar componentId: *int*, ID of component that generated this event.
:ivar frameId: *int*, Video frame ID of this event.
:ivar confidence: *int*, Confidence level of the inference.
:ivar trackingId: *int*, Tracking ID of object.
:ivar ts: *str*, Time stamp of generated event.
:ivar objectId: *str*, ID of detected / inferred object.
:ivar sensorStr: *str*, Identity string of sensor.
:ivar otherAttrs: *str*, Other attributes associated with the object.
:ivar videoPath: *str*, Name of video file.
:ivar extMsg: Object to extend the event message meta data. This can be used for custom values that can't be accommodated in the existing fields
OR if object(vehicle, person, face etc.) Specific values must be attached.
:ivar extMsgSize: *int*, Size of the custom object at extMsg.
Example usage:
::
def generate_event_msg_meta(data, class_id):
meta =pyds.NvDsEventMsgMeta.cast(data)
meta.sensorId = 0
meta.placeId = 0
meta.moduleId = 0
meta.sensorStr = "sensor-0"
meta.ts = pyds.alloc_buffer(MAX_TIME_STAMP_LEN + 1)
pyds.generate_ts_rfc3339(meta.ts, MAX_TIME_STAMP_LEN) #Generate timestamp
# This demonstrates how to attach custom objects.
# Any custom object as per requirement can be generated and attached
# like NvDsVehicleObject / NvDsPersonObject. Then that object should
# be handled in payload generator library (nvmsgconv.cpp) accordingly.
if(class_id==PGIE_CLASS_ID_VEHICLE):
meta.type = pyds.NvDsEventType.NVDS_EVENT_MOVING
meta.objType = pyds.NvDsObjectType.NVDS_OBJECT_TYPE_VEHICLE
meta.objClassId = PGIE_CLASS_ID_VEHICLE
obj = pyds.alloc_nvds_vehicle_object()
obj = generate_vehicle_meta(obj) #See NvDsVehicleObject example code
meta.extMsg = obj
meta.extMsgSize = sys.getsizeof(pyds.NvDsVehicleObject);
if(class_id == PGIE_CLASS_ID_PERSON):
meta.type =pyds.NvDsEventType.NVDS_EVENT_ENTRY
meta.objType = pyds.NvDsObjectType.NVDS_OBJECT_TYPE_PERSON;
meta.objClassId = PGIE_CLASS_ID_PERSON
obj = pyds.alloc_nvds_person_object()
obj=generate_person_meta(obj)
meta.extMsg = obj
meta.extMsgSize = sys.getsizeof(pyds.NvDsPersonObject)
return meta
...
# Allocating an NvDsEventMsgMeta instance and getting reference
# to it. The underlying memory is not manged by Python so that
# downstream plugins can access it. Otherwise the garbage collector
# will free it when this probe exits.
msg_meta=pyds.alloc_nvds_event_msg_meta()
msg_meta.bbox.top = obj_meta.rect_params.top
msg_meta.bbox.left = obj_meta.rect_params.left
msg_meta.bbox.width = obj_meta.rect_params.width
msg_meta.bbox.height = obj_meta.rect_params.height
msg_meta.frameId = frame_number
msg_meta.trackingId = long_to_uint64(obj_meta.object_id)
msg_meta.confidence = obj_meta.confidence
msg_meta = generate_event_msg_meta(msg_meta, obj_meta.class_id)
user_event_meta = pyds.nvds_acquire_user_meta_from_pool(batch_meta)
if(user_event_meta):
user_event_meta.user_meta_data = msg_meta;
