






真题链接:2024年第十五届蓝桥杯软件赛决赛C/C++大学B组真题 - 题库 - C语言网
省赛国赛题目是大差不差的,大家如果在省赛前也可以去把国赛题目做一遍,心里有个底!(省赛的经验分享这两天我也会发)
试题A——合法密码

一、解题思路
- 确定密码合法的条件:
- 长度条件:密码长度需在8到16个字符之间。
- 字符类型条件:必须同时包含至少1个数字字符和至少1个符号字符(这里除了字母和数字之外的字符视为符号字符 )。
- 遍历所有子串:
- 采用双重循环,外层循环控制子串的起始位置
i,内层循环控制子串的结束位置j。 - 对于每一个从位置
i到位置j的子串,判断其是否满足上述合法密码的条件。
- 采用双重循环,外层循环控制子串的起始位置
- 统计合法子串数量:
- 如果某个子串满足合法密码的条件,就将计数器
sum加1。 - 最后
sum的值就是合法子串的数量。
- 如果某个子串满足合法密码的条件,就将计数器
二、代码展示
//kfdhtshmrw4nxg#f44ehlbn33ccto#mwfn2waebry#3qd1ubwyhcyuavuajb#vyecsycuzsmwp31ipzah#catatja3kaqbcss2th
#include<bits/stdc++.h>
using namespace std;
// 函数fun用于判断从字符串s的begin位置到end位置的子串是否为合法密码
bool fun(string s, int begin, int end)
{
// 判断子串长度是否在8到16之间,如果不在这个范围,直接返回false
if ((end - begin + 1) < 8 || (end - begin + 1) > 16)
{
return false;
}
// sign1用于标记是否出现数字字符,sign2用于标记是否出现符号字符,初始化为0
int sign1 = 0, sign2 = 0;
// 遍历从begin到end的子串
for (int i = begin; i <= end; i++)
{
// 如果字符是数字字符('0'到'9'),则将sign1置为1,表示出现了数字字符
if (s[i] >= '0' && s[i] <= '9')
{
sign1 = 1;
}
// 这里原代码else if后面的分号是错误的,会导致判断符号字符的逻辑没有实际执行,应去掉分号
// 修正后:如果字符既不是字母(大写或小写)也不是数字,就认为是符号字符,将sign2置为1
else if (!(s[i] >= 'a' && s[i] <= 'z' || s[i] >= 'A' && s[i] <= 'Z'))
{
sign2 = 1;
}
}
