







- Overview
cfs调度器被称作是完全公平调度器,那么如何体现公平的呢?是否有绝对的公平呢?本博客主要回答如下的问题:
vruntime的原理是什么?
vruntime如何更新的? - Vtime的原理
Linux抽象出来一个调度实体,在这个实体当中保存了了一个叫vruntime的变量,如下所示:struct sched_entity { /* For load-balancing: */ struct load_weight load; unsigned long runnable_weight; struct rb_node run_node; struct list_head group_node; unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime; u64 nr_migrations; struct sched_statistics statistics; #ifdef CONFIG_FAIR_GROUP_SCHED int depth; struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q; #endif #ifdef CONFIG_SMP /* * Per entity load average tracking. * * Put into separate cache line so it does not * collide with read-mostly values above. */ struct sched_avg avg; #endif };vruntime更新的时间点与位置:
Kernel会在涉及到task时间变化 或者变更cpu的时候,更新vruntime,如下所示:

update_curr的函数如所示:/* * Update the current task's runtime statistics. */ static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_clock_task(rq_of(cfs_rq));//此处取得的是task的clock,关于rq相关的clock,后面研究。 u64 delta_exec; if (unlikely(!curr)) return; delta_exec = now - curr->exec_start; if (unlikely((s64)delta_exec <= 0)) return; curr->exec_start = now;//重新开始计时 schedstat_set(curr->statistics.exec_max, max(delta_exec, curr->statistics.exec_max)); curr->sum_exec_runtime += delta_exec;//计算总运行时间 schedstat_add(cfs_rq->exec_clock, delta_exec); curr->vruntime += calc_delta_fair(delta_exec, curr);//计算vruntime update_min_vruntime(cfs_rq);//更新cfs_rq的最小vruntime if (entity_is_task(curr)) { struct task_struct *curtask = task_of(curr); trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime); cgroup_account_cputime(curtask, delta_exec); account_group_exec_runtime(curtask, delta_exec); } account_cfs_rq_runtime(cfs_rq, delta_exec); }vruntime的计算:
/* * delta /= w */ static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se) { if (unlikely(se->load.weight != NICE_0_LOAD)) //如果权重不是优先级为0的权重,则要根据其权重重新计算。 delta = __calc_delta(delta, NICE_0_LOAD, &se->load); //否则就是真实的runing时间差值。 return delta; }所以,根据上面的公式看上去和load.weight有很大关系,那么Load.weight表示什么呢?
如之前sched_entity中Load的类型为: struct load_weight load;struct load_weight { unsigned long weight; u32 inv_weight; };查询代码,主要是通过如下的函数设置load.weight:
static void set_load_weight(struct task_struct *p, bool update_load) { int prio = p->static_prio - MAX_RT_PRIO;//RT的最大优先级为99,normal的从100开始,此处MAX_RT_PRIO的值为100。 struct load_weight *load = &p->se.load; /* * SCHED_IDLE tasks get minimal weight: */ if (task_has_idle_policy(p)) { load->weight = scale_load(WEIGHT_IDLEPRIO); load->inv_weight = WMULT_IDLEPRIO; p->se.runnable_weight = load->weight; return; } /* * SCHED_OTHER tasks have to update their load when changing their * weight */ if (update_load && p->sched_class == &fair_sched_class) { reweight_task(p, prio); } else { load->weight = scale_load(sched_prio_to_weight[prio]); load->inv_weight = sched_prio_to_wmult[prio]; p->se.runnable_weight = load->weight; } } #ifdef CONFIG_64BIT # define NICE_0_LOAD_SHIFT (SCHED_FIXEDPOINT_SHIFT + SCHED_FIXEDPOINT_SHIFT) # define scale_load(w) ((w) << SCHED_FIXEDPOINT_SHIFT)所以,weight的值其实是根据prio在sched_prio_to_weight查表获得一个值并左移(32位系统不用左移)。这个表的内容如下所示:
/* * Nice levels are multiplicative, with a gentle 10% change for every * nice level changed. I.e. when a CPU-bound task goes from nice 0 to * nice 1, it will get ~10% less CPU time than another CPU-bound task * that remained on nice 0. * * The "10% effect" is relative and cumulative: from _any_ nice level, * if you go up 1 level, it's -10% CPU usage, if you go down 1 level * it's +10% CPU usage. (to achieve that we use a multiplier of 1.25. * If a task goes up by ~10% and another task goes down by ~10% then * the relative distance between them is ~25%.) */ const int sched_prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, };根据英文注释:这个表中的每个值都是前一个值的80%,以nice为0(即prio的值为120)时候的值为1024。
nice的值区间为[-20,20],那么sched_prio_to_weight对应[-20,20]每一个Nice的weight值。这个数组的值近似满足等比数列。
可以用下面的公式表示: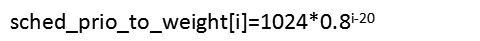
其中: load->inv_weight = sched_prio_to_wmult[prio];中的sched_prio_to_wmult如下所示:/* * Inverse (2^32/x) values of the sched_prio_to_weight[] array, precalculated. * * In cases where the weight does not change often, we can use the * precalculated inverse to speed up arithmetics by turning divisions * into multiplications: */ const u32 sched_prio_to_wmult[40] = { /* -20 */ 48388, 59856, 76040, 92818, 118348, /* -15 */ 147320, 184698, 229616, 287308, 360437, /* -10 */ 449829, 563644, 704093, 875809, 1099582, /* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326, /* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587, /* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126, /* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717, /* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153, };根据注释,每个元素的值公式如下:
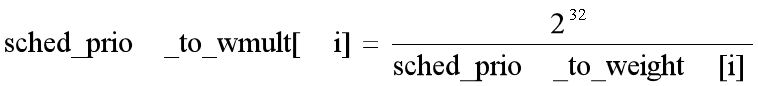
接下来继续计算delta_time:/* * delta_exec * weight / lw.weight * OR * (delta_exec * (weight * lw->inv_weight)) >> WMULT_SHIFT * * Either weight := NICE_0_LOAD and lw \e sched_prio_to_wmult[], in which case * we're guaranteed shift stays positive because inv_weight is guaranteed to * fit 32 bits, and NICE_0_LOAD gives another 10 bits; therefore shift >= 22. * * Or, weight =< lw.weight (because lw.weight is the runqueue weight), thus * weight/lw.weight <= 1, and therefore our shift will also be positive. */ static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw) { u64 fact = scale_load_down(weight); //因为在设定weight的时候对于64位系统,向左移了10位,这里再移回来,这样做的目的,看注释是为了增加分辨率。 int shift = WMULT_SHIFT; __update_inv_weight(lw); if (unlikely(fact >> 32)) { while (fact >> 32) { fact >>= 1; shift--; } } /* hint to use a 32x32->64 mul */ fact = (u64)(u32)fact * lw->inv_weight; while (fact >> 32) { fact >>= 1; shift--; } return mul_u64_u32_shr(delta_exec, fact, shift); }上面的函数对应的公式为:
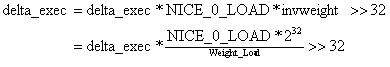
所以,当优先级为120的时候,dealta_exec不用打折。而对于其他优先级都会打折或者放大。
如果优先级越大那么其nice值越小,对应的weight_load的值越大,则计算出的时间比实际执行时间要少
如果优先级越小,那么其nice值越大,对应的weight_load的值越小,则计算出的时间比较实际执行时间要多。
如果按照vtime进行公平调度的话,那么优先级越大,则实际分配的时间越多。
如下图所示:
时间片计算
/*
* Preempt the current task with a newly woken task if needed:
*/
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}















 1845
1845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