user_event_meta.base_meta.meta_type = pyds.NvDsMetaType.NVDS_EVENT_MSG_META
# Setting callbacks in the event msg meta. The bindings layer
# will wrap these callables in C functions. Currently only one
# set of callbacks is supported.
pyds.user_copyfunc(user_event_meta, meta_copy_func)
pyds.user_releasefunc(user_event_meta, meta_free_func)
pyds.nvds_add_user_meta_to_frame(frame_meta, user_event_meta)
else:
print("Error in attaching event meta to buffer\n")
"""
这里还要提及一下关于deepstream原数据是怎样产生的,根据nvidia官方文档中的下图以及说明,主要还是多路复用器已经定义好了接下来的格式,即gst-nvstreammux,按nvidia的原话翻译是Gst-nvstreammux 插件从多个输入源形成一批帧。将源连接到 nvstreammux(muxer)时,必须使用gst_element_get_request_pad()和pad template从 muxer 请求新的 pad sink_%u。那么我们就知道了Meta值就在解码复用器固定后,通过buffer取:

到此,说明了deepstream的数据交互方式,以及加上第一篇deepstream介绍,与第二篇gstreamer的原理,基本对deepstream有一个全方位的了解。下面将介绍deepstream-imagedata-multistream测试用例。
deepstream-imagedata-multistream解析
python项目的源文件deepstream_python_apps的一些常用插件如下表格所示:
| 插件名称 | 功能 |
|---|---|
| gst-nvvideocodecs | 加速H265和H264视频解码器 |
| gst-nvstreammux | 流复用和批处理 |
| gst-nvinfer | 基于TensorRT的检测和分类的推断 |
| gst-nvtracker | KLT跟踪器实现 |
| gst-nvosd | 用于绘制框和文本叠加的API |
| gst-tiler | 将视频帧从多源渲染为2D阵列 |
| gst-eglglessink | 基于加速X11 / EGL的渲染器插件 |
| gst-nvvidconv | 缩放,格式转换,旋转 |
而deepstream-imagedata-multistream测试用例nvidia在项目目录下也是画了一张流程图,见如下图:

当然,上述不是十分完整,结合上一篇中的管道图一起基本就比较清楚了:

管道图中缺少一个探针,在nvidia的流程图中就是Probe-Metadata,这个功能是可以单独摘出来的,相当于在pipeline中增加了一个出口,整个管道本身不到最后阶段是不具备输出能力的,一般需要到gst-nvosd或者图中蓝色的GstFakesink。加入探针后,通过转换成numpy并且使用opencv输写结果,下面就将总结过程。
添加探针以获取生成的元数据:
tiler_sink_pad = tiler.get_static_pad("sink") # 对sink增加一个探头,将探头src_pad链接给回调函数,回调函数可以访问里面的数据,sink pad 数据流入
if not tiler_sink_pad:
sys.stderr.write(" Unable to get src pad \n")
else:
tiler_sink_pad.add_probe(Gst.PadProbeType.BUFFER, tiler_sink_pad_buffer_probe, 0)
# perf callback function to print fps every 5 sec
# perf回调函数,每5秒打印一次fps
GLib.timeout_add(5000, perf_data.perf_print_callback)
tiler_sink_pad_buffer_probe探针函数部分代码:
拿到tiler的sinkpad,在该位置加入probe,注册了名为tiler_sink_pad_buffer_probe的回调函数,该函数的部分代码为:
def tiler_sink_pad_buffer_probe(pad, info, u_data):
frame_number = 0
num_rects = 0
gst_buffer = info.get_buffer()
if not gst_buffer:
print("Unable to get GstBuffer ")
return
batch_meta = pyds.gst_buffer_get_nvds_batch_meta(hash(gst_buffer))
l_frame = batch_meta.frame_meta_list
frame_count = 0
while l_frame is not None:
try:
"""
标记推理结果,转换数据输出opencv图像
"""
l_frame = l_frame.next
except StopIteration:
break
上述代码的原理就是上节的Meta数据解析部分,在tiler这个插件上加入探针,相关方法见官方文档:MetaData in the DeepStream SDK
管道初始化与sources连接streammux:
Gst.init(None)
print("Creating Pipeline \n ")