// 如果同时出现了数字字符和符号字符,返回true,表示该子串是合法密码;否则返回false
if (sign1 && sign2) return true;
else return false;
}
int main()
{
string s = "kfdhtshmrw4nxg#f44ehlbn33ccto#mwfn2waebry#3qd1ubwyhcyuavuajb#vyecsycuzsmwp31ipzah#catatja3kaqbcss2th";
int n = s.length();
int sum = 0;
// 外层循环,i从0到n - 1,控制子串的起始位置
for (int i = 0; i < n; i++)
{
// 内层循环,j从0到n - 1,控制子串的结束位置
for (int j = 0; j < n; j++)
{
// 调用fun函数判断从位置i到位置j的子串是否为合法密码,如果是,将sum加1
if (fun(s, i, j)) sum++;
}
}
// 输出合法子串的数量
cout << sum;
return 0;
}三、感悟
在这里大家要注意一个点:子串和子序列的区别
子串是原字符串中连续的一段字符序列,数量有限,计算方式为n(n + 1)/2个(n为字符串长度);
子序列是原序列中不要求连续的字符构成的新序列,数量较多,有2^n个(n为序列长度,含空序列)。
去年大一的时候还是太菜了,当时第一眼看到这题以为考的是正则表达式,但其实这题做法非常简单,就是暴力枚举,两个for循环取字符串的一个区间,然后进行判断是否符合要求,若符合sum++,最后sum值就是答案了。
试题B:——选数概率

一、解题思路:

二、代码展示
//a=55,b=94,c=56
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a1=2585,a2=1540;
int b=2632;
int c=2632;
for(int i=b;i>1;i--)
{
if(a1%i==0&&c%i==0)
{
a1/=i;
c/=i;
}
if(a2%i==0&&b%i==0)
{
a2/=i;
b/=i;
}
}
cout<<"a1="<<a1<<" b="<<b<<endl;
cout<<"a2="<<a2<<" c="<<c;
} 三、感悟:
因为去年省赛被第二个填空题卡了好长时间,就差那一题没写出来,所以当时国赛做填空题第二题以为也会很难,当时看见题目也感觉很麻烦,但实际上这题非常简单,所以大家在比赛的时候一定不要有惧怕心理,一定要尝试去做每一题。
C——蚂蚁开会
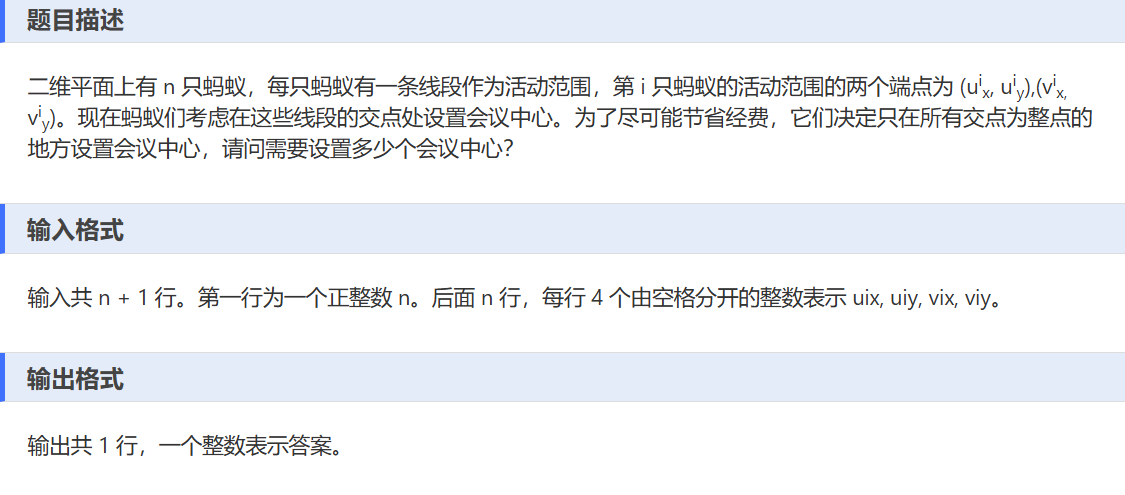
