







目录标题
1、对比分析
1、绝对值(本身具备价值的数字) eg:销售金额、阅读数
2、比例值(在具体环境中看比例才具备对比价值) eg:活跃占比、注册转化率
3、环比:与当前时间范围相邻的上一个时间范围对比
eg:月环比 10月与9月比
4、同比:与历史同时期比较,就是与不同年份(月份)的同一时期作比较
eg:2005年7月份与2004年7月份相比,叫同比。
2、辛普森悖论
1、辛普森悖论定义
在分组比较中都占优势的一方,在总评中有时反而是失势的一方。
2、分析
(1)辛普森悖论成立时,通常是忽略了因果关系(causal relation);
影响康复率的根本因素是病情严重,而不是治疗方法;
(2)分组后观察数据更加清晰;
分组后,组之间的规模大小size差距悬殊,这导致各组权重应该是不同的。
案例中,在轻症患者分类下,方法B虽然处于弱势,但是弱的程度并不大,且B的规模比方法A大,这导致了方法B综合比A强;
从数据综合来看:方法A适用重症,B适用轻症;
3、费米问题
3.1 定义
费米问题是在科学研究中用来做量纲分析、估算和清晰地验证一个假设的估算问题。这类问题通常包括关于给定限定信息的有可能计算的数量的猜想的验证。
费米思想的核心:逻辑拆解。也就是说把一个庞大的、抽象的、复杂的问题,逐级拆解为微小的、具体的、简单的问题,然后再将这些小问题进一步拆解,只要保证了逻辑关系,那么将这些可以回答的小问题答案,逐步反推到费米问题上,就可以得到最终的准确答案。
3.2 举例
第一个大问题:全部钢琴调音师一年总工作时间
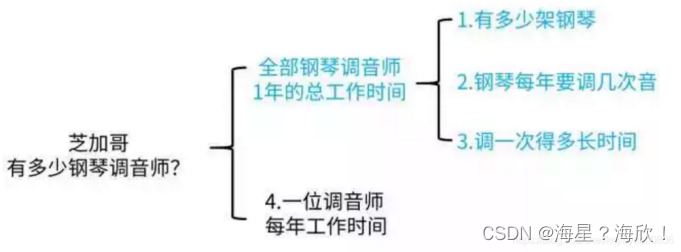
1,第一个子问题:芝加哥有多少架钢琴?
首先需要知道芝加哥有多少人,其次需要知道拥有钢琴的人所占的一个比例。芝加哥的人口上网可以查出来大概有250万,平均每个家庭有4个人(美国四人家庭居多),那么芝加哥估计会有75万个家庭。这些家庭中有多少有钢琴呢?在当时的美国,钢琴属于半稀缺物品,拥有钢琴的家庭应该不会超过1/2,也不会低于1/10,因此费米估算为1/3,那么全市大概会有25万架钢琴。
2,第二个子问题:钢琴每年要调几次音?
钢琴调音师属于稀缺行业,调音次数应该不会超过1年3次,也不会低于10年1次,因此费米估算为3年1次,也就是每年0.33次,那么每年全市有8.3万架钢琴需要调音。
3,第三个子问题:调一次得多久?
一般不会超过10小时,也不会低于1小时,因此费米估算为3小时。
这样第一个大问题我们就解决了,总钢琴的总调音时长大约是3*83000=249000H。
第二个大问题:一位调音师每年工作多长时间呢?
假设调音师一年工作250天,算上他每天需要往返的路时,那么他一年的工作时间就是250240.6=3600H。
这样所有的问题都已经估算出了结果,最终调音师数量=249000/3600=69位。
3.3 平均律
费米估算法中涉及到了一个数据概念:平均律。
它的原理是在任何一组计算中,估算带来的错误都可以相互抵消,所做的假设越多,被抵消的概率就会越大。
换成数据分析的语言就是,你在假设或者猜测某一个小事件的时候,你的推测假设有可能有的过高,有可能有的过低,如果这些“点”的数量足够,最终误差就会被相互抵消,整体结果最终会呈现为一个平均值,这就是平均律理论。
4、幸存者偏差
4.1 定义
幸存者偏差指用于统计的样本数据有偏,导致结论与实际情况存在偏差的情况。
4.2 产生原因
之所以会产生幸存者偏差,是因为很多人从一开始就搞错了统计样本,只看到经过筛选的数据,但没有意识到筛选的过程。如果只是人为地选择部分观察数据,那就无法保证结论的客观性。
注意:
与幸存者偏差相类似的,还有一个叫作选择性偏差。
选择性偏差是在抽样时出现的一大问题。有时,人们为了证明自己的观点,倾向于选择特定的数据来支撑结论,从而忽略了其他证据。采用有偏差的抽样数据,几乎可以得到人们想要的任何结论。
- 幸存者偏差提醒我们,要考察所有类型的数据。