pipeline = Gst.Pipeline() # 创建将形成其他元素连接的管道元素
is_live = False # 在线实时流开关
# Create nvstreammux instance to form batches from one or more sources.
""" 创建nvstreammux实例可以输入多个源类型作为一个类对象。辅助元数据结构包含框架、对象、分类器和标签数据,即定义下之后的解码逻辑,如使用NvDsBatchMeta与gst_buffer_get_nvds_batch_meta
# 我们知道,Gst-nvstreammux的作用是将各个video streammux在一起,然后进入下一个nvinfer模块。
更为详细地址的为:https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_plugin_gst-nvstreammux2.html
"""
streammux = Gst.ElementFactory.make("nvstreammux", "Stream-muxer")
if not streammux:
sys.stderr.write(" Unable to create NvStreamMux \n")
pipeline.add(streammux)
for i in range(number_sources):
os.mkdir(folder_name + "/stream_" + str(i))
frame_count["stream_" + str(i)] = 0
saved_count["stream_" + str(i)] = 0
print("Creating source_bin ", i, " \n ")
uri_name = args[i + 1]
if uri_name.find("rtsp://") == 0:
is_live = True
source_bin = create_source_bin(i, uri_name) # 构建解码器sources的element,完善其里面bin的逻辑
if not source_bin:
sys.stderr.write("Unable to create source bin \n")
pipeline.add(source_bin) # 按照顺序,首先添加sources
padname = "sink_%u" % i
sinkpad = streammux.get_request_pad(padname) #
if not sinkpad:
sys.stderr.write("Unable to create sink pad bin \n")
srcpad = source_bin.get_static_pad("src")
if not srcpad:
sys.stderr.write("Unable to create src pad bin \n")
srcpad.link(sinkpad) # 将此bin上的src pad链接到streammux中的sinkpad,这里是手动的将pad与pad连接
这里的过程即在管道图的推理模块之前,添加了sources源即rtsp流,与确定使用streammux解复用插件,相当于固定了模板,而sources部分,发现通过number_sources这个输入args将element已经分开,这在C的txt文件里是sources的配置参数,代表是否复用,那很显然,python没有,好处在于不用考虑后续将使用NvDsFrameMeta而不是NvDsBatchMeta,不好地方在于要去考虑它的并发性,不如C那样一目了然,streammux解析在于注释中。
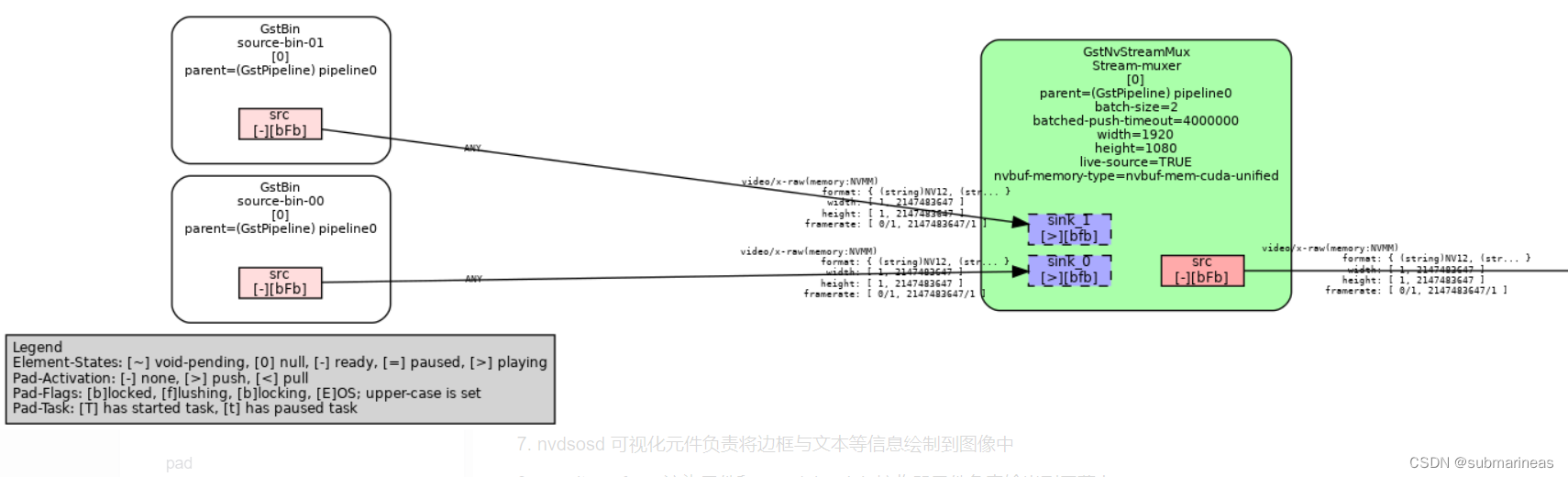
管道剩余其它插件创建与连接:
pgie = Gst.ElementFactory.make("nvinfer", "primary-inference") # 推理模块
if not pgie:
sys.stderr.write(" Unable to create pgie \n")