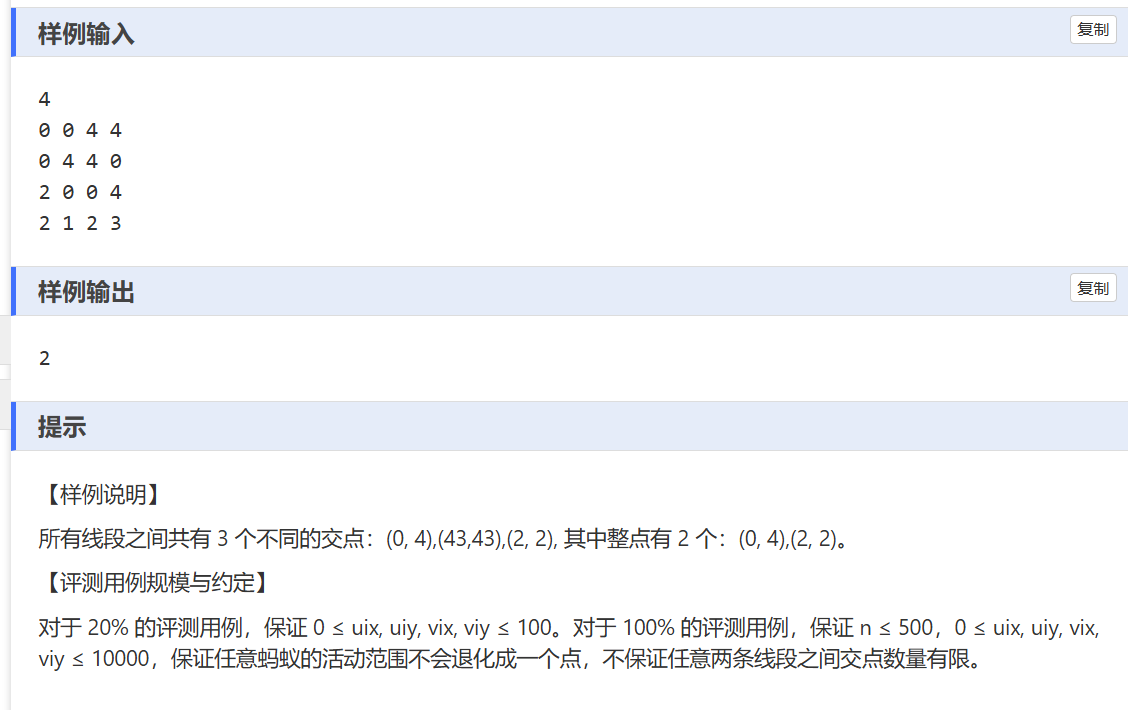
一、解题思路:
- 读取输入数据:首先读取蚂蚁的数量
n,然后依次读取每只蚂蚁活动范围线段的两个端点坐标(uix, uiy)和(vix, viy)。 - 处理每一条线段:对于每一条线段,求出其方向向量
(dx, dy),并将其化简(通过求最大公约数__gcd)。然后沿着这条线段,从一个端点开始,按照化简后的方向向量逐步遍历线段上的整点,并将这些整点记录下来。这里的依据是,如果线段两个端点是整点,那么线段上的整点可以通过从一个端点开始,按照一定的步长(由方向向量决定)来找到。 - 统计交点数量:遍历所有记录下来的整点,使用
map来统计每个整点出现的次数。因为只有当一个整点是两条线段的交点时(即出现次数为 2 ),才符合设置会议中心的要求,所以当某个整点出现次数为 2 时,将结果计数器ans加 1。 - 输出结果:最后输出符合要求的会议中心数量
ans。
二、代码展示
#include<bits/stdc++.h>
using namespace std;
int n;
const int N = 501;
// 定义PII类型,用于表示二维平面上的点(整数坐标)
typedef pair<int, int> PII;
// 定义结构体node,用于存储每条线段的两个端点坐标
struct node {
int x1, y1, x2, y2;
};
node a[N];
// 使用map来统计每个整点出现的次数,键是点(PII类型),值是出现次数(int类型)
map<PII, int> cnt;
PII points[N * N];
int num;
int main() {
// 读取蚂蚁的数量n
cin >> n;
for (int i = 0; i < n; i++) {
// 依次读取每只蚂蚁活动范围线段的两个端点坐标
cin >> a[i].x1 >> a[i].y1 >> a[i].x2 >> a[i].y2;
}
for (int i = 0; i < n; i++) {
int x1, y1, x2, y2;
x1 = a[i].x1;
y1 = a[i].y1;
x2 = a[i].x2;
y2 = a[i].y2;
// 计算线段在x和y方向上的变化量,即方向向量
int dx = x2 - x1;
int dy = y2 - y1;
// 对方向向量进行化简,通过求x和y方向变化量绝对值的最大公约数
int k = __gcd(abs(dx), abs(dy));
dx /= k;
dy /= k;
for (int i = 0;; i++) {
// 沿着线段方向,从一个端点开始计算线段上的整点坐标
int x = x1 + i * dx;
