







Spark Standalone HA(高可用)模式
一、HA架构说明
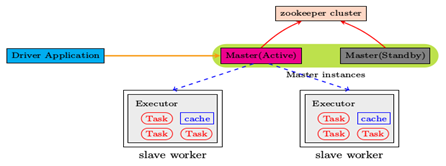
二、主机规划

| 主节点 | 从节点 |
|---|---|
| hadoop002,hadoop005 | hadoop003,hadoop004 |
| Zookeeper |
|---|
| hadoop002 ,hadoop003,hadoop004 |
三、Zookeeper的安装
四、Spark的安装
-
安装部署,请参考Spark Standalone集群安装及测试案例
注意:这里是4台虚拟机 -
Spark高可用配置,只需要修改spark-env.sh,具体需要修改的内容如下表所示:

在hadoop002上编辑spark-env.sh,将内容替换成如下内容即可:export JAVA_HOME=/training/jdk1.8.0_171 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop002,hadoop003,hadoop004 -Dspark.deploy.zookeeper.dir=/spark" #history 配置历史服务 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=/training/spark-2.4.8-bin-hadoop2.7/history"注意:
需要将spark-env.sh分发到其他节点中,即分发到hadoop003,hadoop004和hadoop005
五、运行测试
- 在Hadoop002上启动spark集群,进入spark的安装目录下,执行:
sbin/start-all.sh - 在Hadoop005上启动Master,进入spark的安装目录下,执行:
sbin/start-master.sh - 在浏览器中查看hadoop002上的spark提供的web界面,输入:
hadoop002:8080,如下所示:

- 在浏览器中查看hadoop005上的spark提供的web界面,输入:
hadoop005:8080,如下所示:

- 高可用测试
1)将hadoop002上的master杀掉:kill + 进程号或者使用stop-master.sh命令关掉
2)在浏览器上的输入:hadoop005:8080,清楚换成并刷新页面,等待片刻之后会看到如下图所示:

至此,spark的master完成了切换,实现了高可用的目的。

















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