# Add nvvidconv1 and filter1 to convert the frames to RGBA
# which is easier to work with in Python.
print("Creating nvvidconv1 \n ")
nvvidconv1 = Gst.ElementFactory.make("nvvideoconvert", "convertor1") # 视频转换器
if not nvvidconv1:
sys.stderr.write(" Unable to create nvvidconv1 \n")
print("Creating filter1 \n ")
caps1 = Gst.Caps.from_string("video/x-raw(memory:NVMM), format=RGBA") # cap滤波
filter1 = Gst.ElementFactory.make("capsfilter", "filter1")
if not filter1:
sys.stderr.write(" Unable to get the caps filter1 \n")
filter1.set_property("caps", caps1)
print("Creating tiler \n ")
tiler = Gst.ElementFactory.make("nvmultistreamtiler", "nvtiler") # 将此批次合成为单个2D帧
if not tiler:
sys.stderr.write(" Unable to create tiler \n")
print("Creating nvvidconv \n ")
nvvidconv = Gst.ElementFactory.make("nvvideoconvert", "convertor") # 图片转换器,使从 NV12 转换为 RGBA
if not nvvidconv:
sys.stderr.write(" Unable to create nvvidconv \n")
print("Creating nvosd \n ")
nvosd = Gst.ElementFactory.make("nvdsosd", "onscreendisplay")
if not nvosd:
sys.stderr.write(" Unable to create nvosd \n")
sink = Gst.ElementFactory.make("fakesink", "nvvideo-renderer") # 显卡播放视频
if not sink:
sys.stderr.write(" Unable to create egl sink \n")
"""
省略代码:创建完所有插件后,将其全部link起来
"""
这一部分就基本很简单,C与python的都是一样,面向过程编程,这个过程就是管道创建过程,然后中间还有streammux控制输入参数,比如视频高宽、延迟时间,推理模块加载配置txt文件,tiler帧解码格式等等,可以根据自己需要来定制化。这里面虽然说每个插件就一行代码,Gst.ElementFactory.make后就创建Element成功,但其实底层nvidia封装好了,目前上面还有几个插件没有开源,开源的其实90%以上的关注对象,还是在推理和追踪上,比如说我这里找到一篇很有意思的博文,是讲怎么客制化Yolo,Deepstream6.0-python 入门 - Yolov5客制化
我下节所描述的基本就是使用别人的客制化Yolov5的案例,上述将所有插件link完后,最后再绑定message,就可以直接启动pipeline了:
# create an event loop and feed gstreamer bus mesages to it
loop = GLib.MainLoop()
bus = pipeline.get_bus()
bus.add_signal_watch()
bus.connect("message", bus_call, loop)
# List the sources
print("Now playing...")
for i, source in enumerate(args[:-1]):
if i != 0:
print(i, ": ", source)
print("Starting pipeline \n")
# start play back and listed to events
pipeline.set_state(Gst.State.PLAYING)
"""
NULL NULL状态或者初始化状态
READY element已经READY或者PAUSED
PAUSED element已经PAUSED,准备接受数据
PLAYING element在PLAYING,时钟在运行数据
"""
try:
loop.run()
except:
pass
# cleanup
print("Exiting app\n")
pipeline.set_state(Gst.State.NULL)
yolo适配deepstream
首先,关于yolo,应该不用我多介绍了,我前面也写了很多篇适配文档,比如openvino、jetson、寒武纪与昇腾等等,虽然不怎么需要自己写程序,因为前人栽树,后人乘凉。这里也是很感谢各位大佬的开源,正如此篇提到的适配yolov5的例子就是GitHub上的一个项目为:DeepStream-Yolo
如何自定义YOLO模型?
