






学习总结——faster rcnn
网络总体概述
faster rcnn是经典的两阶段目标检测模型,它分为两部分训练:
1.第一部分是训练RPN,得到候选框;
2.第二部分是训练faster rcnn,对候选框中的物体分类、修正RPN生成的候选框。

conv layers
conv layers可以采用经典的卷积神经网络来提取图片特征,如VGG、ResNet等,Faster rcnn使用网络模型在ImageNet数据集上训练的权重,初始化卷积层参数。
RPN(Region Proposal Network)
Faster RCNN中的anchors是人为设定,总共有9种不同的anchors。RPN主要有两个任务:
- 分类:判断预设的anchor(候选框)里是否含有物体,并抛弃不含有物体的候选框;(注意:特征图上的每一个像素点都有9种候选框,每个像素点只能预测一个类别)
- 对预设的anchor进行修正。

由此可见,RPN分为两个部分来完成任务,先采用3*3卷积,将特征窗口的图调整为256维:
- 图上面的路用于分类,使用1
*1*256的卷积核,从而减少通道数,第一条路得到结果是M*N*18,为什么是18?因为要对每个anchor进行二分类(判断是前景或者背景),所以2*9;这里使用softmax进行分类,我觉得也可以用sigmoid函数; - 图下面的路用于anchor修正,使用1
*1*256的卷积核,从而减少通道数,第一条路得到结果是M*N*36,为什么是36?因为一个anchor使用(x,y,w,h)表示,其中x、y表示anchor的中心点坐标,一个像素点有9个anchors,所以修正一个像素点的anchors需要4*9个参数,注意:这里卷积得到的坐标,是偏移量,相对于直接得到anchor坐标(数量级相对比较大),这样可以加快运算速度,好训练。
偏移量计算方法:
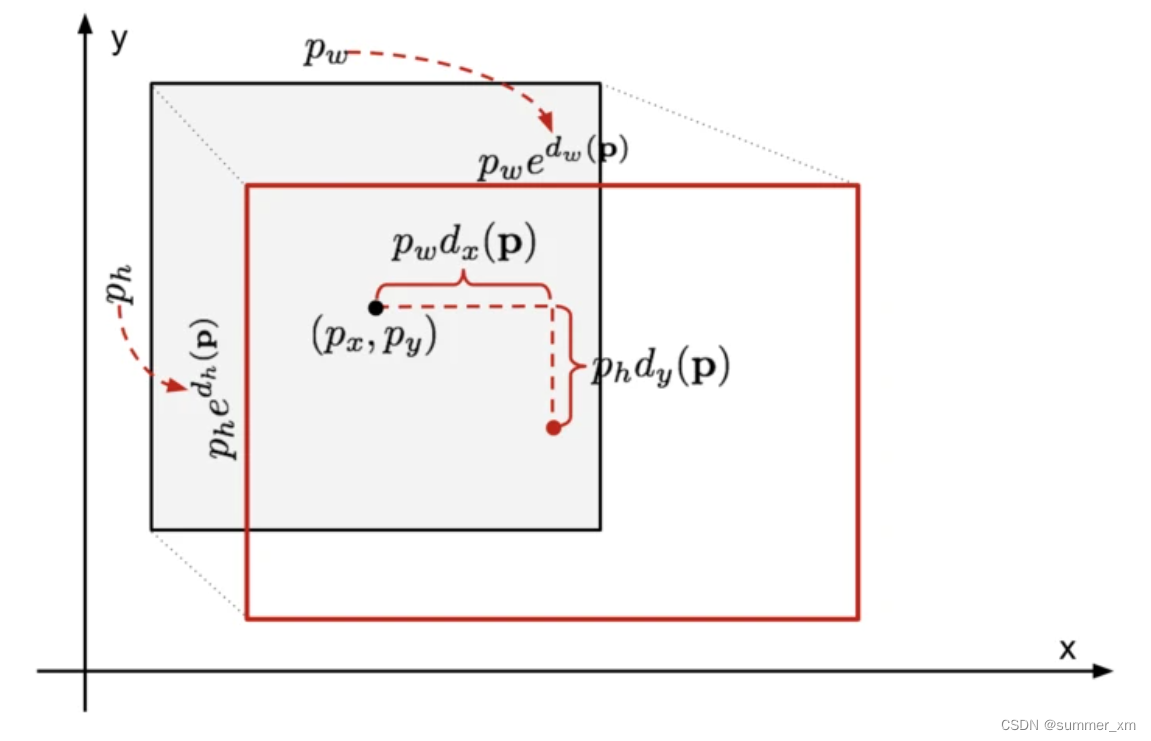
[px,py,pw,ph]表示原始anchor的坐标
