






一、回顾与引入
在第一天我们了解了蓝桥杯赛制以及暴力解法在比赛中的应用。暴力解法能帮我们在一些题目中拿到部分分数,但要在比赛中取得更好成绩,还需要掌握更高效的工具和方法。在今天的基础版中,我们学习了 C++ 中非常实用的 vector、set、stack 和 queue 这四个容器。这一讲我们将继续深入学习 C++ STL(Standard Template Library)中的其他几个重要容器,包括 priority_queue、multiset 和 map,这些容器能帮助我们更方便、高效地处理数据,在蓝桥杯的编程题中经常会用到。
注意:以下所有代码中的头文件都不需要单独记忆,可以直接用#include<bits/stdc++.h>这个万能头文件代替
二、priority_queue 容器
(一)概念
priority_queue(优先队列)是 C++ STL 中的一个容器适配器,它实现了一个优先队列。优先队列和普通队列的区别在于,普通队列是按照先进先出(FIFO)的原则进行操作,而优先队列中的元素会按照某种特定的顺序(默认是从大到小)进行排序,每次取出的元素是当前队列中优先级最高的元素。
(二)特点
- 自动排序:
priority_queue会自动根据元素的优先级对元素进行排序。默认情况下,它使用<运算符来比较元素,实现从大到小的排序。例如,对于数值类型,较大的数优先级更高。 - 操作受限:它只允许在队顶进行插入(
push)和删除(pop)操作,不支持像普通数组那样的随机访问,也不能在中间插入或删除元素。
(三)定义与初始化
#include <bits/stdc++.h>
using namespace std;
int main() {
// 定义一个存储int类型的优先队列,默认从大到小排序
priority_queue<int> pq;
// 定义一个存储double类型的优先队列
priority_queue<double> pq_double;
// 定义一个存储自定义结构体类型的优先队列,需要自定义比较函数
struct Node {
int value;
// 自定义比较函数,实现从小到大排序
bool operator<(const Node& other) const {
return value > other.value;
}
};
priority_queue<Node> pq_node;
return 0;
}(四)常用函数
push():用于将一个元素插入到优先队列中。
#include <bits/stdc++.h>
using namespace std;
int main() {
priority_queue<int> pq;
pq.push(5);
pq.push(3);
pq.push(7);
return 0;
}pop():删除优先队列顶部(优先级最高)的元素,注意该函数不返回被删除的元素。
#include <bits/stdc++.h>
using namespace std;
int main() {
priority_queue<int> pq;
pq.push(5);
pq.push(3);
pq.push(7);
pq.pop(); // 删除优先级最高的元素(这里是7)
return 0;
}top():返回优先队列顶部(优先级最高)的元素,但不删除该元素。
#include <bits/stdc++.h>
using namespace std;
int main() {
priority_queue<int> pq;
pq.push(5);
pq.push(3);
pq.push(7);
int top_element = pq.top(); // 获取优先级最高的元素(这里是7)
cout << top_element << endl;
return 0;
}size():返回优先队列中元素的数量。
#include <bits/stdc++.h>
using namespace std;
int main() {
priority_queue<int> pq;
pq.push(5);
pq.push(3);
pq.push(7);
int size_num = pq.size();
cout << size_num << endl;
return 0;
}empty():判断优先队列是否为空,如果为空则返回true,否则返回false。
#include <bits/stdc++.h>
using namespace std;
int main() {
priority_queue<int> pq;
bool is_empty = pq.empty();
cout << (is_empty? "true" : "false") << endl;
return 0;
}(五)自定义排序规则
- 基本数据类型自定义排序(从小到大)