在deepstream SDK中objectDetector_Yolo示例应用程序提供了一个开源 YOLO 模型的工作示例包括:YOLOv2、YOLOv3,以及根据NVIDIA® TensorRT™校准的int8方案:tiny YOLOv2、tiny YOLOv3等,对于适配方案,我们首先可以给出一个整体的架构图:
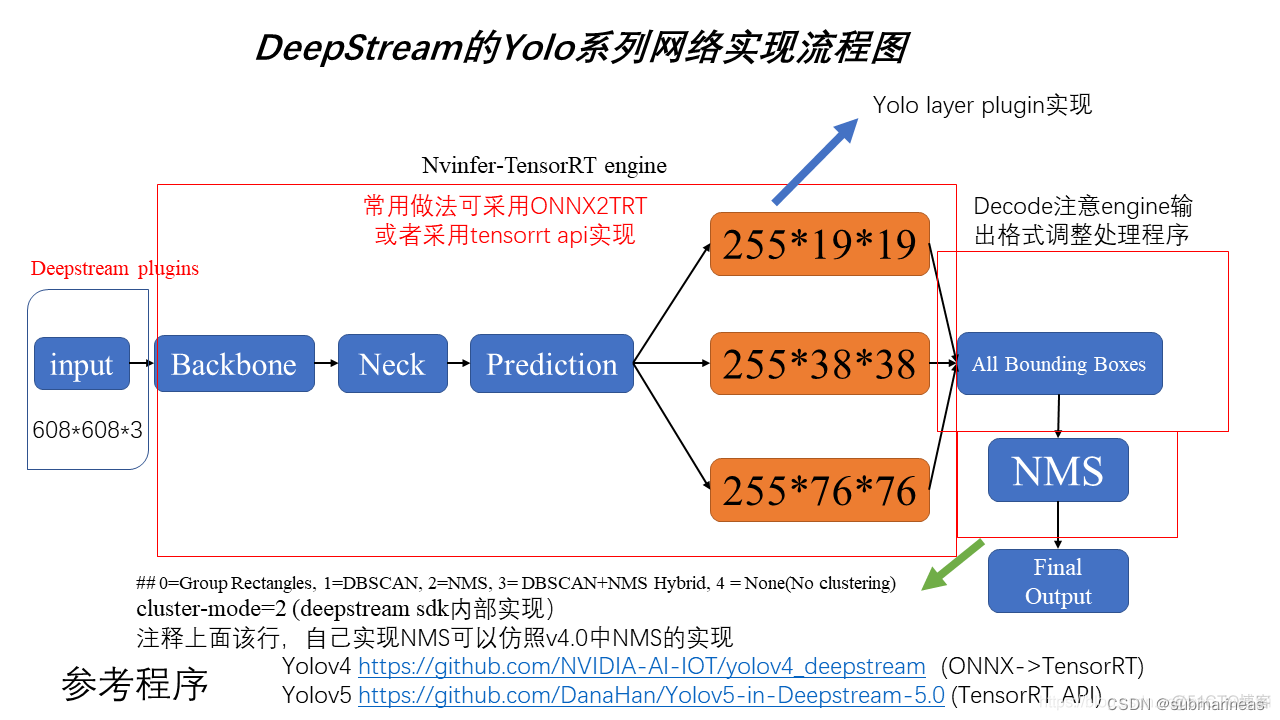
此图参考链接为:英伟达DeepStream学习笔记10——DeepStream5.0中Yolo v3的使用
上述图按我的理解,中间部分基本是tensorrt的内容,目前yolo系已经完全适配,只要有原始模型基本不需要管,需要注意的是前后处理,尺寸一定要对上,以及NMS问题,这里我们可以进入当前sdk目录nvdsinfer_custom_impl_Yolo进行查看源文件:
root@R740:/opt/nvidia/deepstream/deepstream-6.1/sources/objectDetector_Yolo/nvdsinfer_custom_impl_Yolo# tree
.