[dx,dy,dw,dh]表示RPN网络预测的坐标偏移
[gx,gy,gw,gh]表示修正后的anchor坐标
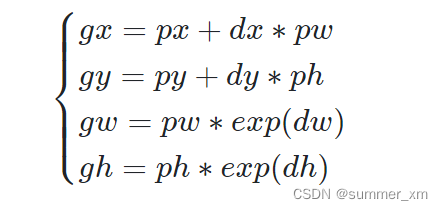
可以参考下图理解:
Proposal模块
-
根据第二条路得到的位置偏移量,对候选框进行修正;
-
边缘的anchor可能超出原图的范围,将严重超出边缘的anchor过滤掉;
-
根据第一条路得到的分数,抛弃不含物体的候选框,再通过分数排序,选前topN个候选框;但还是有很多重叠的候选框,使用非极大抑制(NMS)这些候选框中挑选出最适合的框,去掉大量重复的框,再按分数排序,取前topN;
-
将候选框映射到原图上。
NMS算法
在使用NMS时,我们需要选择一个阈值来判断两个候选框是否重叠。通常而言,如果两个候选框的IoU(Intersection over Union,重叠面积与两个框并集面积的比例)大于阈值,我们就认为它们是重复的。在进行NMS时,我们会对所有候选框按照它们对应的目标得分进行排序。然后,从最高分的框开始,我们将其添加到最终的框列表中,并从候选框列表中删除与该框IoU大于阈值的所有框。最终,我们得到的框列表中只包含IoU小于阈值的不同目标的候选框。
ROI pooling(Region Of Interest pooling)
ROI pooling称为感兴趣池化,主要的任务就是:
1.将RPN选出来的候选框在特征图上提取出来,因为RPN得到的候选框是相当于原图而言;
2.统一候选框的大小,方便送入后续的全连接层进行分类。我们知道RPN选出来的候选框有大有小,即不同尺度的候选框,而全连接层要求输入维度不变,那就必须使得候选框大小一致。
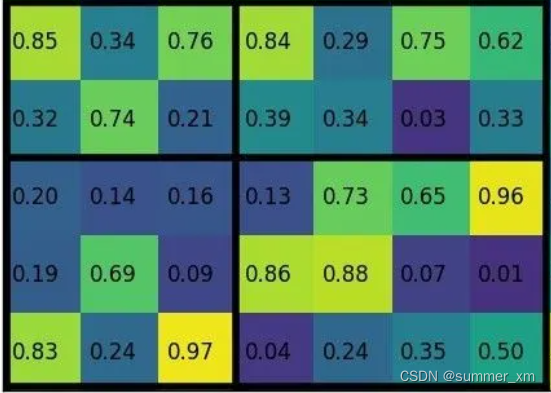
ROI pooling首先确定候选框统一为width*height(w*h),方法如下:它将候选框划分为w*h大小的网格,再对每个网格求平均值或者最大值,这样就得到了w*h大小的候选框。
例如,将候选框分为2*2,求每一网格的最大值,得到2*2的候选框。