对于基本数据类型,如int、double等,如果想要实现从小到大排序,可以通过自定义比较函数来实现。我们可以使用greater<类型>。#include <bits/stdc++.h> using namespace std; int main() { // 定义一个存储int类型的优先队列,实现从小到大排序 priority_queue<int, vector<int>, greater<int>> pq_asc; pq_asc.push(5); pq_asc.push(3); pq_asc.push(7); while (!pq_asc.empty()) { cout << pq_asc.top() << " "; pq_asc.pop(); } return 0; }这里
priority_queue<int, vector<int>, greater<int>>,第二个模板参数vector<int>是指定优先队列的底层容器(这里使用vector),第三个模板参数greater<int>是比较函数,它定义了从小到大的比较规则。 - 自定义结构体类型排序
当我们要对自定义结构体类型进行排序时,有两种常见方式。- 重载
operator<
- 重载
#include <bits/stdc++.h>
using namespace std;
struct Node {
int value;
// 重载小于号,实现从小到大排序
bool operator<(const Node& other) const {
return value > other.value;
}
};
int main() {
priority_queue<Node> pq_node;
Node n1 = {3}, n2 = {1}, n3 = {2};
pq_node.push(n1);
pq_node.push(n2);
pq_node.push(n3);
while (!pq_node.empty()) {
cout << pq_node.top().value << " ";
pq_node.pop();
}
return 0;
}在这个结构体中,重载了operator< ,当在优先队列中比较Node 类型的元素时,就会按照我们定义的规则进行比较。这里返回value > other.value ,表示按照value 从小到大排序。
- 使用自定义比较类
#include <bits/stdc++.h> using namespace std; struct Node { int value; }; struct CompareNode { bool operator()(const Node& a, const Node& b) const { return a.value > b.value; } }; int main() { priority_queue<Node, vector<Node>, CompareNode> pq_custom; Node n1 = {3}, n2 = {1}, n3 = {2}; pq_custom.push(n1); pq_custom.push(n2); pq_custom.push(n3); while (!pq_custom.empty()) { cout << pq_custom.top().value << " "; pq_custom.pop(); } return 0; }这里定义了一个比较类
CompareNode,重载了()运算符,在定义优先队列priority_queue<Node, vector<Node>, CompareNode>时,将这个比较类作为第三个模板参数传入,从而实现按照我们期望的规则对Node类型元素进行排序。
(六)真题训练:试题 G: 爬山



本题的核心目标是通过合理运用两种魔法(第一种魔法能把高度为 H 的山变为 ⌊sqrt(H)⌋,可使用 P 次;第二种魔法能把高度为 H 的山变为 ⌊H / 2⌋,可使用 Q 次),来最小化爬山所耗费的体力值。
为达成这一目标,我们采用优先队列(大顶堆)这一数据结构,其特性是每次取出的元素为队列中的最大值。具体步骤如下:
- 输入处理:读取的数量
n、两种魔法的可用次数p和q,并将每座山的高度存入优先队列。 - 魔法使用:只要还有可用的魔法次数,就从优先队列中取出当前最高的山,依据山的高度和魔法的剩余次数,合理选择使用哪种魔法,以实现高度的最大降低。
- 高度更新:对使用魔法后的山的高度进行更新,并将其重新放入优先队列。
- 结果计算:在所有魔法使用完毕后,把优先队列中剩余的山的高度累加,从而得到最终的体力值。
代码:
#include <bits/stdc++.h>
using namespace std;
int main()
{
int n, P, Q;
long long ans = 0;
// 定义一个大顶堆h,用于存储山的高度,方便每次取出最高的山
priority_queue<int> h;
