







Spark实战项目——电商指标统计
一、引言
在实战项目中,根据不同的需求进行编程,由于需求不同,核心的计算逻辑会不同,但是其他的一些代码,如获取环境变量、读取文件等等操作是固定。本次我们采用编写框架的模式来完成我们的需求,这样的优势有:
- 代码的扩展性强;
- 减少代码的冗余;
- 将相同的功能进行封装,降低代码的耦合度;
- 将代码进行分层次,代码的逻辑看起来就非常的清晰。
采用框架的方式,在企业实际生产环境中是非常有优势的,希望大家能够学以致用。
1.1 框架设计原理
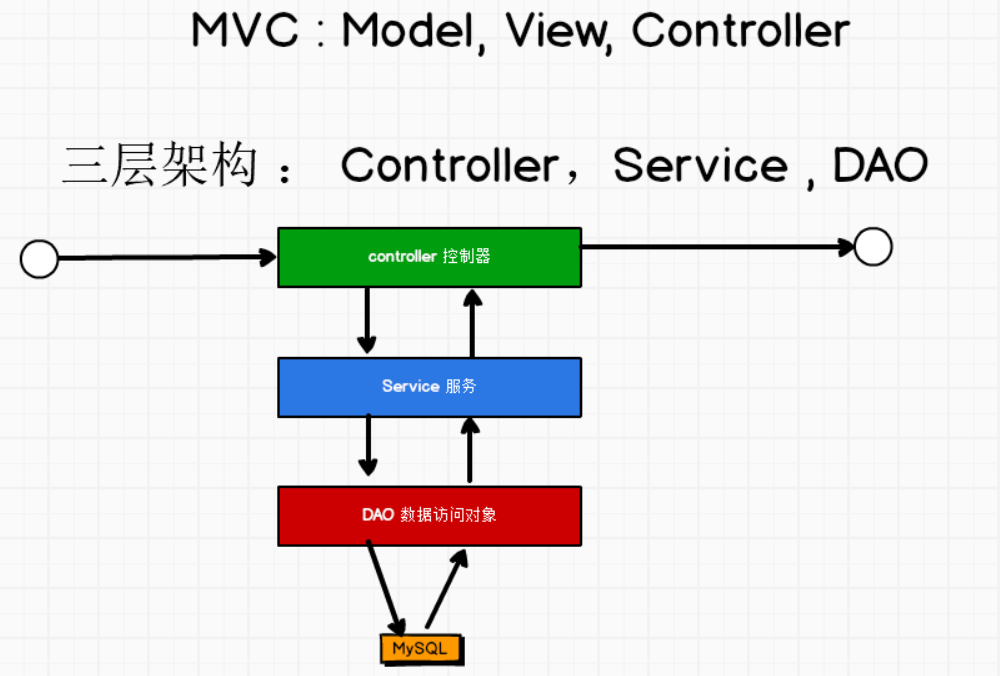
框架设计思想可以采取两种模式,一种是MVC,另外一种是三层架构,由于我们这里没有页面展示的需求,所以我们暂时采取三层架构的方式。
-- 1.三层架构的概念
1. Controller:控制层,封装调度作用,数据的流转过程
2. Service: 服务层,封装实际的计算逻辑
3. DAO :Data Access Object,数据访问对象,专门用于和一些关系型数据互相访问,用来和数据源的连接
-- 2.调用的顺序
按照下面图示。
-- 3.架构中一些其他的内容
1. bean : 用来封装一个bean类,对数据的一些封装,采用样例类,声明在包对象中
2. helper:辅助类,如累加器类
3. Apllication : 应用程序,主程序
4. Util : 工具类
1.2 框架搭建
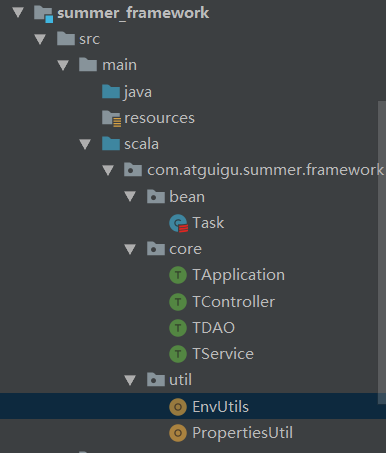
1.2.1 Util
1.2.1.1 EnvUtils
-- 如何实现三层框架共享数据呢?
1. 实现原理:在当前线程中创建一个内存,将共享数据存放在这个内存中,这样三层架构均可以使用。
2. 实现方式:
a、在线程中一直就保留着可以共享数据的空间
b、JDK API 提供了一个工具类,可以直接访问这个空间
c、只要调用这个工具类(ThreadLocal)将数据存入到共享数据中,也可以从这个内存中调用共享内存中的数据
3. 具体的步骤:
a、"创建"一个共享数据 : 案例如下:
"private val scLocal = new ThreadLocal[SparkContext] "
b、将共享数据"放进"共享空间中
"scLocal.set(sc)"
c、从当前线程的共享空间中"获取"共享数据
"scLocal.get()"
d、将共享数据从共享空间中"清除"
"scLocal.remove()"
package com.atguigu.summer.framework.util
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-09 14:00:02
*/
object EnvUtils {
// 创建一个共享数据
private val scLocal = new ThreadLocal[SparkContext]
//获取环境对象
def getEnv() = {
//从当前线程的共享空间中获取环境对象
var sc: SparkContext = scLocal.get()
if (sc == null) {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkApplication")
sc = new SparkContext(sparkConf)
scLocal.set(sc)
}
sc
}
// 清除对象
def clean() = {
getEnv().stop()
// 将共享内存中的数据清除
scLocal.remove()
}
}
1.2.1.2 PropertiesUtil
--动态获取连接的资源,将需要连接的资源配置文件放置在配置文件中,从配置文件中读取连接需要的资源,这样,当我们需要更换连接的资源时,只要修改配置文件即可。
这种思想是非常重要的,类似hadoop的RM,将资源和计算分离开,做资源的调度,扩展起来就非常的方便。
package com.atguigu.summer.framework.util
import java.util.ResourceBundle
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-23 23:37:44
*/
object PropertiesUtil {
//绑定配置文件
val summer: ResourceBundle = ResourceBundle.getBundle("summers")
def getValue(key: String): String = {
//传入一个key,返回一个value
summer.getString(key)
}
}
1.2.2 core
1.2.2.1 TApplication
-- 主程序,是个特质,只需要传递执行的逻辑,获取环境和关闭环境自动完成
package com.atguigu.summer.framework.core
import java.net.{InetAddress, ServerSocket, Socket}
import com.atguigu.summer.framework.util.{EnvUtils, PropertiesUtil}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-22 19:33:39
*/
trait TApplication {
var envdata: Any = null
//第一步:初始化环境
def start(t: String)(op: => Unit) = {
if (t == "Socket") {
envdata = new Socket(PropertiesUtil.getValue("serverhost")
, PropertiesUtil.getValue("serverport").toInt)
} else if (t == "ServerSocket") {
envdata = new ServerSocket(PropertiesUtil.getValue("serverport").toInt)
} else if (t == "Spark") {
envdata = EnvUtils.getEnv()
}
//业务逻辑
try {
op
} catch {
case ex: Exception => println("op执行失败,原因是:" + ex.getMessage)
}
//环境关闭
if (t == "ServerSocket") {
val ServerSocket = envdata.asInstanceOf[ServerSocket]
if (!ServerSocket.isClosed) {
ServerSocket.close()
}
} else if (t == "Socket") {
val socket = envdata.asInstanceOf[Socket]
if (!socket.isClosed) {
socket.close()
}
} else if (t == "Spark") {
EnvUtils.clean()
}
}
}
1.2.2.2 TController
package com.atguigu.summer.framework.core
/**
* @Description 控制器,封装调度
**
* @author lianzhipeng
* @create 2020-06-08 21:52:39
*/
trait TController {
//执行控制
def execute() : Unit
}
1.2.2.3 TService
package com.atguigu.summer.framework.core
/**
* @Description 服务,封装逻辑
**
* @author lianzhipeng
* @create 2020-06-08 21:53:31
*/
trait TService {
//数据分析
def analysis() : Any
//数据分析
def analysis(data :Any) : Any
}
1.2.2.4 TDAO
package com.atguigu.summer.framework.core
import com.atguigu.summer.framework.util.EnvUtils
import org.apache.spark.rdd.RDD
/**
* @Description 数据访问对象,专门负责和关系型数据如mysql之间的交互
**
* @author lianzhipeng
* @create 2020-06-08 21:53:56
*/
trait TDAO {
def readFile(path :String) ={
val fileRDD: RDD[String] = EnvUtils.getEnv().textFile(path)
fileRDD
}
}
二 、 实战项目
2.1 项目思路
--完成项目需求的步骤:
1. 分析原始数据的结构,包括数据的格式,数据的含义,数据之间的关系
2. 分析项目需求 -- 非常关键
a、 数据的输入是什么
b、 数据的输出是什么
3. 步骤划分:
a、根据原始数据的格式,朝着数据结果的输出一步一步的进行分解
b、几大原则:
缺什么,补什么;
少什么,加什么,
多什么,删什么。
4. 完成比完美更重要,先完成需求,再优化
5. 当出现的结果不是自己想要的时候,可以从后往前依次进行排查,排查的方式可以打印阶段计算结果,查看是否是自己想到的预期结果。
6. 一般我们会将原始数据的字段进行封装成样例类,相当于数据有了结构,同时可以封装一些方法,并可以进行模式匹配,数据也富有了含义,便于理解
2.2 原始数据
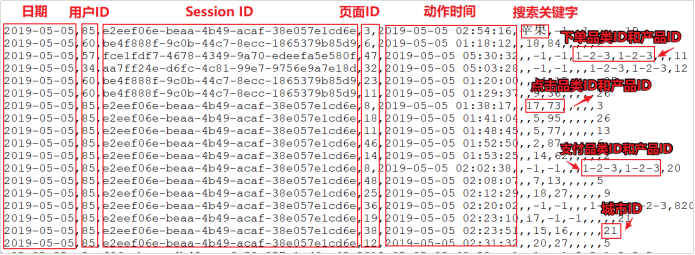
- 数据说明
-- 上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的4种行为:搜索,点击,下单,支付。数据规则如下:
1. 数据文件中每行数据采用"下划线"分隔数据
2. 每一行数据表示用户的一次行为,这个行为只能是4种行为的一种
3. 如果搜索关键字为null,表示数据不是搜索数据
4. 如果点击的品类ID和产品ID为-1,表示数据不是点击数据
5. 针对于下单行为,一次可以下单多个商品,所以品类ID和产品ID可以是多个,id之间采用逗号分隔,如果本次不是下单行为,则数据采用null表示
6. 支付行为和下单行为类似
- 详细字段说明:
| 编号 | 字段名称 | 字段类型 | 字段含义 |
|---|---|---|---|
| 1 | date | String | 用户点击行为的日期 |
| 2 | user_id | String | 用户的ID |
| 3 | session_id | String | Session的ID |
| 4 | page_id | String | 某个页面的ID |
| 5 | action_time | String | 动作的时间点 |
| 6 | search_keyword | String | 用户搜索的关键词 |
| 7 | click_category_id | String | 某一个商品品类的ID |
| 8 | click_product_id | String | 某一个商品的ID |