分类
使用全连接层对候选框里的物体进行具体分类,同时再次修正候选框。假设有400个候选框,20个类别,则得到的结果维度是[400,20]。
训练过程
首先声明,下面所说的RPN=conv layers+RPN特有层(3*3卷积层、softmax层、1*1卷积层);Faster RCNN=conv layers+Faster RCNN特有层(全连接层、ROI pooling)
训练步骤:
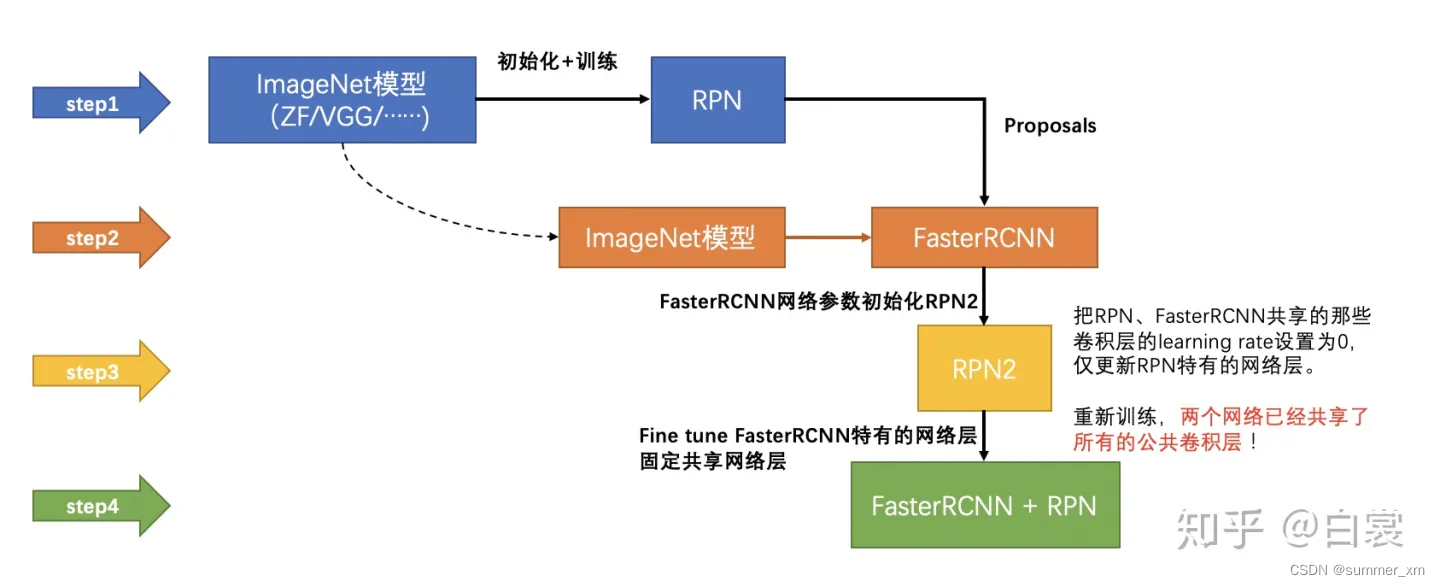
- 使用ImageNet预训练模型初始化conv layers,训练RPN,得到候选框(对应在原图上的候选框);
- 使用ImageNet预训练模型初始化conv layers,使用第一步的结果,训练Faster RCNN
- 使用第二步的conv layers参数再次训练RPN,训练过程中保持conv layers中的参数不变;
- 使用第二步的conv layers参数,以及使用第三步的结果,再次训练Faster RCNN;
参考文献
以上是我自己对Faster rcnn的一个学习总结,梳理了我对它的理解。大家如果看不太明白,可以直接阅读下面优秀的博文,讲的比我清楚。若有错误,欢迎大家指正
- 一文读懂Faster RCNNhttps://zhuanlan.zhihu.com/p/31426458
- ROI poolinghttps://zhuanlan.zhihu.com/p/65423423
- 一文读懂Faster RCNN(大白话,超详细解析)https://blog.csdn.net/weixin_42310154/article/details/119889682















 6064
6064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