|-- Makefile
|-- kernels.cu
|-- kernels.o
|-- libnvdsinfer_custom_impl_Yolo.so
|-- nvdsinfer_yolo_engine.cpp
|-- nvdsinfer_yolo_engine.o
|-- nvdsparsebbox_Yolo.cpp
|-- nvdsparsebbox_Yolo.o
|-- trt_utils.cpp
|-- trt_utils.h
|-- trt_utils.o
|-- yolo.cpp
|-- yolo.h
|-- yolo.o
|-- yoloPlugins.cpp
|-- yoloPlugins.h
`-- yoloPlugins.o
0 directories, 17 files
该目录下源文件说明为:
- kernel.cu :实现了CUDA下预测位置,objectness和classification的sigmoid和exp处理,cuda核最底层的实现
- Makefile: 用于编译
- nvdsinfer_yolo_engine.cpp:根据网络类型创建引擎,用于生成tensorrt engine, 该例子是基于tensorrt API构建的网络定义
- nvdsparsebbox_Yolo.cpp:yolo目标检测结果的输出,用于网络预测后信息的处理包括预测框的decode和bounding box的NMS处理
- 其他文件 :用来构建Yolov3网络
- YoloPlugin: 模型搭建的一些组件以及相应的实现,是Yolo网络中的Yolo layer 的一个tensorrt custom plugin.
- trt_utils.cpp: 建立tensorRT网络的部分,已经支持的部分
- yolo.cpp :创建引擎、创建网络等的具体实现
nvidia针对yolo,适配到了yolov4,事实上后面的比如说yolov5,yolox等等都是针对这个模板进行修改,所以nvidia在更新完yolov4后我看到好像就没再更新了,而这里用到的yolov5的git,就是非官方的代码,我也发现到yolov5之后,其实需要改的也就是后处理部分,前处理与中间部分其实都已经在tensorrt里适配完全了。在接入yolov5之前,还需要前置条件,准备好deepstream学习笔记(一):C与python环境部署与测试 ,没有问题则可以先测试yolov3:
# 进入sdk默认路径
$ cd /opt/nvidia/deepstream/deepstream/sources/objectDetector_Yolo
# 运行脚本,下载yolo的模型与权重
$ sh prebuild.sh
# 将deepstream-apps-python中的deepstream-imagedata-multistream拉过来
$ cp <project_path>/deepstream-imagedata-multistream.py .
运行完上面三步后,修改deepstream-imagedata-multistream.py文件里的加速推理插件pgie.set_property加载路径,便可以直接跑了。没有bug能正常跑通,接下来就是适配yolov5了。
拉取Deepstream-Yolo源码与yolov5的源码:
$ git clone https://github.com/marcoslucianops/DeepStream-Yolo.git
# 安装yolov5环境
$ git clone https://github.com/ultralytics/yolov5.git
$ cd yolov5
$ pip3 install -r requirements.txt
# 拉取模型
$ wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
下载好模型与环境后,将模型丢于DeepStream-Yolo目录下转换cfg与weights:
$ cd yolov5
$ cp <project_path>/DeepStream-Yolo/utils/gen_wts_yoloV5.py .
# Generate the cfg and wts files (example for YOLOv5s)
$ python3 gen_wts_yoloV5.py -w yolov5s.pt
生成成功后,再将cfg与weights拷贝回DeepStream-Yolo目录下,这时候就可以编译DeepStream所需要的nvdsinfer_custom_impl_Yolo.so:
# x86 平台上的 DeepStream 6.1
$ CUDA_VER=11.6 make -C nvdsinfer_custom_impl_Yolo
# x86 平台上的 DeepStream 6.0.1 / 6.0
$ CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
# Jetson 平台上的 DeepStream 6.1
$ CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
# Jetson 平台上的 DeepStream 6.0.1 / 6.0
$ CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
编译出动态库后,更改配置,这时候yolov5的配置文件config_infer_primary_yoloV5.txt为:
[property]
gpu-id=0
net-scale-factor=0.0039215697906911373
model-color-format=0
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
# model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
labelfile-path=labels.txt
batch-size=1
network-mode=0
num-detected-classes=80
interval=0
gie-unique-id=1
process-mode=1
network-type=0
cluster-mode=4
maintain-aspect-ratio=1
parse-bbox-func-name=NvDsInferParseYolo
custom-lib-path=../DeepStream-Yolo/nvdsinfer_custom_impl_Yolo/libnvdsinfer_custom_impl_Yolo.so
engine-create-func-name=NvDsInferYoloCudaEngineGet
这里的配置项不用我说,还有模糊的可以看上一节我的注释,这里需要注意的是net-scale-factor参数,一般官方模型都是采用归一化的,如果自己训练的没有归一化,这个参数需要改成1.