| 9 | order_category_ids | String | 一次订单中所有品类的ID集合 |
| 10 | order_product_ids | String | 一次订单中所有商品的ID集合 |
| 11 | pay_category_ids | String | 一次支付中所有品类的ID集合 |
| 12 | pay_product_ids | String | 一次支付中所有商品的ID集合 |
| 13 | city_id | String | 城市 id |
2.3 准备样例类
//用户访问动作表
case class UserVisitAction(
date: String,//用户点击行为的日期
user_id: String,//用户的ID
session_id: String,//Session的ID
page_id: String,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: String,//某一个商品品类的ID
click_product_id: String,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: String //城市 id
)
2.4 需求1:Top10热门品类
--需求具体说明
1. 分别统计每个品类点击的次数,下单的次数和支付的次数:
(品类,点击总数)(品类,下单总数)(品类,支付总数)
2. 先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。
3. 取Top10
2.4.1 数据结构分析
-- 原始数据:
//2019-07-27_ ==>日期 0
// 73_ ==>用户ID 1
// d79508b4-66bf-4410-a5bb-f67a8831610f_ ==>会话ID 2
// 45_ ==>页面ID 3
// 2019-07-27 19:47:55_ ==>动作时间 4
// null_ ==>搜索 5
// 9_ ==>点击品类ID,不是则为-1 6
// 51_ ==>点击产品ID,不是则为-1 7
// null_ ==>下单品类ID,不是则为null 8
// null_ ==>下单产品ID,不是则为null 9
// null_ ==>支付品类ID,不是则为null 10
// null_ ==>支付产品ID ,不是则为null 11
// 6 ==>城市ID,不是则为null 12
2.4.2 数据结果分析
-- 最后结果:
1. (品类,(clickCount,orderCont,payCount)),
2. 多个品类之间,按照clickCount,orderCont,payCount的大小依次进行排序,然后取排名的前10名。
2.4.5 实现步骤
-- 具体实现步骤
1. 数据进行切分,根据每条数据是哪种行为,将数据转换为:
(品类,(1,0,0)) : 点击行为
(品类,(0,1,0)) : 下单行为
(品类,(0,0,1)) : 支付行为
2. 按照品类进行分组聚合:
品类,(clickCount,orderCont,payCount)
3. 排序取前10
-- 数据来龙去脉分析清楚以后,写代码都是分分钟的事情
2.2.6 代码实现
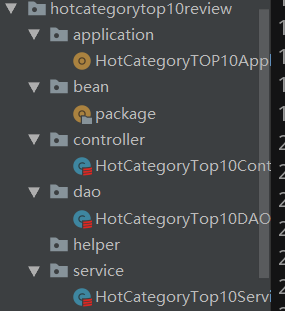
2.2.6.1 bean
package com.atguigu.core.hotcategorytop10review
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:48:41
*/
package object bean {
//用户访问动作表
case class UserVisitAction(
date: String,//用户点击行为的日期
user_id: String,//用户的ID
session_id: String,//Session的ID
page_id: String,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: String,//某一个商品品类的ID
click_product_id: String,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: String //城市 id
)
}
2.2.6.2 HotCategoryTOP10ApplicationReview
package com.atguigu.core.hotcategorytop10review.application
import com.atguigu.core.hotcategorytop10review.controller.HotCategoryTop10ControllerReview
import com.atguigu.summer.framework.core.TApplication
/**
* @Description 应用程序启动层
**
* @author lianzhipeng
* @create 2020-06-11 0:35:53
*/
object HotCategoryTOP10ApplicationReview extends App with TApplication{
start("Spark"){
val hotCategoryTop10ControllerReview = new HotCategoryTop10ControllerReview
hotCategoryTop10ControllerReview.execute()
}
}
2.2.6.3 HotCategoryTop10ControllerReview
package com.atguigu.core.hotcategorytop10review.controller
import com.atguigu.core.hotcategorytop10review.service.HotCategoryTop10ServiceReview
import com.atguigu.summer.framework.core.TController
/**
* @Description 控制层
**
* @author lianzhipeng
* @create 2020-06-11 0:36:40
*/
class HotCategoryTop10ControllerReview extends TController{
private val hotCategoryTop10ServiceReview = new HotCategoryTop10ServiceReview
override def execute(): Unit = {
val result: Array[(String, (Int, Int, Int))] = hotCategoryTop10ServiceReview.analysis()
result.foreach(println)
}
}
2.2.6.4 HotCategoryTop10DAOReview
package com.atguigu.core.hotcategorytop10review.dao
import com.atguigu.core.hotcategorytop10review.bean.UserVisitAction
import com.atguigu.summer.framework.core.TDAO
import org.apache.spark.rdd.RDD
/**
* @Description 资源连接层
* *
* @author lianzhipeng
* @create 2020-06-11 0:38:25
*/
class HotCategoryTop10DAOReview extends TDAO {
def getUserVisitAction() = {
// 读取路径下的数据
val fileRDD: RDD[String] = readFile("input/user_visit_action.txt")
// 将数据封装对象
fileRDD.map(
data => {
val datasArray: Array[String] = data.split("_")
UserVisitAction(
datasArray(0),
datasArray(1),
datasArray(2),
datasArray(3),
datasArray(4),
datasArray(5),
datasArray(6),
datasArray(7),
datasArray(8),
datasArray(9),
datasArray(10),
datasArray(11),
datasArray(12)
)
}
)
}
}
2.2.6.5 HotCategoryTop10ServiceReview
package com.atguigu.core.hotcategorytop10review.service
import java.io
import com.atguigu.core.hotcategorytop10review.bean
import com.atguigu.core.hotcategorytop10review.dao.HotCategoryTop10DAOReview
import com.atguigu.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @Description 计算逻辑层
**
* @author lianzhipeng
* @create 2020-06-11 0:37:41
*/
class HotCategoryTop10ServiceReview extends TService{
private val hotCategoryTop10DAOReview = new HotCategoryTop10DAOReview
override def analysis() = {
// 获取数据,数据已经被封装成一个一个的对象
val UserRDD: RDD[bean.UserVisitAction] = hotCategoryTop10DAOReview.getUserVisitAction()
//1. 数据进行切分,根据每条数据是哪种行为,将数据转换为:
// (品类,(1,0,0)) : 点击行为
// (品类,(0,1,0)) : 下单行为
// (品类,(0,0,1)) : 支付行为
val cagegoryToOneRDD: RDD[(String, (Int, Int, Int))] = UserRDD.flatMap(UserBean => {
if (UserBean.click_category_id != "-1") {
List((UserBean.click_category_id, (1, 0, 0)))
} else if (UserBean.order_category_ids != "null") {
val ids: Array[String] = UserBean.order_category_ids.split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (UserBean.pay_category_ids != "null") {