- 选择性偏差提醒我们,要客观地挑选数据。
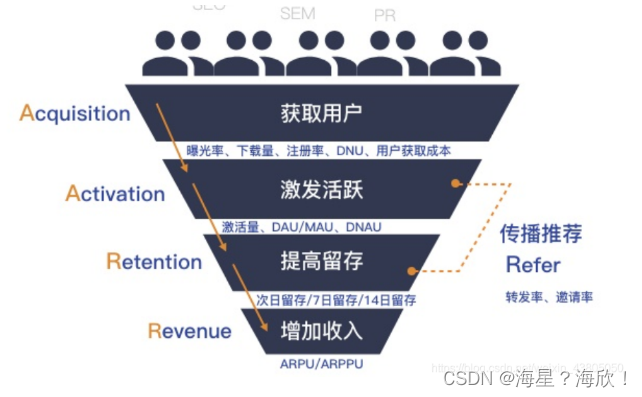
5、AARRR模型(用户分层方法1、漏斗转化模型)
AARRR模型又称海盗模型,指的是一款产品在运营阶段的各个生命周期,主要有五个阶段:拉新、激活、留存、付费、传播,可以指导产品运营和用户增长。
6、RFM模型
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。
- R (Recency):指用户的最近一次消费时间,简单来说就是用户最后一次下单时间距今天有多长时间了,这个指标与用户流失和复购直接相关。
- F(Frequency):指用户下单频率,简单来说就是用户在固定的时间段内消费了几次。这个指标反映了用户的消费活跃度。
- M(Monetary):指用户消费金额,简单来说就是用户在固定的周期内在平台上花了多少钱,直接反映了用户对公司贡献的价值。
RFM模型就是根据用户近期购买行为、购买总体频率和花了多少钱三项指标来描述该客户的价值状况。
7、用户留存分析
定义:
第n日留存率 = (第一日新增的,且第n日仍在使用的用户数) / 第一日新增用户数
假如今天新增了100名用户,第二天登陆了50名,则次日留存率为50/100=50%,第三天登录了30名,则第三日留存率为30/100=30%,以此类推。
分析:
- 产品的核心功能,使用率和留存率都很高。比如b站的发送弹幕、抖音的点赞功能。对于核心功能,我们要保证功能的体验越来越好,并持续监控使用情况,防止生态恶化;
- 有些功能虽然使用的人数不多,但留存率非常高。说明这个功能的体验很好,我们要尽量引导用户使用这个功能;
- 有些功能虽然dau很高,但留存率较低。也许是这个功能比较吸引用户,但体验不好;可以通过漏斗模型,看功能哪个环节出现了问题,有针对性地进行优化。
(3)新老用户同期分析模型
产品接入品台的SDK接口时,每天能够从后台得到用户的数据。 - 如果新用户留存率较低,那说明产品对新人的吸引力度不够。不如电商app发送的优惠券较少。
- 老用户如果持续流失的话,说明产品某些核心的功能出现了问题,需要及时调整。
8、转化漏斗分析
漏斗分析模型已经广泛应用于流量监控、产品目标转化等日常数据运营与数据分析的工作中。例如在一款产品服务平台中,直播用户从激活 APP 开始到花费,一般的用户购物路径为激活 APP、注册账号、进入直播间、互动行为、礼物花费五大阶段,漏斗能够展现出各个阶段的转化率,通过漏斗各环节相关数据的比较,能够直观地发现和说明问题所在,从而找到优化方向。
通过与其他数据分析模型结合进行深度用户行为分析,从而找到用户流失的原因,以提升用户量、活跃度、留存率,并提升数据分析与决策的科学性等。
9、用户生命周期模型
用户的生命周期,简单来说就是:用户从开始接触产品到离开产品的整个过程。
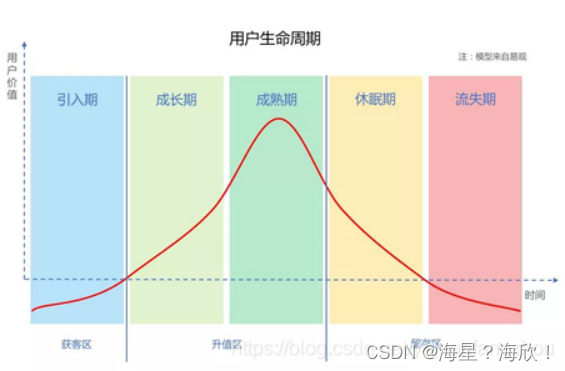
根据上图可知,用户的生命周期主要分为5个阶段:导入期、成长期、成熟期、休眠期、流失期。
根据用户发生的行为,找到用户处于生命周期的哪个阶段,是导入期还是成熟期,知道了用户所处阶段,才能方便我们进一步开展运营工作。
10、用户分层
用户分层是以用户价值(比如说:活跃用户、高价值用户)为中心来进行切割的,在同一分层模型下,一个用户只会处于一个层次中。
还有一种说法是用户分群,它是以用户属性(用户身上的某一类标签,比如:喜欢在地铁上看书的用户)为中心进行划分,1个用户可能会同时拥有多个属性。
用户分层的本质是一种以用户和特征、用户行为等为中心对用户进行细分的精细化运营。
四种常见的用户分层方法
https://www.jianshu.com/p/5bb31f906aee















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









