







一、主要内容
1、学习什么是hash表,运用hash表解决问题。
2、了解自动数组(根据存储内容自动调整大小),数组的排序。
3、利用hash表统计经典巨著《红楼梦》中所有汉字的使用次数。
4、利用数组,对所有汉字按使用次数进行排序。
二、要到的基础库
本练习要到Glib库,Glib是在C语言标准库的基础上实现的一套跨平台的功能强大的通用函数库。
三、编程环境
编程环境为Cygwin,安装方法见https://blog.csdn.net/sudsheng/article/details/88909066
四、实现步骤
1、识别汉字
汉字通常采用GBK编码,GBK编码标准如下(https://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php)
GBK编码范围:8140-FEFE,汉字编码范围见第二节:码位分配及顺序。
GBK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准。GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年12月15日正式发布,这一版的GBK规范为1.0版。
一、字汇
GBK 规范收录了 ISO 10646.1 中的全部 CJK 汉字和符号,并有所补充。具体包括:
1. GB 2312 中的全部汉字、非汉字符号。
2. GB 13000.1 中的其他 CJK 汉字。以上合计 20902 个 GB 化汉字。
3. 《简化字总表》中未收入 GB 13000.1 的 52 个汉字。
4. 《康熙字典》及《辞海》中未收入 GB 13000.1 的 28 个部首及重要构件。
5. 13 个汉字结构符。
6. BIG-5 中未被 GB 2312 收入、但存在于 GB 13000.1 中的 139 个图形符号。
7. GB 12345 增补的 6 个拼音符号。
8. 汉字“〇”。
9. GB 12345 增补的 19 个竖排标点符号(GB 12345 较 GB 2312 增补竖排标点符号 29 个,其中 10 个未被 GB 13000.1 收入,故 GBK 亦不收)。
10. 从 GB 13000.1 的 CJK 兼容区挑选出的 21 个汉字。
11. GB 13000.1 收入的 31 个 IBM OS/2 专用符号。
12.未录入《新华字典》上的一些字,如“韡”的简体。
二、码位分配及顺序
GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。
全部编码分为三大部分:
1. 汉字区。包括:
a. GB 2312 汉字区。即 GBK/2: B0A1-F7FE。收录 GB 2312 汉字 6763 个,按原顺序排列。
b. GB 13000.1 扩充汉字区。包括:
(1) GBK/3: 8140-A0FE。收录 GB 13000.1 中的 CJK 汉字 6080 个。
(2) GBK/4: AA40-FEA0。收录 CJK 汉字和增补的汉字 8160 个。CJK 汉字在前,按 UCS 代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列。
(3) 汉字“〇”安排在图形符号区GBK/5:A996。
2. 图形符号区。包括:
a. GB 2312 非汉字符号区。即 GBK/1: A1A1-A9FE。其中除 GB 2312 的符号外,还有 10 个小写罗马数字和 GB 12345 增补的符号。计符号 717 个。
b. GB 13000.1 扩充非汉字区。即 GBK/5: A840-A9A0。BIG-5 非汉字符号、结构符和“〇”排列在此区。计符号 166 个。
3. 用户自定义区:分为(1)(2)(3)三个小区。
(1) AAA1-AFFE,码位 564 个。
(2) F8A1-FEFE,码位 658 个。
(3) A140-A7A0,码位 672 个。
第(3)区尽管对用户开放,但限制使用,因为不排除未来在此区域增补新字符的可能性。
三、字形
GBK 对字形作了如下的规定:
1. 原则上与 GB 13000.1 G列(即源自中国大陆法定标准的汉字)下的字形/笔形保持一致。
2. 在 CJK 汉字认同规则的总框架内,对所有的 GBK 编码汉字实施“无重码正形”(“GB 化”);即在不造成重码的前提下,尽量采用中国新字形。
3. 对于超出 CJK 汉字认同规则的、或认同规则尚未明确规定的汉字,在 GBK 码位上暂安放旧字形。这样,在许多情况下 GBK 收入了同一汉字的新旧两种字形。
4. 非汉字符号的字形,凡 GB 2312 已经包括的,与 GB 2312 保持一致;超出 GB 2312 的部分,与 GB 13000.1 保持一致。
5. 带声调的拼音字母取半角形式。
由以上红色字体可知,每个汉字占两个字节,取值范围为
B0A1-F7FE
8140-A0FE
AA40-FEA0
第一个字节按有符号数处理时为负数。
2、选择合适的容器存放汉字以及其出现的次数
统计过程如下:
读取一个汉字 —> 在容器中查找该汉字 —> 如果查找到该汉字则将该汉字的计数加一;如果没有查找到则将该汉字新加入容器并将计数设置为1
整个过程中,在容器中查找汉字将是最费时的部分,所以要选择查找速度快的容器,hash表无疑是最合适的。