val ids: Array[String] = UserBean.pay_category_ids.split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
})
//2. 按照品类进行分组聚合:
// 品类,(clickCount,orderCont,payCount)
val categorySumRDD: RDD[(String, (Int, Int, Int))] = cagegoryToOneRDD.reduceByKey {
case ((click, order, pay), (click1, order1, pay1)) => {
(click + click1, order + order1, pay + pay1)
}
}
//3. 排序取前10
val result: Array[(String, (Int, Int, Int))] = categorySumRDD.sortBy(_._2,false).take(10)
result
}
override def analysis(data: Any): Any = ???
}
- 计算结果如下

2.2.7 优化:使用累加器
2.2.7.1 更新bean
-- 添加新的样例类HotCagetoryBean
package com.atguigu.core.hotcategorytop10review
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:48:41
*/
package object bean {
//用户访问动作表
case class HotCagetoryBean(
category_id: String,//某一个商品品类的ID
var clickCount: Long,//点击的次数
var orderCount: Long,//下单的次数
var payCount: Long,//支付的次数
)
//用户访问动作表
case class UserVisitAction(
date: String,//用户点击行为的日期
user_id: String,//用户的ID
session_id: String,//Session的ID
page_id: String,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: String,//某一个商品品类的ID
click_product_id: String,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: String //城市 id
)
}
2.2.7.2 累加器 : HotCategoryTop10AccumulatorReview
-- 因为是统计出现的次数,然后进行累加,所以我们可以使用累加器的方式,从而减少shuffle的阶段。
-- 累加器重点
1. 明确编程累加器的步骤,声明类加器,注册累加器,使用累加器,获取累加器的值
2. 明确6个重写方法的作用
3. 明确累加器输入的值和输出值的数据,从而必须知道输入值的类型和输出值的类型
-- 总结:
在写累加器的时候出现如下情况:
1. 更新add方法时,数据累加出现错误,最后执行结果为0,发现是
bean.clickCount += 1 写成了 bean.clickCount + 1
2. 进行数据累加时,发现通不过,原来的是封装的HotCagetoryBean,属性均是val类型,不可变,需改为var类型
package com.atguigu.core.hotcategorytop10review.helper
import com.atguigu.core.hotcategorytop10review.bean.HotCagetoryBean
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 1:52:29
*/
class HotCategoryTop10AccumulatorReview extends AccumulatorV2[(String,String),mutable.Map[String,HotCagetoryBean]]{
/*
in:品类,行为
out:品类,HotCagetoryBean
*/
private val hotCategoryMap = mutable.Map[String,HotCagetoryBean]()
override def isZero: Boolean = hotCategoryMap.isEmpty
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCagetoryBean]] = {
new HotCategoryTop10AccumulatorReview
}
override def reset(): Unit = hotCategoryMap.clear()
/*
add操作是在同一个executor中的操作,将executor中的所有数据一个一个进行累加,然后将累加以后的计算结果返回给
Driver。
*/
override def add(v: (String, String))= {
val category: String = v._1
val action: String = v._2
//判断当前的品类在当前的集合中是否存在,如果存在,value,如果没有,则创建对应的value
val bean: HotCagetoryBean = hotCategoryMap.getOrElse(category,HotCagetoryBean(category,0,0,0))
// 根据行为的不同,更新当前累加器的值
action match{
case "click" => bean.clickCount += 1
case "order" => bean.orderCount += 1
case "pay" => bean.payCount += 1
case _ =>
}
// 更新当前cagetory的value值
hotCategoryMap(category) = bean
}
/*
merge操作是在driver端完成,所有的executor将自己的计算结果,也就是累加器返回给driver,那么在driver端
就会多个累加器,此方法就是实现在driver将累加器进行两两合并,得到最后的结果
*/
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCagetoryBean]]) = {
other.value.foreach{
case (category,bean) =>{
val value: HotCagetoryBean = hotCategoryMap.getOrElse(category,HotCagetoryBean(category,0,0,0))
value.clickCount += bean.clickCount
value.orderCount += bean.orderCount
value.payCount += bean.payCount
hotCategoryMap(category) = value
}
}
}
/*
返回累加器的值
*/
override def value: mutable.Map[String, HotCagetoryBean] = hotCategoryMap
}
2.2.7.3 更新HotCategoryTop10ServiceReview
-- 总结:
1. 在进行累加器处理时,使用了map算子,错误,应该使用foreach就行,挨个遍历数据
package com.atguigu.core.hotcategorytop10review.service
import com.atguigu.core.hotcategorytop10review.bean.HotCagetoryBean
import com.atguigu.core.hotcategorytop10review.dao.HotCategoryTop10DAOReview
import com.atguigu.core.hotcategorytop10review.helper.HotCategoryTop10AccumulatorReview
import com.atguigu.summer.framework.core.TService
import com.atguigu.summer.framework.util.EnvUtils
import org.apache.spark.rdd.RDD
import scala.collection.mutable
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:37:41
*/
class HotCategoryTop10ServiceReview extends TService{
private val hotCategoryTop10DAOReview = new HotCategoryTop10DAOReview
override def analysis() = {
// 1.获取数据
val fileRDD: RDD[String] = hotCategoryTop10DAOReview.readFile("input/user_visit_action.txt")
// 2. 创建累加器
val acc = new HotCategoryTop10AccumulatorReview
// 3. 注册累加器
EnvUtils.getEnv().register(acc)
fileRDD.foreach(data => {
val datas: Array[String] = data.split("_")
if (datas(6) != "-1") {
acc.add(datas(6),"click")
} else if (datas(8) != "null") {
val ids: Array[String] =datas(8).split(",")
ids.foreach(id => acc.add(id,"order"))
} else if (datas(10) != "null") {
val ids: Array[String] =datas(10).split(",")
ids.foreach(id => acc.add(id,"pay"))
}
})
//3. 获取累加器的值,排序取前10
val HotCagetoryMap: mutable.Map[String, HotCagetoryBean] = acc.value
// 4. 排序取前10
val reslut: List[(String, (Long, Long, Long))] = HotCagetoryMap.map {
case (category, bean) => {
(category, (bean.clickCount, bean.orderCount, bean.payCount))
}
}.toList.sortBy(_._2)(Ordering.Tuple3(Ordering.Long.reverse, Ordering.Long.reverse, Ordering.Long.reverse))
.take(10)
reslut
}
override def analysis(data: Any): Any = ???