int y = y1 + i * dy;
// 将计算得到的整点坐标记录到points数组中
points[num++] = { x, y };
// 当到达线段的另一个端点时,停止遍历这条线段上的整点
if (x == x2 && y == y2) break;
}
}
int ans = 0;
// 遍历所有记录下来的整点
for (int i = 0; i < num; ++i) {
// 统计每个整点出现的次数
cnt[points[i]]++;
// 如果某个整点出现次数为2,说明它是两条线段的交点,符合设置会议中心的要求,将结果计数器ans加1
if (cnt[points[i]] == 2) ans++;
}
// 输出符合要求的会议中心数量
cout << ans;
}三、感悟:
通过这题可以看出来掌握stl容器的重要性,map和pair经常会搭配一起使用,大家如果想取得好成绩,一定要掌握并能做到熟练使用。
D——立定跳远
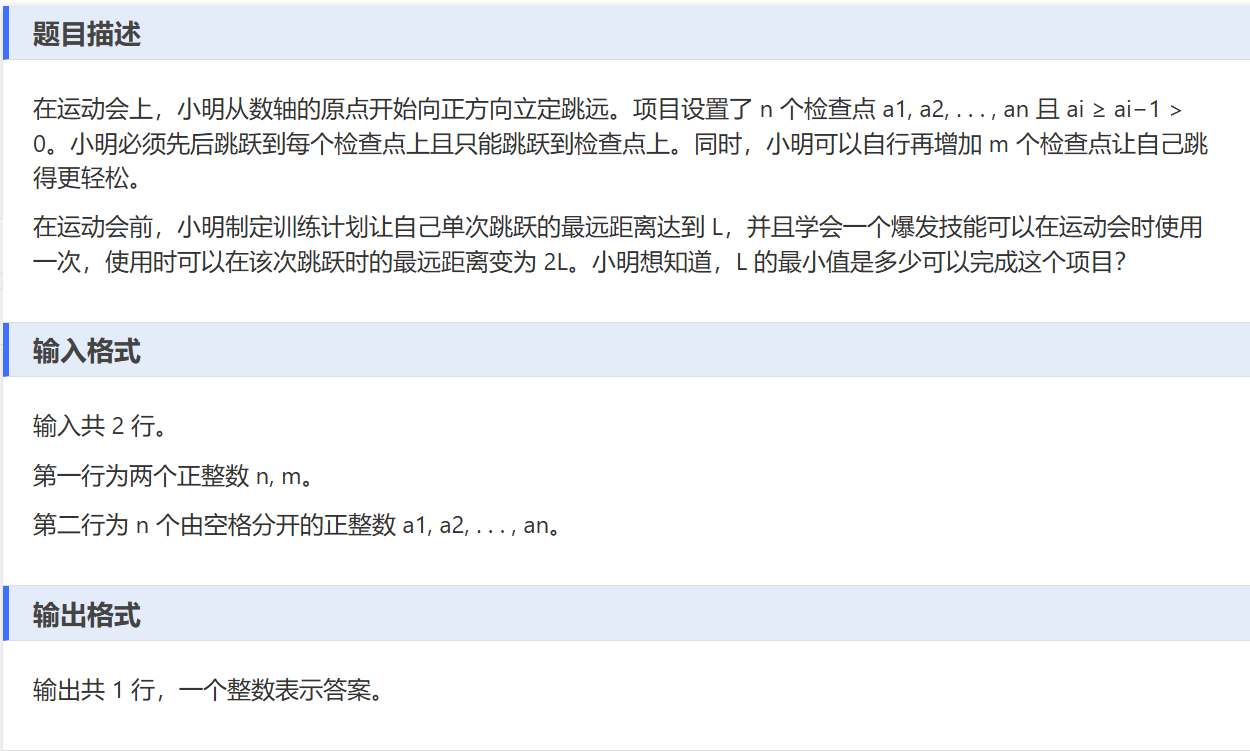
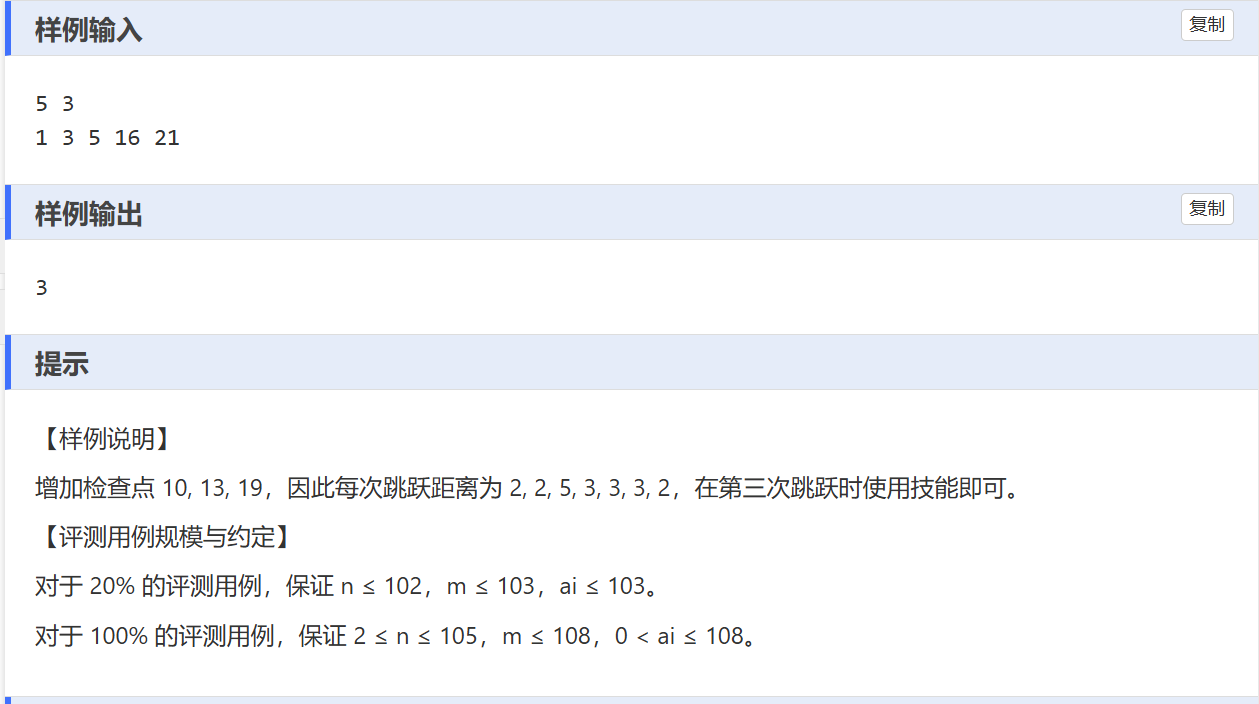
一、解题思路:
本题采用二分查找确定最小的 L 值。
check函数判断可行性:遍历相邻检查点距离,距离小于等于 L 可直接跳过;技能未用且距离小于等于 2L 则用技能跳过;否则计算需添加检查点数量,超 m 个则返回false,没超且循环结束则返回true。- 二分查找过程:左边界设为 1 ,右边界设较大值,每次取中间值
mid,用check函数判断。若可行,更新答案并缩小右边界;不可行则增大左边界,直至左边界大于右边界,得到最小 L 值。
二、代码展示
#include <bits/stdc++.h>
using namespace std;
// 检查在给定的 L 值下是否可以完成跳跃
bool check(int L, vector<int> a, int m) {
// 获取检查点的数量
int n = a.size();
// 标记技能是否已使用,初始化为未使用
int usedSkill = 0;
// 记录已添加的检查点数量,初始化为 0
int addedPoints = 0;
// 遍历相邻检查点之间的距离
for (int i = 1; i < n; i++) {
// 计算相邻两个检查点之间的距离
int dist = a[i] - a[i - 1];
// 如果当前距离小于等于 L,说明可以直接跳跃过去,不需要添加检查点或使用技能,直接跳过本次循环
if (dist <= L) continue;
// 如果技能还未使用,并且当前距离小于等于 2L,则使用技能完成这次跳跃
if (!usedSkill && dist <= 2 * L) {
