







一、前置工作
- 需要安装MySQL并启动服务,本文MySQL版本为5.7
- 需要安装Hadoop并启动服务,本文基于Hadoop伪分布式环境
- 需要安装sqoop,本文sqoop版本为1.4.7
二、需求说明
- 需要利用sqoop的import命令将MySQL中表的数据导入到hdfs中
三、测试数据
- MySQL中表t_test_user:
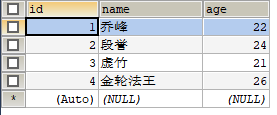
创表语句:CREATE TABLE `t_test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '姓名', `age` tinyint(4) NOT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
四、案例说明
-
案例一:将t_test_user表数据导入到hdfs中,默认方式
命令如下:
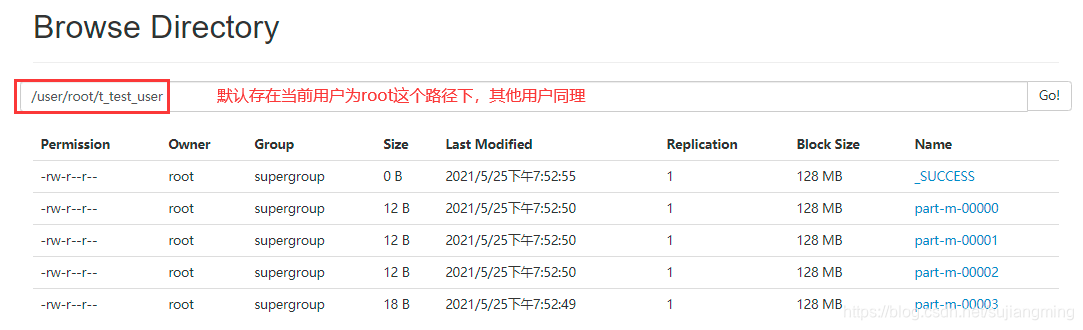
sqoop import \ --connect jdbc:mysql://192.168.76.1:3306/itcollege \ --username root \ --password 123456 \ --table t_test_user注意:不指定
--target-dir,默认使用表的名称作为在HDFS上存储的目录名称,默认的存储路径为当前sqoop安装用户目录下,如下图所示:
默认的
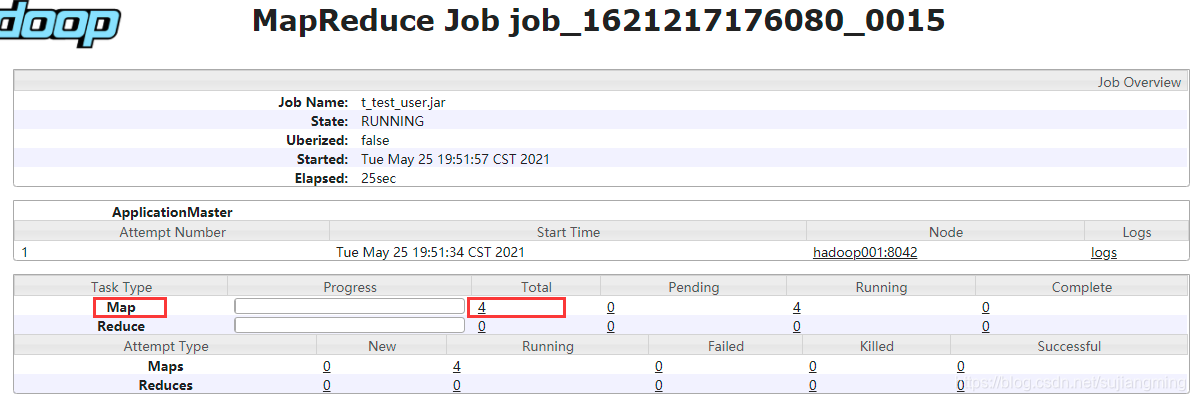
map task数量为4,如下图所示:
-
案例二:将t_test_user表数据导入到hdfs中,指定
--target-dir方式
命令如下:sqoop import \ --connect jdbc:mysql://192.168.76.1:3306/itcollege \ --username root \ --password 123456 \ --table t_test_user \ --target-dir /mysql/user/结果如下图:

-
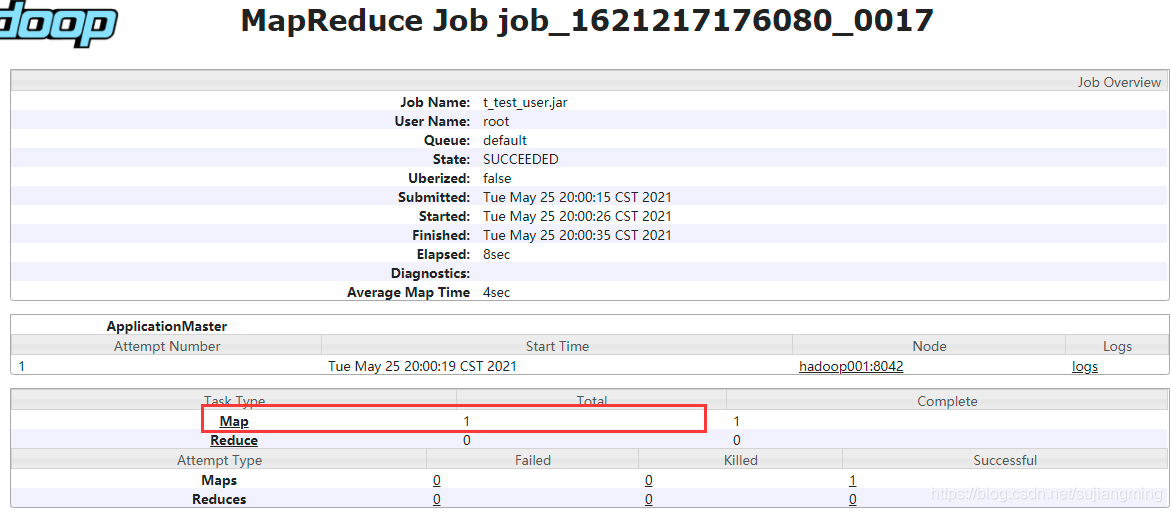
案例三: 通过
-m指定map task数量将t_test_user表数据导入到hdfs中sqoop import \ --connect jdbc:mysql://192.168.76.1:3306/itcollege \ --username root \ --password 123456 \ --table t_test_user \ --target-dir /mysql/user01/ \ -m 1注意: sqoop中的import命令默认会启动多个map task(4个)来加速导入数据到hdfs中,但是我们也可以指定map task个数,即-m 1 代表指定一个map task。如下图:
-
案例四: 通过
--split-by id指定sqoop按照id进行分割,将t_test_user表数据导入到hdfs中sqoop import \ --connect jdbc:mysql://192.168.76.1:3306/itcollege \ --username root \ --password 123456 \ --split-by id \ --table t_test_user \ --target-dir /mysql/user02/注意: --split-by id 指定sqoop按照id进行分割,id为数值类型的
-
案例五: 通过
--columns id,name指定导入当前表的两列数据到hdfs上sqoop import \ --connect jdbc:mysql://192.168.76.1:3306/itcollege \ --username root \ --password 123456 \ --split-by id \ --columns id,name \ --table t_test_user \ --target-dir /mysql/user03/注意: --columns id,name 指定导入当前表的两列数据到hdfs上
















 2029
2029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