// 读取山的数量n,第一种魔法的可用次数P,第二种魔法的可用次数Q
cin >> n >> P >> Q;
for (int i = 0; i < n; i++)
{
int hi;
// 读取每座山的高度hi
cin >> hi;
// 将山的高度hi加入大顶堆h中
h.push(hi);
}
// 当两种魔法还有可用次数时,循环进行操作
while (P || Q)
{
// 取出堆顶元素,即当前最高的山的高度
int first = h.top();
h.pop();
// 如果两种魔法都有可用次数
if (P && Q)
{
// 比较两种魔法作用后的山的高度,选择能使山变得更矮的魔法
if (sqrt(first) <= first / 2)
{
// 使用第一种魔法,将山的高度变为其平方根向下取整
h.push(sqrt(first));
// 第一种魔法可用次数减1
P--;
}
else
{
// 使用第二种魔法,将山的高度变为其一半向下取整
h.push(first / 2);
// 第二种魔法可用次数减1
Q--;
}
}
// 如果只剩下第一种魔法有可用次数
else if (P)
{
// 使用第一种魔法,将山的高度变为其平方根向下取整
h.push(sqrt(first));
// 第一种魔法可用次数减1
P--;
}
// 如果只剩下第二种魔法有可用次数
else if (Q)
{
// 使用第二种魔法,将山的高度变为其一半向下取整
h.push(first / 2);
// 第二种魔法可用次数减1
Q--;
}
}
// 遍历堆,将剩余山的高度累加起来,得到最终花费的体力值
while (!h.empty())
{
ans += h.top();
h.pop();
}
// 输出最优情况下需要花费的体力值
cout << ans;
return 0;
}注意:这一题可能只能通过90%的样例,并不能通过全部样例
三、multiset 容器
(一)概念
multiset是 C++ STL 中的一个关联式容器,它以红黑树(一种自平衡的二叉搜索树)作为底层数据结构,用于存储元素。与set不同的是,multiset允许存储重复的元素,并且会自动对元素进行排序(默认从小到大)。
(二)特点
- 允许重复元素:
multiset可以存储多个相同的元素,这在处理一些需要统计重复数据的场景中非常有用。 - 自动排序:内部会根据元素的值对元素进行排序,默认是按照从小到大的顺序。这使得我们在遍历
multiset时,元素是有序的。 - 高效查找:由于底层是红黑树结构,插入、删除和查找操作的时间复杂度都是\(O(\log n)\),其中n是
multiset中元素的数量。
(三)定义与初始化
#include <bits/stdc++.h>
using namespace std;
int main() {
// 定义一个存储int类型的multiset
multiset<int> ms;
// 初始化一个存储int类型的multiset,并插入一些元素
multiset<int> ms_init = {1, 2, 2, 3};
// 定义一个存储自定义结构体类型的multiset,需要自定义比较函数
struct Node {
int value;
bool operator<(const Node& other) const {
return value < other.value;
}
};
multiset<Node> ms_node;
return 0;
}注意:相关自定义排序用法和基础版set一致
(四)常用函数
insert():用于向multiset中插入一个元素。
#include <bits/stdc++.h>
using namespace std;
int main() {
multiset<int> ms;
ms.insert(3);
ms.insert(1);
ms.insert(2);
return 0;
}erase():删除multiset中的元素。有两种用法,一种是删除指定值的所有元素,另一种是删除指定迭代器位置的元素。
#include <bits/stdc++.h>
using namespace std;
int main() {
multiset<int> ms = {1, 2, 2, 3};
// 删除值为2的所有元素
ms.erase(2);
// 定义迭代器删除元素
multiset<int>::iterator it = ms.find(3);
if (it != ms.end()) {
ms.erase(it);
}
return 0;
}find():查找multiset中是否存在某个元素,若存在则返回指向该元素的迭代器,否则返回end()迭代器。
#include <bits/stdc++.h>
using namespace std;
int main() {
multiset<int> ms = {1, 2, 3};
