






当一个warp中的不同线程访问一个bank中的不同的字地址时,就会发生bank冲突。
如果没有bank冲突的话,共享内存的访存速度将会非常的快,大约比全局内存的访问延迟低100多倍,但是速度没有寄存器快。然而,如果在使用共享内存时发生了bank冲突的话,性能将会降低很多很多。在最坏的情况下,即一个warp中的所有线程访问了相同bank的32个不同字地址的话,那么这32个访问操作将会全部被序列化,大大降低了内存带宽。
NOTE:不同warp中的线程之间不存在什么bank冲突。
共享内存的地址映射方式
要解决bank冲突,首先我们要了解一下共享内存的地址映射方式。
在共享内存中,连续的32-bits字被分配到连续的32个bank中,这就像电影院的座位一样:一列的座位就相当于一个bank,所以每行有32个座位,在每个座位上可以“坐”一个32-bits的数据(或者多个小于32-bits的数据,如4个char型的数据,2个short型的数据);而正常情况下,我们是按照先坐完一行再坐下一行的顺序来坐座位的,在shared memory中地址映射的方式也是这样的。下图中内存地址是按照箭头的方向依次映射的:
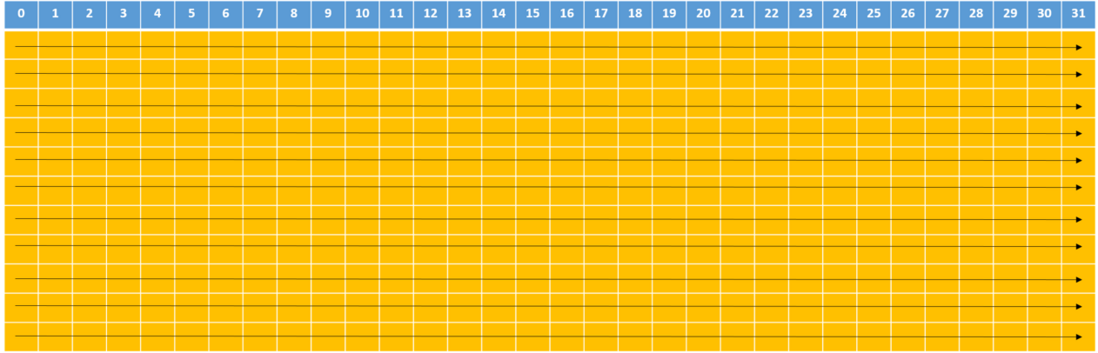
上图中数字为bank编号。这样的话,如果你将申请一个共享内存数组(假设是int类型)的话,那么你的每个元素所对应的bank编号就是地址偏移量(也就是数组下标)对32取余所得的结果,比如大小为1024的一维数组myShMem:
-
myShMem[4]: 对应的bank id为#4 (相应的行偏移量为0)
-
myShMem[31]: 对应的bank id为#31 (相应的行偏移量为0)
-
myShMem[50]: 对应的bank id为#18 (相应的行偏移量为1)
-
myShMem[128]: 对应的bank id为#0 (相应的行偏移量为4)
-
myShMem[178]: 对应的bank id为#18 (相应的行偏移量为5)















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