}
2.2.7.4 其余结构不变
2.2.7.5 运行结果
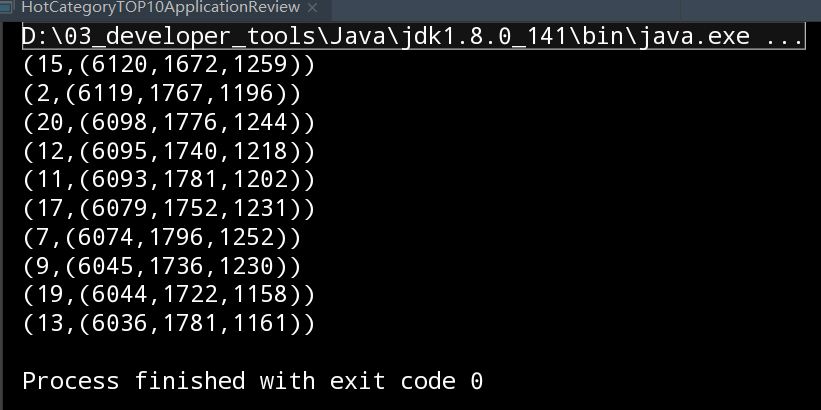
2.2.8 需求1总结
-- 总结:
在写累加器的时候出现如下情况:
1. 在进行累加器处理时,使用了map算子,错误,应该使用foreach就行,挨个遍历数据
2. 更新add方法时,数据累加出现错误,最后执行结果为0,发现是
bean.clickCount += 1 写成了 bean.clickCount + 1
3. 进行数据累加时,发现通不过,原来的是封装的HotCagetoryBean,属性均是val类型,不可变,需改为var类型
2.5 需求2:Top10热门品类中每个品类的Top10活跃点击Session统计
2.5.1 数据结构
--需求1的计算结果
(15,(6120,1672,1259))
(2,(6119,1767,1196))
(20,(6098,1776,1244))
(12,(6095,1740,1218))
(11,(6093,1781,1202))
(17,(6079,1752,1231))
(7,(6074,1796,1252))
(9,(6045,1736,1230))
(19,(6044,1722,1158))
(13,(6036,1781,1161))
2.5.2 数据结果分析
1. 统计上面10个品类中,每个品类,按照session进行分组,按照统计次数从大到小进行排序,然后取出前10的session
2. 说明,同一个session中会执行多个操作,比如点击、下单、支付等操作,那么就说明在一个session中,一个品类会出现多次。
3. 希望得到的结果:
(品类,Iterator((session1,count1),(session2,count2)....))
2.5.3 实现步骤
1. 获取需求1结果的top10的品类
2. 过滤数据,
a、首先过滤不是点击的数据
b、过滤点击数据中,品类不在top10品类中的数据
3. 进行数据结构转换,将数据转换成:
"(品类-session,1)"
4. 分组聚合
"(品类-session,count)"
5. 结构转换
"(品类, (session,count))"
6. 按照品类分组
"(品类,Iterator((session1,count1),(session2,count2)....))"
7. 结构转换,对value进行排序,然后取value排名的前10
2.5.4 代码实现
2.5.4.1 HotCategorySessionTOP10ApplicationReview
package com.atguigu.core.hotcategorytop10review.application
import com.atguigu.core.hotcategorytop10review.controller.HotCategorySessionop10ControllerReview
import com.atguigu.summer.framework.core.TApplication
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:35:53
*/
object HotCategorySessionTOP10ApplicationReview extends App with TApplication{
start("Spark"){
val hotCategorySessionop10ControllerReview = new HotCategorySessionop10ControllerReview
hotCategorySessionop10ControllerReview.execute()
}
}
2.5.4.2 HotCategorySessionop10ControllerReview
package com.atguigu.core.hotcategorytop10review.controller
import com.atguigu.core.hotcategorytop10review.service.{HotCategorySessionTop10ServiceReview, HotCategoryTop10ServiceReview}
import com.atguigu.summer.framework.core.TController
import org.apache.spark.rdd.RDD
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-11 0:36:40
*/
class HotCategorySessionop10ControllerReview extends TController {
private val hotCategorySessionTop10ServiceReview = new HotCategorySessionTop10ServiceReview
private val hotCategoryTop10ServiceReview = new HotCategoryTop10ServiceReview
override def execute(): Unit = {
val data: List[(String, (Long, Long, Long))] = hotCategoryTop10ServiceReview.analysis()
val result: RDD[(String, List[(String, Int)])] = hotCategorySessionTop10ServiceReview.analysis(data)
result.foreach(println)
}
}
2.5.4.3 HotCategorySessionTop10DAOReview
package com.atguigu.core.hotcategorytop10review.dao
import com.atguigu.core.hotcategorytop10review.bean.UserVisitAction
import com.atguigu.summer.framework.core.TDAO
import org.apache.spark.rdd.RDD
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-11 0:38:25
*/
class HotCategorySessionTop10DAOReview extends TDAO {
def getUserVisitAction() = {
// 读取路径下的数据
val fileRDD: RDD[String] = readFile("input/user_visit_action.txt")
// 将数据封装对象
fileRDD.map(
data => {
val datasArray: Array[String] = data.split("_")
UserVisitAction(
datasArray(0),
datasArray(1),
datasArray(2),
datasArray(3),
datasArray(4),
datasArray(5),
datasArray(6),
datasArray(7),
datasArray(8),
datasArray(9),
datasArray(10),
datasArray(11),
datasArray(12)
)
}
)
}
}
2.5.4.4 HotCategorySessionTop10ServiceReview
package com.atguigu.core.hotcategorytop10review.service
import com.atguigu.core.hotcategorytop10review.bean
import com.atguigu.core.hotcategorytop10review.dao.{HotCategorySessionTop10DAOReview, HotCategoryTop10DAOReview}
import com.atguigu.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:37:41
*/
class HotCategorySessionTop10ServiceReview extends TService{
private val hotCategorySessionTop10DAOReview = new HotCategorySessionTop10DAOReview
override def analysis(data: Any) = {
// 获取将数据封装成对象的数据
val UserRDD: RDD[bean.UserVisitAction] = hotCategorySessionTop10DAOReview.getUserVisitAction()
// 1. 获取需求1结果的top10的品类
val datas: List[(String, (Long, Long, Long))] = data.asInstanceOf[List[(String, (Long, Long, Long))]]
val categoryList: List[String] = datas.map(_._1)
// 2. 过滤数据
// a、首先过滤不是点击的数据
// b、过滤点击数据中,品类不在top10品类中的数据
val clickSession: RDD[bean.UserVisitAction] = UserRDD.filter(Userbean => {
Userbean.click_category_id != "-1" && categoryList.contains(Userbean.click_category_id)
})
// 3. 进行数据结构转换,将数据转换成:
// "(品类&session,1)"
val mapRDD: RDD[(String, Int)] = clickSession.map(Userbean => {
(Userbean.click_category_id + "&" + Userbean.session_id, 1)
})
// 4. 分组聚合
// "(品类&session,count)"
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
// 5. 结构转换
// "(品类, (session,count))"
val mapRDD1: RDD[(String, (String, Int))] = reduceRDD.map {
case (data, count) => {
val array: Array[String] = data.split("&")
(array(0), (array(1), count))
}
}
// 6. 按照品类分组
// "(品类,Iterator((session1,count1),(session2,count2)....))"
val groupByRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD1.groupByKey()
// 7. 结构转换,对value进行排序,然后取value排名的前10
val resultRDD: RDD[(String, List[(String, Int)])] = groupByRDD.mapValues(iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(10)
})
resultRDD
}
override def analysis() = {}
}
2.5.4.5 运行结果

2.5.5 优化:使用广播变量
仅修改一下HotCategorySessionTop10ServiceReview代码即可
// 广播变量
val broadCast: Broadcast[List[String]] = EnvUtils.getEnv().broadcast(categoryList)
// 2. 过滤数据
// a、首先过滤不是点击的数据
// b、过滤点击数据中,品类不在top10品类中的数据
val clickSession: RDD[bean.UserVisitAction] = UserRDD.filter(Userbean => {
//获取广播变量的值
Userbean.click_category_id != "-1" && broadCast.value.contains(Userbean.click_category_id)
})
2.5.6 需求2总结
-- 1. 在进行数据组合时,分割符和原始数据的分隔符一致,导致后面进行数据切分时,数据产生了丢失。
开始是:"(品类-session,count)"
修正后:"(品类&session,count)"
2.6 需求3:页面单跳转换率统计
2.6.1 数据结构
-- 原始数据:
//2019-07-27_ ==>日期 0
// 73_ ==>用户ID 1
// d79508b4-66bf-4410-a5bb-f67a8831610f_ ==>会话ID 2
// 45_ ==>页面ID 3
// 2019-07-27 19:47:55_ ==>动作时间 4
// null_ ==>搜索 5
// 9_ ==>点击品类ID,不是则为-1 6
// 51_ ==>点击产品ID,不是则为-1 7
// null_ ==>下单品类ID,不是则为null 8
// null_ ==>下单产品ID,不是则为null 9
// null_ ==>支付品类ID,不是则为null 10
// null_ ==>支付产品ID ,不是则为null 11
// 6 ==>城市ID,不是则为null 12
2.6.2 数据结果分析
-- 需求分析
什么是页面单跳转换率?
a、在一次会话中,用户会多次且反复执行搜索、点击、下单、支付等操作
b、在一次会话中,执行的操作是按照时间依次进行
c、转换率就是:假如A页面一共被访问n次,从A页面直接跳转B页面的次数为m次,那么A到B页面的转换率pageFlowRate=n/m
-- 希望得到的结果是:
("id1-id2",pageFlowRate)
("id1-id3",pageFlowRate)
.....
2.6.3 实现步骤
1. 根据需求可知,页面转换率是指在同一次会话中才有效
统计每个页面id出现的次数
2. 按照session进行分组,
(session,List(bean1,bean2,...))
3. 对value值进行结构转换
3.1 按照时间进行升序排序
3.2 对数据进行转换
(页面id1,页面id2,页面id3...)
3.3 对数据进行关联
((id1-id2),1),((id2-id3),1)
4. 对3的结果数据进行数据转换,将key去掉,只保留value,并进行扁平化
((id1-id2),1),((id2-id3),1)
5. 按照key进行分组聚合
((id1-id2),count)
((id2-id3),count)
6. 获取转换率
((id1-id2),count)
6.1 获取id1被访问的总次数
6.2 使用count/总次数就是转换率
2.6.4 代码实现
2.6.4.1 PageFlowApplicationReview
package com.atguigu.core.hotcategorytop10review.application
import com.atguigu.core.hotcategorytop10review.controller.PageFlowControllerReview
import com.atguigu.summer.framework.core.TApplication
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:35:53
*/
object PageFlowApplicationReview extends App with TApplication{
start("Spark"){
val pageFlowControllerReview = new PageFlowControllerReview
pageFlowControllerReview.execute()
}
}
2.6.4.2 PageFlowControllerReview
package com.atguigu.core.hotcategorytop10review.controller
import com.atguigu.core.hotcategorytop10review.service.PageFlowServiceReview
import com.atguigu.summer.framework.core.TController
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-11 0:36:40
*/
class PageFlowControllerReview extends TController {
private val pageFlowServiceReview = new PageFlowServiceReview
override def execute(): Unit = {
pageFlowServiceReview.analysis()
// result.foreach(println)
}
}
2.6.4.3 PageFlowDAOReview
package com.atguigu.core.hotcategorytop10review.dao
import com.atguigu.core.hotcategorytop10review.bean.UserVisitAction
import com.atguigu.summer.framework.core.TDAO
import org.apache.spark.rdd.RDD
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-06-11 0:38:25
*/
class PageFlowDAOReview extends TDAO {
def getUserVisitAction() = {
// 读取路径下的数据
val fileRDD: RDD[String] = readFile("input/user_visit_action.txt")
// 将数据封装对象
fileRDD.map(
data => {
val datasArray: Array[String] = data.split("_")
UserVisitAction(
datasArray(0),
datasArray(1),
datasArray(2),
datasArray(3),
datasArray(4),
datasArray(5),
datasArray(6),
datasArray(7),
datasArray(8),
datasArray(9),
datasArray(10),
datasArray(11),
datasArray(12)
)
}
)
}
}
2.6.4.4 PageFlowServiceReview
package com.atguigu.core.hotcategorytop10review.service
import com.atguigu.core.hotcategorytop10review.bean
import com.atguigu.core.hotcategorytop10review.dao.PageFlowDAOReview
import com.atguigu.summer.framework.core.TService
import org.apache.spark.rdd.RDD
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:37:41
*/
class PageFlowServiceReview extends TService{
private val pageFlowDAOReview = new PageFlowDAOReview
override def analysis() = {
// 1. 根据需求可知,页面转换率是指在同一次会话中才有效
// 统计每个页面id出现的次数
val UserRDD: RDD[bean.UserVisitAction] = pageFlowDAOReview.getUserVisitAction()
UserRDD.cache()
val pageIDCount: Array[(String, Int)] = UserRDD.groupBy(_.page_id).mapValues(_.size).collect()
// 2. 按照session进行分组,
// (session,List(bean1,bean2,...))