multiset<int>::iterator it = ms.find(2);
if (it != ms.end()) {
cout << "Element found" << endl;
} else {
cout << "Element not found" << endl;
}
return 0;
}size():返回multiset中元素的数量。
#include <bits/stdc++.h>
using namespace std;
int main() {
multiset<int> ms = {1, 2, 3};
int size_num = ms.size();
cout << size_num << endl;
return 0;
}empty():判断multiset是否为空,如果为空则返回true,否则返回false。
#include <bits/stdc++.h>
using namespace std;
int main() {
multiset<int> ms;
bool is_empty = ms.empty();
cout << (is_empty? "true" : "false") << endl;
return 0;
}(五)真题训练:试题 H: 拔河



解题思路
本题的目标是在给定的 n 名同学的力量值数组中,挑选出两个编号连续的同学队伍,使得这两个队伍的力量值之和尽可能相近,需要计算出这两个队伍力量值之和的最小差距。
为了解决这个问题,我们采用以下步骤:
- 前缀和数组的构建:为了能够快速计算任意区间内同学的力量值之和,我们先构建前缀和数组。前缀和数组
a[i]表示从第 1 名同学到第i名同学的力量值总和。这样,对于任意区间[l, r],其力量值之和就可以通过a[r] - a[l - 1]来计算。 - 右区间所有可能情况的枚举:我们使用
multiset来存储所有可能的右区间的力量值之和。multiset是一个有序的容器,它会自动对元素进行排序,并且允许存储重复的元素。通过双重循环枚举所有可能的右区间[i, j],并将其力量值之和a[j] - a[i - 1]插入到multiset中。 - 左区间的枚举与最小差距的计算:我们通过双重循环枚举左区间
[j, i],对于每个左区间,我们需要在multiset中找到最接近该左区间力量值之和的右区间力量值之和。为了避免左区间和右区间重叠,我们在每次枚举左区间之前,先从multiset中删除所有以当前左区间右端点i作为起始点的右区间情况。然后,使用lower_bound函数在multiset中找到第一个大于等于左区间力量值之和的元素,计算该元素与左区间力量值之和的差值的绝对值,同时也考虑该元素前一个元素与左区间力量值之和的差值的绝对值,取两者中的较小值作为当前的最小差距。最后,不断更新全局最小差距res。
代码:
#include<bits/stdc++.h>
using namespace std;
// 定义数组的最大长度
const int N = 1e3+10;
// 存储前缀和数组
long long a[N];
// 同学的数量
int n;
// 用于存储所有可能的右区间的力量值之和
multiset<long long>s;
// 自定义函数,返回两个数中的较小值
long long minn(long long a,long long b){
if(a<b) return a;
else return b;
}
int main(){
// 读取同学的数量
cin>>n;
// 读取每个同学的力量值,并构建前缀和数组
for(int i = 1;i<=n;i++) {
cin>>a[i];
// 计算前缀和
a[i]+=a[i-1];
}
// 枚举所有可能的右区间 [i, j],并将其力量值之和插入到 multiset 中
for(int i = 1;i<=n;i++){
for(int j = i;j<=n;j++){
// 计算右区间 [i, j] 的力量值之和并插入到 multiset 中
s.insert(a[j]-a[i-1]);
}
}
// 初始化最小差距为一个较大的值
long long res = 1e9;
// 枚举左区间的右端点 i
for(int i = 1;i<n;i++){
// 删除所有以 i 作为右区间起始点的情况,避免左区间和右区间重叠
for(int j = i;j<=n;j++){
// 计算以 i 为起始点的右区间 [i, j] 的力量值之和
auto k = a[j] - a[i-1];
// 从 multiset 中删除该力量值之和
s.erase(s.find(k));
}
// 枚举左区间的左端点 j
for(int j = 1;j<=i;j++){
// 计算左区间 [j, i] 的力量值之和
auto k = a[i] - a[j-1];
// 在 multiset 中找到第一个大于等于 k 的元素