至此,我们就可以测试python版本的yolov5,将测试py文件移过来,跟yolov3一样,修改加载项txt文件,可以直接跑,它就会输出预加载的网络日志与pipeline输出:
Frames will be saved in frame
Creating Pipeline
Creating streamux
......
Creating source_bin 0
......
Atleast one of the sources is live
Adding elements to Pipeline
Linking elements in the Pipeline
Now playing...
1 : rtsp://admin:xxxx2016@192.168.1.170:554/cam/realmonitor?xxxx
Starting pipeline
0:00:00.820583534 5417 0x1e7b060 INFO nvinfer gstnvinfer.cpp:646:gst_nvinfer_logger:<primary-inference> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1914> [UID = 1]: Trying to create engine from model files
Loading pre-trained weights
Loading weights of yolov5s complete
Total weights read: 7254397
Building YOLO network
layer input output weightPtr
(0) conv_silu 3 x 640 x 640 32 x 320 x 320 3584
(1) conv_silu 32 x 320 x 320 64 x 160 x 160 22272
(2) conv_silu 64 x 160 x 160 32 x 160 x 160 24448
......
(97) conv_logistic 512 x 20 x 20 255 x 20 x 20 7254397
(98) yolo 255 x 20 x 20 - -
batched_nms - 300 x 1 x 4 -
Output YOLO blob names:
yolo_93
yolo_96
yolo_99
Total number of YOLO layers: 272
Building YOLO network complete
Building the TensorRT Engine
Building complete
0:00:51.923752458 5417 0x1e7b060 INFO nvinfer gstnvinfer.cpp:646:gst_nvinfer_logger:<primary-inference> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1946> [UID = 1]: serialize cuda engine to file: /home/Download/DeepStream-Yolo/model_b1_gpu0_fp32.engine successfully
INFO: ../nvdsinfer/nvdsinfer_model_builder.cpp:610 [Implicit Engine Info]: layers num: 5
0 INPUT kFLOAT data 3x640x640
1 OUTPUT kINT32 num_detections 0
2 OUTPUT kFLOAT nmsed_boxes 300x4
3 OUTPUT kFLOAT nmsed_scores 300
4 OUTPUT kFLOAT nmsed_classes 300
0:00:53.244347189 5417 0x1e7b060 INFO nvinfer gstnvinfer_impl.cpp:328:notifyLoadModelStatus:<primary-inference> [UID 1]: Load new model:config_infer_primary_yoloV5.txt sucessfully
Decodebin child added: source
**PERF: {'stream0': 0.0}
Decodebin child added: capsfilter0
Decodebin child added: nvv4l2decoder0
In cb_newpad
...
Frame Number= 6 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
Frame Number= 7 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
Frame Number= 8 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
Frame Number= 9 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
Frame Number= 10 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
Frame Number= 11 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
Frame Number= 12 Number of Objects= 0 Vehicle_count= 0 Person_count= 0
可以看到模型参数(删了大半输出的),yolov5就调试成功了,并且当前目录下生成了model_b1_gpu0_fp32.engine的模型,这种方法得到的engine模型会比通过git上的tensorrt_yolov5将pt转onnx再转engine要快,如果都不熟悉的话,并且基本不会出错。所以,本篇博客最终适配yolov5完成。后续会更新适配yolox,以及加入追踪MOT等插件的笔记,这里因为篇幅问题,感觉写得很长了,那就到这了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











