







下面这个是我做到思维导图,只包含了我们学过的知识,其实学的挺少的。之后还是得要好好学习一哈!


这个题目主要就是第二问我当时做错了。按照我的想法,这题就是简单的连接查询而已,但是重要的是这里不仅仅涉及到查询,还有更新操作。但是根据更新操作的语法来看,他并不支持多个表,所以我一开始写出了这样的SQL,被sql server报错了。
update tb_R
set tb_R.B=‘b4’
where tb_R.A=tb_S.A and tb_S.C=40;
然后我又尝试写出这样的SQL,也是错误的
update tb_R,tb_S
set tb_R.B=‘b4’
where tb_R.A=tb_S.A and tb_S.C=40;
最后是答案上的方法才是可以的:
update tb_R
set B=‘b4’
where A in(
select A
from tb_S
where C=40)
这个例子告诉我们,虽然书本上说了现在的DBMS对嵌套查询做到不够优化,要我们能使用连接查询就尽量使用。但是,针对于更新操作,而且还是涉及到多张表的,只能使用In的嵌套查询
查询至少选修了1001号老师教的所有课程的学生的学号。
select distinct Sno
from tb_SC SC_X
where not exists(
select *
from tb_Course,tb_SC SC_Y
where tb_Course.Cno=SC_Y.Cno and tb_Course.Tno='1001'
and not exists(
select *
from tb_SC SC_Z
where SC_Z.Cno=SC_Y.Cno
and SC_Z.Sno=SC_X.Sno
)
)

这题的答案选择A。所以说捏,自己还是有很多没有复习到位的地方。
当破坏参照完整性规则的时候,有以下三种策略可以处理。第一:拒绝(NO ACTION)执行;第二:级联(CASCADE)执行;第三:设置为空值。最后一个就得要求参照表(SC)是可以将外键设置为NULL的
事务是用户定义的一个数据库操作序列,这些序列要么不做,要么全都做,是一个不可分割的基本单位。事务具有原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持续性(Durability)四个特性。


上面的一个是题目,一个是答案。不要纠结为什么一个是第三题,而另一个是第二题。
这个题目并不难。但是我就是没有看出来这个”组装“会有什么属性。看了答案,的确也没有什么特殊的属性。但是通过这个题目我知道了,以后凡是遇到m:n的关系,这个联系肯定会产生属性的。如果题目没有明确说它的属性,那么它的属性就是那两个实体的主码。这个一定德记得,至少通过我现在的做的题目要来看,就是这样的套路。


这个是一个很好的题目,我就是想告诉自己。在使用关系代数在做自然连接处理的时候,就先把条件给对应的表,然后把筛选出来的表去进行自然连接处理。当然,你先进行自然连接处理,后筛选条件也是可以的。只不过我看答案上都是这么写的。
但是记得前面说的都是 ‘选择’ 关系,遇到 ‘投影’ 关系的时候,是先投影还是先连接是由区别的
在数据库中存贮的是:数据与数据之间的联系。因为存贮的都是一张一张表


对于上面的…数据库的名字也得记得。欸,上课老师都没有说,怎么考试就有了!
数据冗余可能导致的问题有存贮空间的浪费和修改麻烦和潜在的数据不一致性
这个题目还可以换一种方法问你:在数据库中,产生数据的不一致性的根本原因是:数据冗余
从外部视图到子模式的数据结构的转换是由应用程序实现;模式与子模式之间的映象是由DBMS实现;存储模式与数据物理组织之间的映象是由操作系统的存取方式实现。

首先从题目就可以知道一个函数依赖:A->B;所以根据函数依赖的定义我们可以知道,一个A仅仅只有一个B可以与之对应,但是多个B可以与一个A对应。
这里来阐述一哈函数依赖的定义:若对于R(U)的任意一个可能的关系r,r中不可能存在有两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数确定Y或Y函数依赖于X
从定义的反面来看,定义并没有规定如果在X的属性值就不等了会怎么样,也就是说,如果在X上的属性值就不相等的话,那么不管Y的属性值是否相等,X都可以函数确定Y。
最后回到题目:假如X,Y上的属性值分别为(a b),(c,d),(e,f),(g,d);我给的这个关系X->Y,因为在X上的属性值就没有一个相等的。但是Y不能确定X。因为存在Y=d的时候,X=a/g。不满足函数依赖的定义。所以,X的c只有一个d与之对应,但是Y的d却有c,g与之对应。所以X与Y的对应关系是n:1。这个也说明了,在E-R中我们说的当实体之间的关系是1:n的时候,n端为主码。就像这里,X->Y,n端也的确是主码。

因为表中不能再有表,所以表中的数据一定的是最小的数据项。所以再在这里应该是不能要部门成员。因为部门成员包裹部门总经理。
没有非主属性起码就是3NF了。这个换一个问法就是:全部是主属性至少是几NF。因为2NF,3NF都是与非主属性有关的。至于能不能达到BCNF,那还得看左边是不是全部都包含所有候选码(如果候选码有多个,包含一种就好)。举个是3NF,但是不是BCNF的例子。也就是书本上的例子:R(S,J,P),F={(S,J)->T,(S,T)->J,T->J},所以候选码为(S,J),(S,T)。但是,T->J左边没有包含所有的候选码(要么是SJ,要么是ST)。但是T也是主属性,所以这个也不是传递函数依赖,因为J也是主属性,也不是部分函数依赖。
二元关系模式的起码最高可达4NF。
关系种的候选码都是单属性构成的,则最起码就是2NF了。

