







一、图像分类概述
本模块是用在图像内容识别的部分,图像分类是利用计算机对图像进行定量分析,把图像中的每个像元或区域划归为若干个类别中的一种,以代替人工视觉判读的技术。从目视角度来说,对图像进行提高对比度、增加视觉维数、进行空间滤波或变换等处理的目的就是使人们能够凭借知识和经验,根据图像亮度、色调、位置、纹理和结构等特征,准确地对图像景物类型或目标做出正确的判读和解释。
特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。
二、本模块完成的主要功能
该模块作用是先对一些已经归类好的图片作为输入,再对一些未知类别的图片进行预测分类。本模块在该项目中可以分出二维码、logo、以及文字 。例如一给定图像,检测并读取其中所有的条码、logo、文字,即使他们处于任意的位置及角度,如果图像中可能有任意数量及格式的条码、logo和文字,输出所有的条码、logo和文字(1个或多个)。
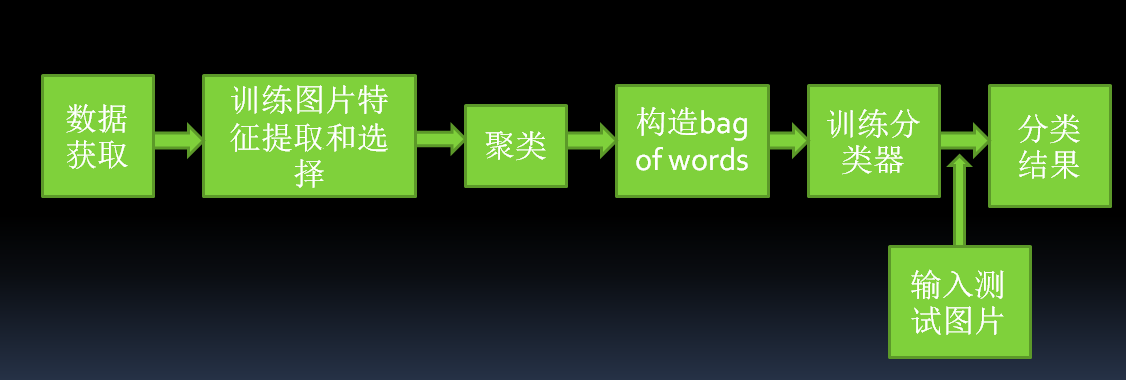
三、svm图像分类的基本流程
- 数据获取
比如摄像机或视频头的输出,通过采样获得数据,也可以是一般的统计数据集,其中的数据以向量或矩阵形式表示,或者是已经准备好的待检测的图片 - 训练图片特征提取和选择
特征提取是指从对象本身获取各种对于分类有用的度量或属性。特征选择是指如何从描述对象的多种特征中找出那些对于分类最有效的特征。特征提取我们用到了surf算法。Surf具有比sift快的检测速度。
对某一类模式的识别,其关键在于对模式特征的描述以及如何去提取这些特征。征描述直接影响到特征提取以及特征向量库的建立,并影响到最后分类识图像的特征提取和分类别精度的高低 从理论上讲,个体的特征是唯一的,这是因为不存在完全相同的两个个体。但是由于客观条件限制的存在,往往使得选取的特征并不是描述个体的特征全集,而只是特征的一个子集。因此,确定物体的本质特征是识别任务成功的关键。为了提高特征提取时计算的鲁棒性,往往又要求用尽可能少的特征来描述物体,这使得在实际应用中特征描述的不完全性是不可避免的。 - 将这些feature聚成n类。这n类中的每一类就相当于是图片的“单词”,所有的n个类别构成“词汇表”。我的实现中n取1000,如果训练集很大,应增大取值。
- 对训练集中的图片构造bag of words,就是将所有训练图片中的feature归到不同的类中,然后统计每一类的feature的频率。这相当于统计一个文本中每一个单词出现的频率。
- 分类器的设计(也就是训练分类器)
利用样本数据来确定分类器的过程称为分类器设计。训练一个多类分类器,将每张图片的bag of words作为feature vector,将该张图片的类别作为label。支持向量机(Support Vector Machines,SVM)应用发热典型流程是首先提取图形的局部特征所形成的特征单词的直方图来作为特征,最后被通过SVM进行训练得到模型。
在图像分类中用到了一种模型叫做BOW (bag of words) 模型。Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
最后通过训练好的模型,再次读取未经分类的图片,就可以对其分类。
流程图如图所示:
四、所用到的技术方法
-
特征提取算法surf
有关surf算法的介绍网上有很多,在这里我就不一一介绍,大家也可以参考下面的文章:http://blog.csdn.net/yujiflying/article/details/8203511 -
聚类算法:Kmeans算法
k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
该算法流程首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 -
Bag of words(BOW)模型
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词 是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
现在Computer Vision中的Bag of words来表示图像的特征描述也是很流行的。大体思想是这样的,假设有5类图像,每一类中有10幅图像,这样首先对每一幅图像划分成patch(可以是刚性分割也可以是像Surf基于关键点检测的),这样,每一个图像就由很多个patch表示,每一个patch用一个特征向量来表示,咱就假设用SURF表示的,一幅图像可能会有成百上千个patch,每一个patch特征向量的维数128。
接下来就要进行构建Bag of words模型了,假设Dictionary词典的Size为1000,即有1000个词。那么咱们可以用K-means算法对所有的patch进行聚类,k=1000,我们知道,等k-means收敛时,我们也得到了每一个cluster最后的质心,那么这1000个质心(维数128)就是词典里的1000个词了,词典构建完毕。
对于bag of words 和K-means算法这一篇文章也挺容易理解的http://www.cnblogs.com/v-July-v/archive/2011/06/20/2091170.html -
svm分类器
支持向量机 (SVM) 是一个类分类器,正式的定义是一个能够将不同类样本在样本空间分隔的超平面。 换句话说,给定一些标记(label)好的训练样本 (监督式学习), SVM算法输出一个最优化的分隔超平面(分类面)。具体可以参考文章:http://blog.csdn.net/sunanger_wang/article/details/7887218
五、算法的分析
SURT采用henssian矩阵获取图像局部最值还是十分稳定的,但是在求主方向阶段太过于依赖局部区域像素的梯度方向,有可能使得找到的主方向不准确,后面的特征向量提取以及匹配都严重依赖于主方向,即使不大偏差角度也可以造成后面特征匹配的放大误差,从而匹配不成功;另外图像金字塔的层取得不足够紧密也会使得尺度有误差,后面的特征向量提取同样依赖相应的尺度,发明者在这个问题上的折中解决方法是取适量的层然后进行插值。
Bag of words方法没有考虑特征点的相对位置,而每类物体大都有自己特定的结构,这方面的信息没有利用起来。用上面一贯的类比,就好像搜索引擎只使用了单词频率,而没有考虑句子一样,没有结构的分析。
SVM有两个不足:
(1) SVM算法对大规模训练样本难以实施
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
图像分类的理论就讲解到这里,对于这个图像分类的代码的讲解请参考下一篇文章。














 9304
9304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









