







yolo
YOLO(You Only Look Once)是一种用于对象检测的深度学习算法。它的关键思想是在单个神经网络中直接预测图像中的对象边界框和类别,从而实现快速和准确的对象检测。
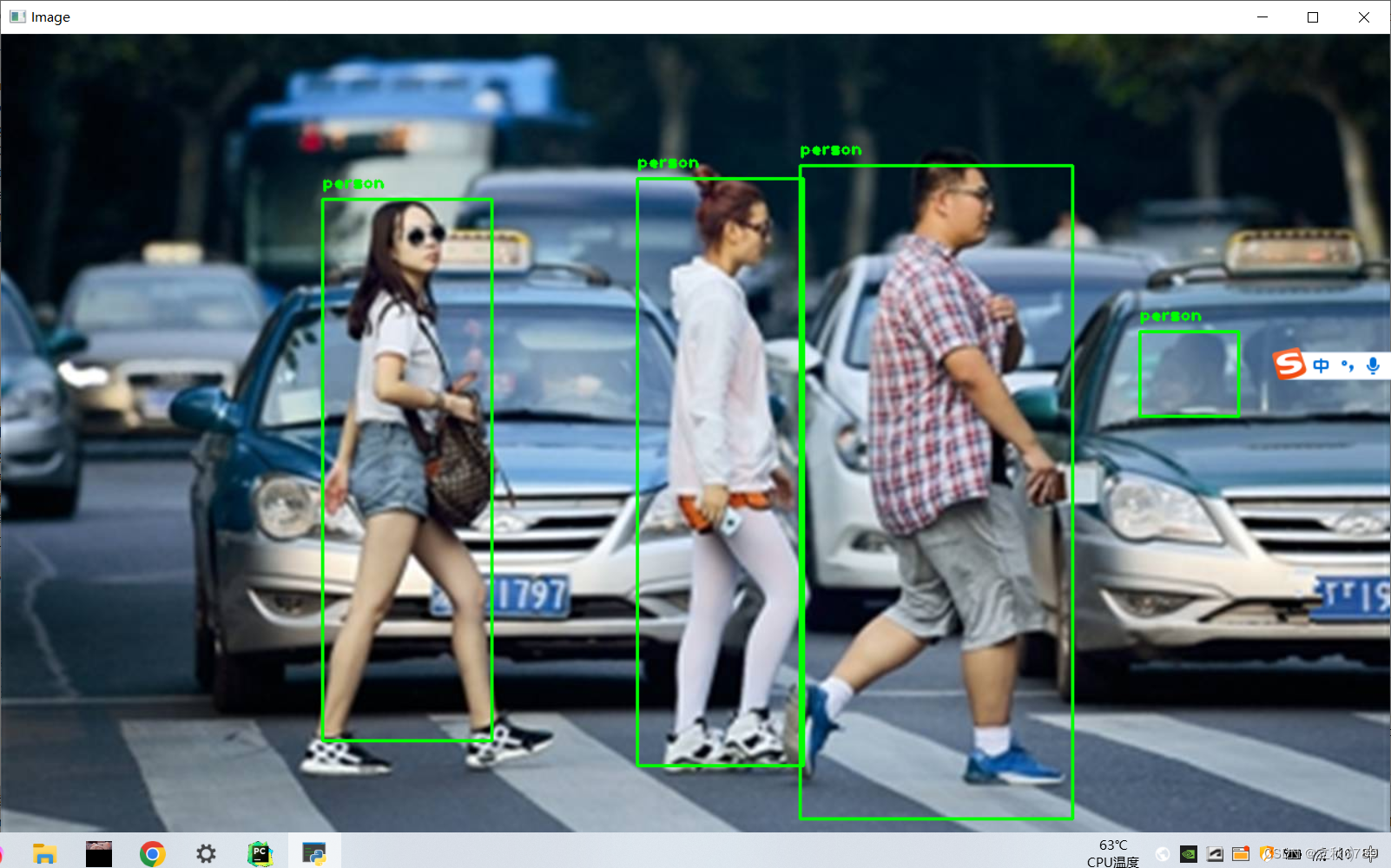
效果

代码
import cv2
import numpy as np
# 加载 YOLO
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
with open("coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
# 读取输入图像
image  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