auto p = s.lower_bound(k);
// 如果找到了这样的元素,计算其与 k 的差值的绝对值,并更新最小差距
if(p!=s.end()){
res = minn(res,abs(*p-k));
}
// 如果 p 不是 multiset 的第一个元素,考虑其前一个元素与 k 的差值的绝对值,并更新最小差距
if(p!=s.begin()){
p--;
res = minn(res,abs(*p-k));
}
}
}
// 输出最小差距
cout<<res<<endl;
return 0;
}四、map 容器与 pair
(一)pair 的概念
pair 是 C++ 中的一种模板类型,它可以将两个不同类型(也可以相同类型)的数据组合成一个单元。简单来说,pair 就像是一个小型的容器,专门用来存放两个相关联的值,方便在函数返回多个不同类型的值,或者在一些数据结构中表示关联关系时使用 。例如,在表示平面直角坐标系中的一个点时,可以用 pair<int, int> 来分别存储横坐标和纵坐标。
(二)pair 的定义与初始化
直接定义与初始化
#include <iostream>
#include <utility> // 包含pair需要引入此头文件
using namespace std;
int main() {
// 定义一个存储int和string类型的pair,并初始化
pair<int, string> p1(1, "one");
// 也可以先定义,后赋值
pair<double, char> p2;
p2 = make_pair(3.14, 'a');
return 0;
}使用make_pair函数
make_pair 函数可以根据传入的参数类型,自动推导出 pair 的模板参数类型,更方便地创建 pair 对象。
#include <iostream>
#include <utility>
using namespace std;
int main() {
auto p3 = make_pair(2, "two"); // 这里使用auto让编译器自动推导类型
return 0;
}(三)pair 的成员访问
pair 有两个公共成员:first 和 second,分别用于访问组合中的第一个元素和第二个元素。
#include <iostream>
#include <utility>
using namespace std;
int main() {
pair<int, string> p(5, "five");
cout << "第一个元素: " << p.first << endl;
cout << "第二个元素: " << p.second << endl;
return 0;
}(四)map 容器概念
map 是 C++ STL 中的一个关联式容器,它使用红黑树作为底层数据结构,用于存储键值对(key - value)。map 中的键(key)是唯一的,并且会自动按照键的大小进行排序(默认从小到大),通过键可以快速查找对应的值(value)。例如,在一个学生成绩管理系统中,可以用学生的学号作为键,成绩作为值存储在 map 中,方便通过学号快速查询成绩。
(五)map 容器特点
- 键值对存储:以键值对的形式存储数据,方便通过键来快速访问对应的值。
- 键唯一性:
map中的键不能重复,这使得它在一些需要去重和查找对应关系的场景中非常实用。 - 自动排序:内部根据键的大小对键值对进行排序,便于有序遍历。
- 高效查找:插入、删除和查找操作的时间复杂度都是\(O(\log n)\),其中n是
map中元素的数量。
(六)map 容器定义与初始化
#include <bits/stdc++.h>
using namespace std;
int main() {
// 定义一个存储int类型键和int类型值的map
map<int, int> m;
// 初始化一个map并插入一些键值对
map<int, string> m_init = { {1, "one"}, {2, "two"} };
// 定义一个存储自定义结构体类型作为键的map,需要自定义比较函数
struct Node {
int value;
bool operator<(const Node& other) const {
return value < other.value;
}
};
map<Node, int> m_node;
return 0;
}(七)map 容器常用函数
insert():用于向map中插入键值对。有多种插入方式。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m;
// 方式一:使用make_pair插入
m.insert(make_pair(1, 10));
// 方式二:使用花括号插入
m.insert({2, 20});