3、对汉字按次数进行排序
hash表中存的汉字是无序的并且不能排序,如果需要按汉字使用的次数进行排序,则需要另一种容器数组或者链表。对于我们的问题数组和链表都可以,但是数组相对来讲需要的内存更少并且可以预先分配内存,更为合适。
汉字和其次数已经存在hash表中,数组只需要保存指针即可。
4、代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
#include <dirent.h>
#include <glib.h>
typedef struct _WordTimes WordTimes;
struct _WordTimes
{
char word[3];
int times;
};
static int cmp_func(gconstpointer a, gconstpointer b)
{
return (*(WordTimes **)b)->times - (*(WordTimes **)a)->times;
}
static void insert_array(gpointer key, gpointer value, gpointer user_data)
{
GPtrArray ** array = (GPtrArray **)user_data;
WordTimes * word_times = (WordTimes *)key;
g_ptr_array_add(*array, word_times);
}
static void free_word_times(gpointer data)
{
g_slice_free(WordTimes, data);
}
static void print_word_times(gpointer data)
{
printf("%s : %d\n", ((WordTimes *)data)->word, ((WordTimes *)data)->times);
}
int main(int argc, char* argv[])
{
GHashTable * h;
FILE * fp;
char word[4] = {0};
char buf[4096] = {0};
WordTimes * word_times = NULL;
unsigned short u16_word;
GPtrArray * array = NULL;
int i = 0;
fp = fopen(argv[1], "r");
if (NULL == fp)
{
printf("文件%s不存在!\n", argv[1]);
}
h = g_hash_table_new_full ((GHashFunc)g_str_hash, (GEqualFunc)g_str_equal, free_word_times, NULL);
while (NULL != fgets(buf, sizeof(buf), fp))
{
for (i = 0; buf[i] != 0; i ++)
{
if (buf[i] < 0)
{
word[0] = buf[i++];
word[1] = buf[i];
word[2] = 0;
*(char *)&u16_word = word[1];
*((char *)&u16_word + 1)= word[0];
if (((u16_word >= 0xB0A1) && (u16_word <= 0xF7FE))
|| ((u16_word >= 0x8140) && (u16_word <= 0xA0FE))
|| ((u16_word >= 0xAA40) && (u16_word <= 0xFEA0)))
{
if (g_hash_table_lookup_extended(h, word, (gpointer *)&word_times, NULL))
{
(word_times->times) ++;
}
else
{
word_times = g_slice_new(WordTimes);
word_times->times = 1;
strcpy(word_times->word, word);
g_hash_table_insert (h, word_times, NULL);
}
}
}
}
}
fclose(fp);
array = g_ptr_array_sized_new(4096);
g_hash_table_foreach(h, insert_array, &array);
g_ptr_array_sort(array, cmp_func);
for (i = 0; i < array->len; i++)
{
print_word_times(g_ptr_array_index(array, i));
}
g_ptr_array_free(array, 0);
g_hash_table_destroy(h);
return 0;
}
5、运行结果

前20个 后20个
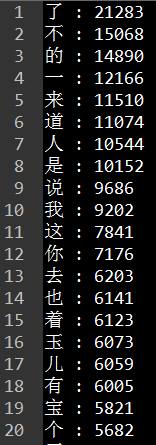
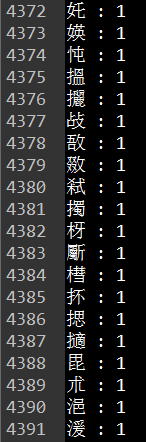

















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