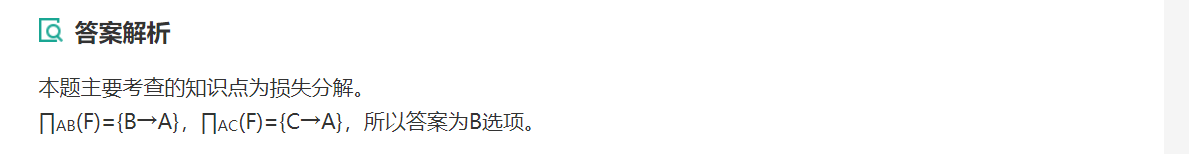
这个题目我就想提醒自己一个问题,就是函数依赖并不是一定得全部都是题目所给的函数依赖,还有可能是函数中可以推导出来的函数依赖关系。就像这里,他分解为了AB,但是直观上看到AB并没有函数依赖。所以,这里AB的函数依赖还必须得通过已知的函数依赖推导出来。这个可以解决你在分解为BCNF保持无损连接的时候的困惑。
还有一个顺便提一哈,还有的分解可能会导致没有依赖出现,也就是它的依赖是空集。也就输说,可能推导出来后在原来的函数依赖中完全没有依赖可以证明出这个。

这个题目我在DBMS上测试过了,的确就是这样子。如果没有共同的属性的话,就是做的笛卡尔集。其实换一个角度来想想,我们每一次做的这样的SQL语句:select Sno from SC,Stundet where SC.Sno=Stuednt.Sno不就是先让SC和Student做一下笛卡尔集然后通过条件筛选出SC.Sno=Student.Sno的情况。
数据在数据库中的特点:永久存贮,可共享,有组织
DNMS的功能:数据定义功能,数据组织,存贮,管理功能,数据操纵功能,数据库的事务管理和运行管理,数据库的建立和维护功能,其他功能。
数据库系统的特点:数据结构化(这个也是数据库系统和文件系统的本质区别),数据冗余度低,易扩展,共享性高,数据独立性高,数据统一由DBMS管理
函数依赖的个数,事务串行执行的个数计算方式是不同的。下面给出了计算方法

SQL语句!来了,老弟
关于教学数据库的关系模式如下:
S(S#,SNAME,AGE,SEX) SC(S#,C#,GRADE) C(C#,CNAME,TEACHER)
其中,S表示学生,它的各属性依次为学号,姓名年龄和性别;SC表示成绩它的各属性依次为学号,课程号和分数;C表示课程, 它的各属性依次为课程号,课程名和任课教师
试用SQL语句完成下列查询
- 检索至少选修王老师所授课程中一门课程的女学生姓名
- 检索张同学不学的课程的课程号
- 检索至少选修两门课程的学生学号
- 检索全部学生都选修的课程的课程号与课程名
- 检索选修课程至少包含王老师所授全部课程的学生学号
1.
SELECT DISTINCT SNAME
FROM S, SC, C
WHERE S.S#=SC.S# AND SC.C#=C.C# AND SEX=‘女’
AND TEACHER='王'
注意上面有一个distinct
2.
SELECT C#
FROM C
WHERE C# not in
(SELECT *
FROM S, SC
WHERE S.S#=SC.S# AND SC.C#=C.C# AND SNAME=‘张’)
3.
select Sno
from tb_SC
group by Sno
having COUNT(*)>=2;
4.
SELECT C#, CNAME
FROM C
WHERE NOT EXISTS
(SELECT *
FROM S
WHERE NOT EXISTS
(SELECT *
FROM SC
WHERE S#=S.S# AND C#=C.C# )
5.
SELECT DISTINCT S#
FROM SC X
WHERE NOT EXISTS
(SELECT *
FROM C
WHERE TEACHER=‘王’AND NOT EXISTS
(SELECT *
FROM SC Y
WHERE Y..S#=X.S# AND Y.C#=C.C#)

其实这个题目我不是第一次碰到了,之前也说实话做错了。这个原因在于老师和书本上明明说实体之间的关系只有一对一,一对多,多对多。我记得我们上课说有没有多对一的关系,他说,多对一和一对多不是一个意思吗?是的,我觉得这个题目上面表达的是部门与职员是一对多的关系,但是最后问的是职员和部门的关系,那么就是多对一了。
然后我发现了一个新的解决这个题目的方法,直接画一个图:
从这个图就可以看出来是:职员—>部门号(可以通过函数依赖的定义推出)。从这个图不就看出来了n个职员才对应一个部门号(张三,李四都对应1001)。其实我就想说这个和E-R图上的1:N时是N端关系作为主码是一个道理。所有的东西都是可以相互佐证的。


其实这个题目考察的就是 空值 的处理。
1.where和having子句只有选择条件问TRUE才可以被选中
2.空值参与的逻辑运算(原来只有TRUE和FALSE),现在还有UNKNOWN。具体的变化在书本120页有
3.还有,只有聚集函数COUNT(*)会处理空值,其他的都不会处理空值,包括COUNT(Sno)。


层次模型是一颗有向树,能够够表达1:1和1:n的关系。这个也是显然的,因为当一个父节点仅仅只有一个孩子节点的时候,就是1:1,如果有多个孩子就是1:n。但是,一个子节点最多一个父节点,所以,无法表达m:n的关系。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