// 方式三:使用数组下标方式插入(如果键不存在则插入,存在则修改值)
m[3] = 30;
return 0;
}erase():删除map中的元素,可以通过键或者迭代器来删除。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m = { {1, 10}, {2, 20} };
// 通过键删除元素
m.erase(1);
// 通过迭代器删除元素
map<int, int>::iterator it = m.find(2);
if (it != m.end()) {
m.erase(it);
}
return 0;
}find():查找map中是否存在某个键,若存在则返回指向该键值对的迭代器,否则返回end()迭代器。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m = { {1, 10}, {2, 20} };
map<int, int>::iterator it = m.find(2);
if (it != m.end()) {
cout << "Key found" << endl;
} else {
cout << "Key not found" << endl;
}
return 0;
}size():返回map中元素的数量。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m = { {1, 10}, {2, 20} };
int size_num = m.size();
cout << size_num << endl;
return 0;
}empty():判断map是否为空,如果为空则返回true,否则返回false。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m;
bool is_empty = m.empty();
cout << (is_empty? "true" : "false") << endl;
return 0;
}operator[]:通过键访问对应的值,如果键不存在,会自动插入一个默认值的键值对。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m;
m[1] = 10; // 插入键值对
int value = m[1]; // 访问键为1的值
cout << value << endl;
return 0;
}(八)map 与 pair 的关系
map 容器中存储的元素类型就是 pair<const key_type, value_type> ,其中键的类型是常量类型,这保证了键的不可修改性,以维护 map 中键的唯一性和有序性。在向 map 中插入元素时,通常需要创建 pair 对象,可以使用 make_pair 函数来方便地构造。例如:
#include <bits/stdc++.h>
using namespace std;
int main() {
map<int, string> m;
// 使用make_pair插入键值对
m.insert(make_pair(1, "one"));
// 也可以直接用花括号初始化,其内部也是构建了pair对象
m.insert({2, "two"});
return 0;
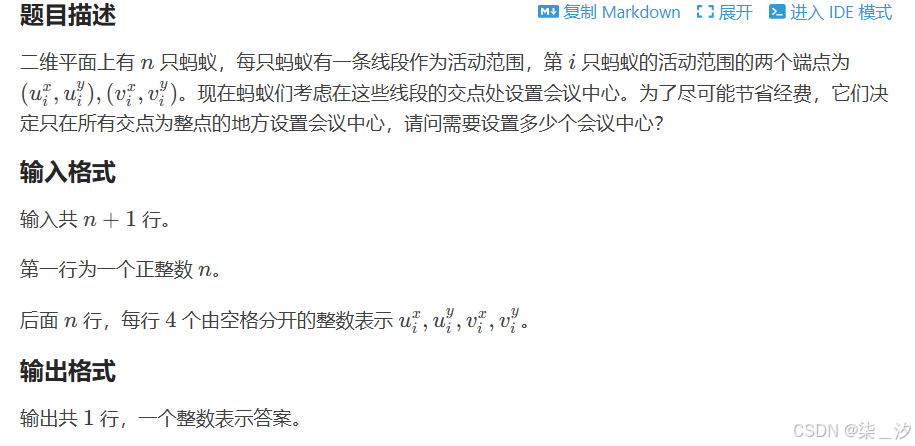
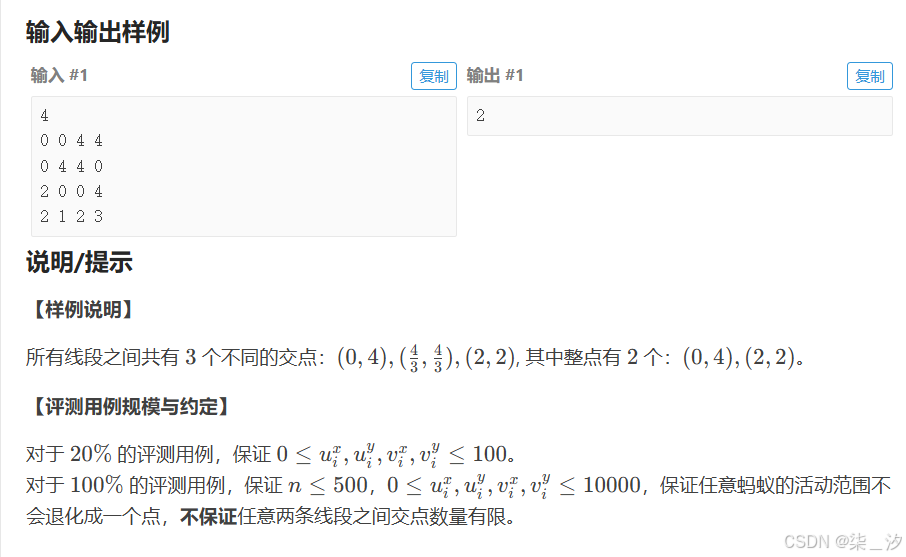
}(九)真题训练:蚂蚁开会
解题思路
本题的目标是计算出所有线段之间整数坐标交点的数量。为了达成这个目标,我们可以按照以下步骤进行操作:
-
输入处理:首先读取线段的数量
n,接着依次读取每条线段的两个端点坐标。 -
计算每条线段经过的整数点:对于每一条线段,我们需要找出它所经过的所有整数坐标点。为了实现这一点,我们会使用最大公约数(GCD)来确定线段的方向向量,然后沿着这个方向向量逐步移动,记录下经过的所有整数点。在这个过程中,我们使用
map来统计每个整数点被经过的次数。 -
统计交点数量:遍历
map中的所有元素,检查每个整数点被经过的次数。如果某个整数点被经过的次数大于等于 2,那么就说明有至少两条线段经过了这个点,我们将其视为一个交点,并将交点的数量加 1。 -
输出结果:最后,输出统计得到的交点数量。
代码:
#include<iostream>
#include<cstring>
#include<algorithm>
#include<map>
using namespace std;
// 定义长整型别名,方便后续使用
typedef long long LL;
// 定义整数对别名,用于表示坐标点
typedef pair<int, int> PII;
// 定义常量 N,作为数组的最大长度
const int N = 505;
// n 表示线段的数量,m 未在代码中使用