val groupByRDD: RDD[(String, Iterable[bean.UserVisitAction])] = UserRDD.groupBy(_.session_id)
// 3. 对value值进行结构转换
val pageIDSToOneRDD: RDD[(String, List[(String, Int)])] = groupByRDD.mapValues(iter => {
// 3.1 按照时间进行升序排序
val sortByList: List[bean.UserVisitAction] = iter.toList.sortBy(_.action_time)
// 3.2 对数据进行转换
// (页面id1,页面id2,页面id3...)
val pageIdList: List[String] = sortByList.map(_.page_id)
// 3.3 对数据进行关联
// ((id1-id2),1),((id2-id3),1)
val zipPageIDList: List[(String, String)] = pageIdList.zip(pageIdList.tail)
val mapPageIdList: List[(String, Int)] = zipPageIDList.map(tuple => {
(tuple._1 + "-" + tuple._2, 1)
})
mapPageIdList
})
// 4. 对3的结果数据进行数据转换,将key去掉,只保留value,并进行扁平化
// ((id1-id2),1),((id2-id3),1)
val flatMapRD: RDD[(String, Int)] = pageIDSToOneRDD.map(_._2).flatMap(iter => iter)
println(flatMapRD.count())
// 5. 按照key进行分组聚合
// ((id1-id2),count)
// ((id2-id3),count)
val pageFlowCountRDD: RDD[(String, Int)] = flatMapRD.reduceByKey(_ + _)
// 6. 获取转换率
pageFlowCountRDD.foreach{
case(ids,count) => {
// ((id1-id2),count)
// 6.1 获取id1被访问的总次数
val idArray: Array[String] = ids.split("-")
val sum: Int = pageIDCount.toMap.getOrElse(idArray(0),1)
// 6.2 使用count/总次数就是转换率
println("页面id:【" + ids + "】的转换率为:" + count.toDouble/sum )
}
}
}
override def analysis(data: Any): Any = ???
}
2.6.4.5 运行结果
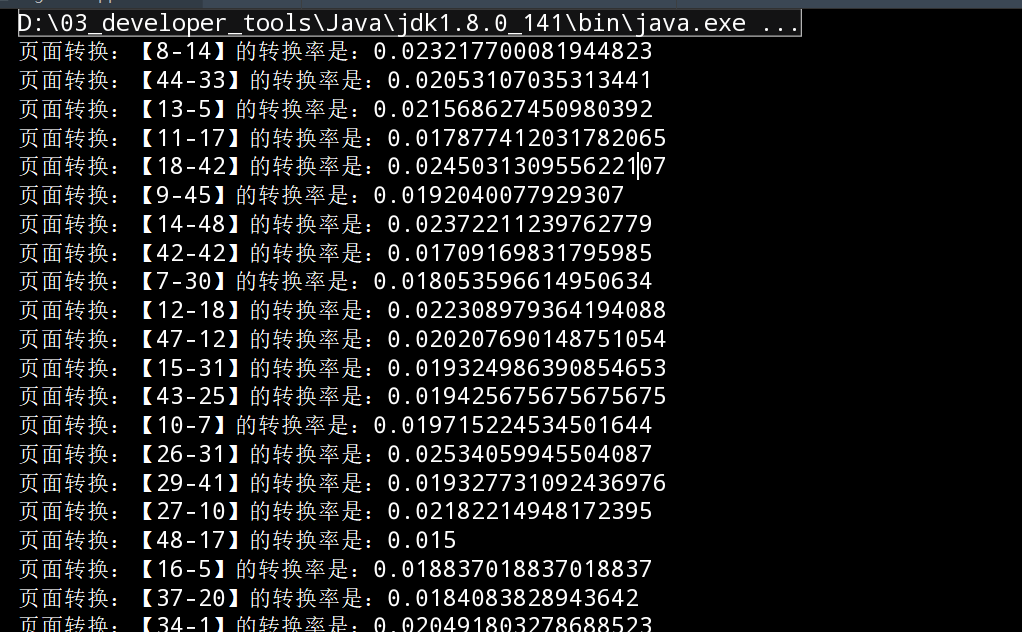
2.6.4 指定页面转换率
在实际开发情况中,我们只需要一些指定的页面流转率。

2.6.4.1 修改PageFlowServiceReview
package com.atguigu.core.hotcategorytop10review.service
import com.atguigu.core.hotcategorytop10review.bean
import com.atguigu.core.hotcategorytop10review.dao.PageFlowDAOReview
import com.atguigu.summer.framework.core.TService
import com.atguigu.summer.framework.util.EnvUtils
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:37:41
*/
class PageFlowServiceReview extends TService{
private val pageFlowDAOReview = new PageFlowDAOReview
override def analysis() = {
// 1. 根据需求可知,页面转换率是指在同一次会话中才有效
// 1.1 指定的页面id,(1-2,2-3,3-4...,6-7)
val pageid = List(1,2,3,4,5,6,7)
val pageFlowIDs: List[String] = pageid.zip(pageid.tail).map(tuple => tuple._1 + "-" + tuple._2)
val broadCast: Broadcast[List[String]] = EnvUtils.getEnv().broadcast(pageFlowIDs)
// 1.2 先过滤掉不需要统计的页面id,统计剩余页面id出现的次数
val UserRDD: RDD[bean.UserVisitAction] = pageFlowDAOReview.getUserVisitAction()
UserRDD.cache()
val pageIDCount: Array[(String, Int)] = UserRDD
.filter(bean=>pageid.init.contains(bean.page_id.toInt))
.groupBy(_.page_id)
.mapValues(_.size).
collect()
// 2. 按照session进行分组,
// (session,List(bean1,bean2,...))
val groupByRDD: RDD[(String, Iterable[bean.UserVisitAction])] = UserRDD.groupBy(_.session_id)
// 3. 对value值进行结构转换
val pageIDSToOneRDD: RDD[(String, List[(String, Int)])] = groupByRDD.mapValues(iter => {
// 3.1 按照时间进行升序排序
val sortByList: List[bean.UserVisitAction] = iter.toList.sortBy(_.action_time)
// 3.2 对数据进行转换
// (页面id1,页面id2,页面id3...)
val pageIdList: List[String] = sortByList.map(_.page_id)
// 3.3 对数据进行关联
// ((id1-id2),1),((id2-id3),1)
val zipPageIDList: List[(String, String)] = pageIdList.zip(pageIdList.tail)
val mapPageIdList: List[(String, Int)] = zipPageIDList.map(tuple => {
(tuple._1 + "-" + tuple._2, 1)
})
// 3.4 过滤掉不需要统计的页面流转
val filtPageIDList: List[(String, Int)] = mapPageIdList.filter(tuple => {
broadCast.value.contains(tuple._1)
})
filtPageIDList
})
// 4. 对3的结果数据进行数据转换,将key去掉,只保留value,并进行扁平化
// ((id1-id2),1),((id2-id3),1)
val flatMapRD: RDD[(String, Int)] = pageIDSToOneRDD.map(_._2).flatMap(iter => iter)
// 5. 按照key进行分组聚合
// ((id1-id2),count)
// ((id2-id3),count)
val pageFlowCountRDD: RDD[(String, Int)] = flatMapRD.reduceByKey(_ + _)
// 6. 获取转换率
pageFlowCountRDD.foreach{
case(ids,count) => {
// ((id1-id2),count)
// 6.1 获取id1被访问的总次数
val idArray: Array[String] = ids.split("-")
val sum: Int = pageIDCount.toMap.getOrElse(idArray(0),1)
// 6.2 使用count/总次数就是转换率
println("页面id:【" + ids + "】的转换率为:" + count.toDouble/sum )
}
}
}
override def analysis(data: Any): Any = ???