int n, m;
// ux 和 uy 存储线段起点的 x 和 y 坐标
int ux[N], uy[N];
// vx 和 vy 存储线段终点的 x 和 y 坐标
int vx[N], vy[N];
// 定义一个 map,用于统计每个整数坐标点被线段经过的次数
map<PII, int> cnt_mp;
// 计算两个整数的最大公约数
int gcd(int a, int b)
{
// 当 b 不为 0 时,递归调用 gcd 函数,直到 b 为 0
// 当 b 为 0 时,a 和 0 的最大公约数即为 a,故返回 a
return b ? gcd(b, a % b) : a;
}
// 记录每条线段经过的整数点
void count(int i)
{
// 获取第 i 条线段的起点和终点的 x 坐标
int x1 = ux[i], x2 = vx[i];
// 获取第 i 条线段的起点和终点的 y 坐标
int y1 = uy[i], y2 = vy[i];
// 计算 x 方向的差值
int dx = x2 - x1;
// 计算 y 方向的差值
int dy = y2 - y1;
// 计算 dx 和 dy 的绝对值的最大公约数
int d = gcd(abs(dx), abs(dy));
// 对 dx 进行归一化处理
dx = dx / d;
// 对 dy 进行归一化处理
dy = dy / d;
// 从起点开始,沿着归一化后的方向向量移动,记录经过的整数点
for (int i = 0; ; i++) {
// 计算当前点的 x 坐标
int x = x1 + i * dx;
// 计算当前点的 y 坐标
int y = y1 + i * dy;
// 将当前点的经过次数加 1
cnt_mp[{x, y}]++;
// 当到达线段的终点时,停止循环
if (x == x2 && y == y2) break;
}
}
// 解决问题的主函数
void solve()
{
// 读取线段的数量
cin >> n;
// 未使用的变量,可能是预留的
int mx = 0, my = 0;
// 读取每条线段的起点和终点坐标
for (int i = 0; i < n; i++) {
cin >> ux[i] >> uy[i] >> vx[i] >> vy[i];
}
// 遍历每条线段,记录其经过的整数点
for (int i = 0; i < n; i++) {
count(i);
}
// 初始化交点数量为 0
int ans = 0;
// 遍历 map 中的所有元素
for (map<PII, int>::iterator it = cnt_mp.begin(); it != cnt_mp.end(); it++) {
// 如果某个整数点被经过的次数大于等于 2,说明是交点,交点数量加 1
if (it->second >= 2) ans++;
}
// 输出交点数量
cout << ans << endl;
}
int main()
{
// 调用 solve 函数解决问题
solve();
return 0;
}五、总结
在本次博客中,我们围绕蓝桥杯 C/C++ 竞赛,深入探讨了 C++ STL 中的priority_queue、multiset以及map与pair的相关知识,并结合真题进行了实战训练。
在priority_queue的学习中,我们认识到它作为优先队列,默认从大到小排序,能够按照元素优先级进行操作。通过学习自定义排序规则,无论是基本数据类型借助greater<类型>实现从小到大排序,还是自定义结构体类型通过重载operator<或使用自定义比较类,都能灵活满足不同场景需求。在 “爬山” 真题里,借助priority_queue优先处理高度变化量大的山,有效解决了降低爬山体力值的问题。
multiset作为关联式容器,允许存储重复元素且自动排序,在处理需要统计重复数据和有序查找的场景中优势明显。在 “拔河” 问题中,通过构建前缀和数组,并借助multiset来存储和查找合适的区间力量值之和,成功找出了力量值之和差距最小的队伍分配方式。
pair能将两个不同类型的数据组合成一个单元,方便在多种场景下传递和处理数据。map作为关联式容器,以键值对的形式存储数据,键唯一且自动排序,查找效率高。在 “蚂蚁开会” 一题中,通过map统计每个整数坐标点被线段经过的次数,结合对每条线段整数点的计算,准确统计出了交点数量。
通过对这些容器和数据结构的学习与实践,我们可以在蓝桥杯竞赛中,面对不同类型的题目,选择合适的数据结构和算法,提升解题效率和准确性。建议大家在后续的学习中,多做相关练习题,加深对这些知识的理解和运用,为在蓝桥杯等编程竞赛中取得优异成绩奠定坚实的基础。

















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