}
2.6.4.2 运行结果
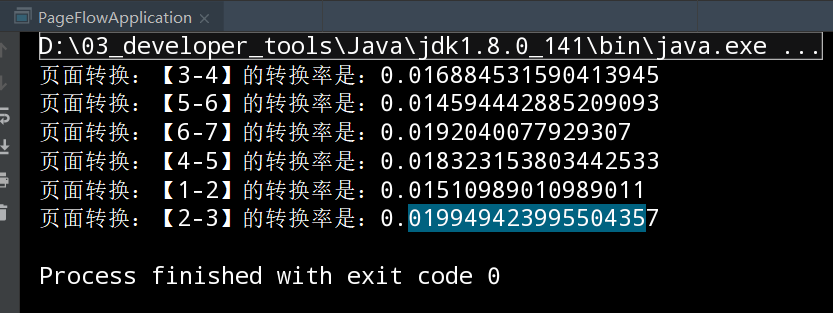
2.6.5 需求3总结
-- 计算转换率的时候算子使用错误,使用map没有结果,后来更换成foreach就可以了。
2.7 需求4 :统计页面id的平均停留时间
2.7.1 数据结构
-- 原始数据:
//2019-07-27_ ==>日期 0
// 73_ ==>用户ID 1
// d79508b4-66bf-4410-a5bb-f67a8831610f_ ==>会话ID 2
// 45_ ==>页面ID 3
// 2019-07-27 19:47:55_ ==>动作时间 4
// null_ ==>搜索 5
// 9_ ==>点击品类ID,不是则为-1 6
// 51_ ==>点击产品ID,不是则为-1 7
// null_ ==>下单品类ID,不是则为null 8
// null_ ==>下单产品ID,不是则为null 9
// null_ ==>支付品类ID,不是则为null 10
// null_ ==>支付产品ID ,不是则为null 11
// 6 ==>城市ID,不是则为null 12
2.7.2 需求结果分析
-- 需求分析:
1. 单页面id的平均停留时间,是以一个session会话为单位,计算在一个session中页面A停留时间,然后将所有会话中页面A的停留时间汇总,除于这个页面id出现的次数,就是平均停留时间。
2. 但是在一个会话的最后一个页面id只有行为时间,没有停留时间,则最后一个页面id的停留时间则忽略不计
3. 统计个数时,最后一个id也不计数
2.7.3 实现步骤
1. 按session进行分组
(session,Iterator(bean1,bean2...))
2. 对分组的value进行操作
2.1 根据时间升序排序,再进行结构转换
(pageid1,time1),(pageid2,time2),.....
2.2 拉链数据
((pageid1,time1),(pageid2,time2)), ((pageid2,time2),(pageid3,time3))...
2.3 结构转换
(pageid1,time2-time1), (pageid2,time3 - time2), ...
3. 对2的结果数据,结构转换
(session, (pageid1,time2-time1), (pageid2,time3 - time2), ...)
==> (pageid1,time2-time1), (pageid2,time3 - time2), ...
4. 分组
(pageid1,Iterator(time2-time1,time2-time1,...),
5. 结构转换
(pageid1,(timeSum/Count))
2.7.4 代码实现
说明:在需求3的基础上,修改PageFlowServiceReview代码逻辑即可,其余代码不需要做任何的改动
2.7.4.1 修改PageFlowServiceReview
package com.atguigu.core.hotcategorytop10review.service
import java.text.SimpleDateFormat
import com.atguigu.core.hotcategorytop10review.bean
import com.atguigu.core.hotcategorytop10review.dao.PageFlowDAOReview
import com.atguigu.summer.framework.core.TService
import com.atguigu.summer.framework.util.EnvUtils
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
/**
* @Description
**
* @author lianzhipeng
* @create 2020-06-11 0:37:41
*/
class PageFlowServiceReview extends TService{
private val pageFlowDAOReview = new PageFlowDAOReview
override def analysis() = {
val UserActionRDD: RDD[bean.UserVisitAction] = pageFlowDAOReview.getUserVisitAction()
// 1. 按session进行分组 (session,Iterator(bean1,bean2...))
val groupByRDD: RDD[(String, Iterable[bean.UserVisitAction])] = UserActionRDD.groupBy(_.session_id)
// 2. 对分组的value进行操作
val sessionPageIdRDD: RDD[(String, List[(String, Long)])] = groupByRDD.mapValues(iter => {
// 2.1 结构转换,根据时间进行升序排序 (pageid1,time1),(pageid2,time2),.....
val dataFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val sortByList: List[(String, Long)] = iter.map(action => {
val action_time: String = action.action_time
val time: Long = dataFormat.parse(action_time).getTime
(action.page_id, time)
}).toList.sortBy(_._2)
// 2.2 拉链数据 ((pageid1,time1),(pageid2,time2)), ((pageid2,time2),(pageid3,time3))...
val zipList: List[((String, Long), (String, Long))] = sortByList.zip(sortByList.tail)
// 2.3 结构转换 (pageid1,time2-time1), (pageid2,time3 - time2), ...
val zipMapList: List[(String, Long)] = zipList.map {
case ((id1, time1), (id2, time2)) => {
(id1, time2 - time1)
}
}
zipMapList
})
//3. 对2的结果数据,结构转换
//(session, (pageid1,time2-time1), (pageid2,time3 - time2), ...)
// ==> (pageid1,time2-time1), (pageid2,time3 - time2), ...
val pageIdTimeRDD: RDD[(String, Long)] = sessionPageIdRDD.map(_._2).flatMap(iter=>iter)
// 4. 分组 (pageid1,Iterator(time2-time1,time2-time1,...),
val pageidTimeRDD: RDD[(String, Iterable[Long])] = pageIdTimeRDD.groupByKey()
// 5. 结构转换 (pageid1,(timeSum/Count))
pageidTimeRDD.foreach{
case(pageID,iter) => {
val count: Int = iter.size
val timeSum: Long = iter.sum
println("页面id:" + pageID + ",访问次数:" + count + ",平均停留时间:" + timeSum/count/1000 + "毫秒")
}
}
}
override def analysis(data: Any): Any = ???
}
2.7.4.5 运行结果
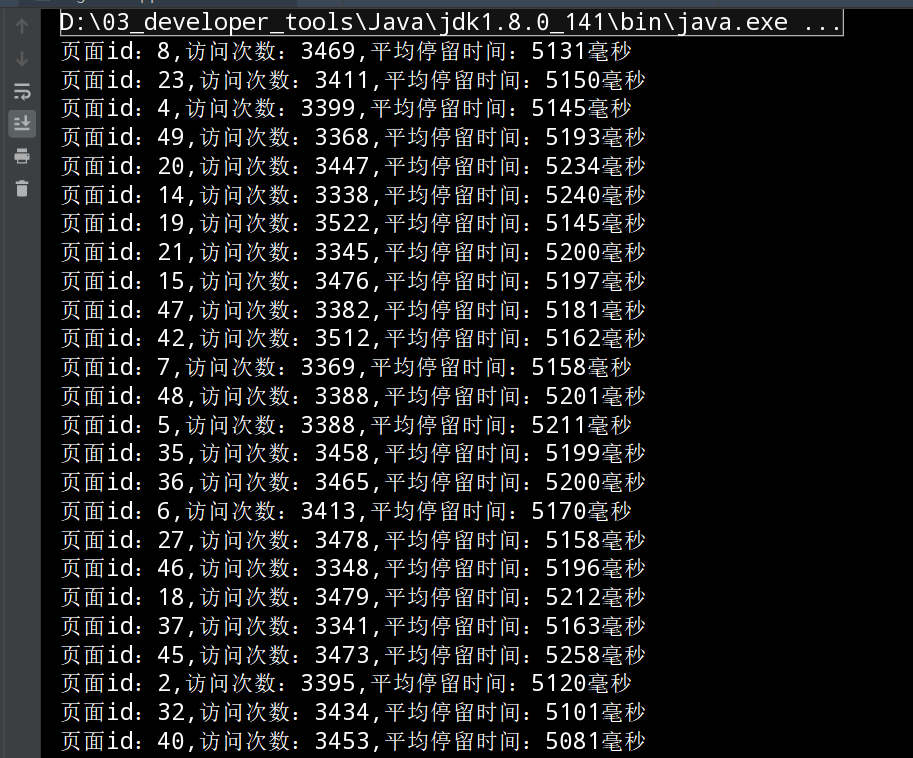
2.7.5 需求4总结
// 时间格式转换成时间戳
val dataFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val action_time: String = action.action_time
val time: Long = dataFormat.parse(action_time).getTime
三 、项目总结
3.1 踩过的坑
-- 总结1:
在写累加器的时候出现如下情况:
1. 在获取遍历累加器的值时,使用了map算子,错误,应该使用foreach,因为map不是行动算子,不会执行遍历的操作
2. 更新add方法时,数据累加出现错误,最后执行结果为0,发现是
bean.clickCount += 1 写成了 bean.clickCount + 1
3. 进行数据累加时,发现通不过,原来的是封装的HotCagetoryBean,属性均是val类型,不可变,需改为var类型
-- 总结2:
1. 在进行数据组合时,分割符和原始数据的分隔符一致,导致后面进行数据切分时,数据产生了丢失。
开始是:"(品类-session,count)"
修正后:"(品类&session,count)"
-- 总结3:
1. 计算转换率的时候算子使用错误,使用map没有结果,后来更换成foreach就可以了,因为map不是行动算子,不会执行遍历的操作。
-- 总结4:
1. 时间格式转换成时间戳,一定不要写错
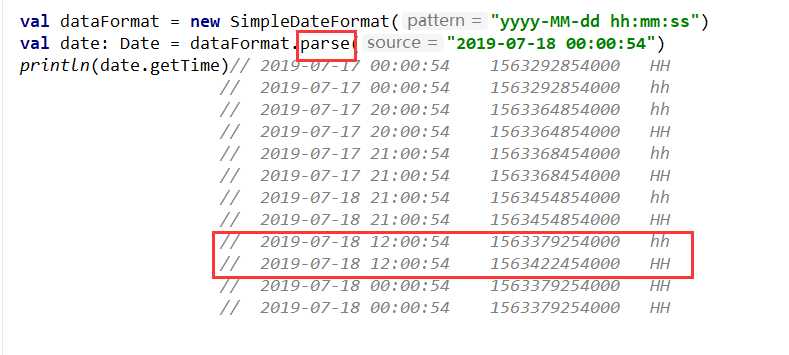
yyyy-MM-dd HH:mm:ss:代表将时间转换为24小时制,例: 2018-06-27 15:24:21
yyyy-MM-dd hh:mm:ss:代表将时间转换为12小时制,例: 2018-06-27 03:24:21
val dataFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val action_time: String = action.action_time
val time: Long = dataFormat.parse(action_time).getTime
3.2 逻辑及优化总结
-- 逻辑部分:
1. 弄清楚数据来源和最终结果数据
2. 梳理好中间各个实现步骤
3. 清楚各个算子之间的作用以及目的
4. 逻辑梳理完成以后,完成代码是很简单的事情
-- 优化
1. 尽量减少使用有shuffle阶段的算子,如果一定需要有,尽量减少shuffle阶段数据的Io
2. 可以考虑使用累加器来减少shuffle
3. 逻辑代码层次拆分,逻辑控制层、逻辑执行层、资源连接层,且所有层共享的数据,放置在线程的共享内存中
4. 原始数据使用样例类进行封装,减少代码的耦合
5. 如果涉及到Driver向每个executor传递数据量大的对象,那么采用广播变量的方式,减少IO
6. 如果涉及到一个变量重复使用,考虑变量的持久化,cache + checkPoint
7. 两个map之间的合并方式一定要学会,在实际开发过程中,使用的场景很多
8. 使用累加器的时候,特别注意,如果算子执行两次,那么结果会累计计算两次
9. 排查错误时,自下而上进行排查,可以打印阶段性计算结果,看看是否是自己预期的结果。
10. 数据一般先进行过滤,再进行计算,减少数据的传输
11. reduceBykey不一定会有shuffle阶段。
ataFormat = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”)
val action_time: String = action.action_time
val time: Long = dataFormat.parse(action_time).getTime
## 三 、项目总结
### 3.1 踩过的坑
```sql
-- 总结1:
在写累加器的时候出现如下情况:
1. 在获取遍历累加器的值时,使用了map算子,错误,应该使用foreach,因为map不是行动算子,不会执行遍历的操作
2. 更新add方法时,数据累加出现错误,最后执行结果为0,发现是
bean.clickCount += 1 写成了 bean.clickCount + 1
3. 进行数据累加时,发现通不过,原来的是封装的HotCagetoryBean,属性均是val类型,不可变,需改为var类型
-- 总结2:
1. 在进行数据组合时,分割符和原始数据的分隔符一致,导致后面进行数据切分时,数据产生了丢失。
开始是:"(品类-session,count)"
修正后:"(品类&session,count)"
-- 总结3:
1. 计算转换率的时候算子使用错误,使用map没有结果,后来更换成foreach就可以了,因为map不是行动算子,不会执行遍历的操作。
-- 总结4:
1. 时间格式转换成时间戳,一定不要写错
yyyy-MM-dd HH:mm:ss:代表将时间转换为24小时制,例: 2018-06-27 15:24:21
yyyy-MM-dd hh:mm:ss:代表将时间转换为12小时制,例: 2018-06-27 03:24:21
val dataFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val action_time: String = action.action_time
val time: Long = dataFormat.parse(action_time).getTime
[外链图片转存中…(img-w5eM1L9f-1681518422090)]
3.2 逻辑及优化总结
-- 逻辑部分:
1. 弄清楚数据来源和最终结果数据
2. 梳理好中间各个实现步骤
3. 清楚各个算子之间的作用以及目的
4. 逻辑梳理完成以后,完成代码是很简单的事情
-- 优化
1. 尽量减少使用有shuffle阶段的算子,如果一定需要有,尽量减少shuffle阶段数据的Io
2. 可以考虑使用累加器来减少shuffle
3. 逻辑代码层次拆分,逻辑控制层、逻辑执行层、资源连接层,且所有层共享的数据,放置在线程的共享内存中
4. 原始数据使用样例类进行封装,减少代码的耦合
5. 如果涉及到Driver向每个executor传递数据量大的对象,那么采用广播变量的方式,减少IO
6. 如果涉及到一个变量重复使用,考虑变量的持久化,cache + checkPoint
7. 两个map之间的合并方式一定要学会,在实际开发过程中,使用的场景很多
8. 使用累加器的时候,特别注意,如果算子执行两次,那么结果会累计计算两次
9. 排查错误时,自下而上进行排查,可以打印阶段性计算结果,看看是否是自己预期的结果。
10. 数据一般先进行过滤,再进行计算,减少数据的传输
11. reduceBykey不一定会有shuffle阶段。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