// 标记技能已使用
usedSkill = 1;
// 跳过本次循环,继续处理下一段距离
continue;
}
// 如果当前距离大于 L 且无法使用技能,则计算需要添加的检查点数量
// 使用 (dist - 1) / L 确保在不能整除的情况下也能正确计算所需的检查点数量
int points = (dist - 1) / L;
// 将本次需要添加的检查点数量累加到 addedPoints 中
addedPoints += points;
// 如果添加的检查点数量超过了允许的 m 个,说明在当前 L 值下无法完成跳跃,返回 false
if (addedPoints > m) return false;
}
// 如果循环结束后都没有返回 false,说明在当前 L 值下可以完成跳跃,返回 true
return true;
}
int main() {
int n, m;
// 读取检查点的数量 n 和可增加的检查点数量 m
cin >> n >> m;
// 创建一个长度为 n 的向量 a 来存储检查点的位置
vector<int> a(n);
// 依次读取每个检查点的位置
for (int i = 0; i < n; i++) {
cin >> a[i];
}
// 初始化二分查找的左边界,最小的跳跃距离为 1
int left = 1;
// 初始化二分查找的右边界,根据题目中检查点位置的范围设定一个较大值
int right = 1e8;
// 初始化答案为右边界
int ans = right;
// 当左边界小于等于右边界时,继续进行二分查找
while (left <= right) {
// 计算中间值,避免使用 (left + right) / 2 可能导致的整数溢出问题
int mid = left + (right - left) / 2;
// 调用 check 函数检查在当前 mid 值下是否可以完成跳跃
if (check(mid, a, m)) {
// 如果可以完成跳跃,说明 mid 是一个可能的答案,更新 ans
ans = mid;
// 尝试更小的 L 值,将右边界更新为 mid - 1
right = mid - 1;
} else {
// 如果不能完成跳跃,说明 mid 太小,需要尝试更大的 L 值,将左边界更新为 mid + 1
left = mid + 1;
}
}
// 输出最终找到的最小的 L 值
cout << ans << endl;
return 0;
}
三、感悟:
当时在赛场做题的时候想着就是暴力,把每两个检查点之间的距离都放在multiset中,然后类似省赛爬山的思路写,当时并没有想到是去靠二分去找到最合适的L
E——最小字符串
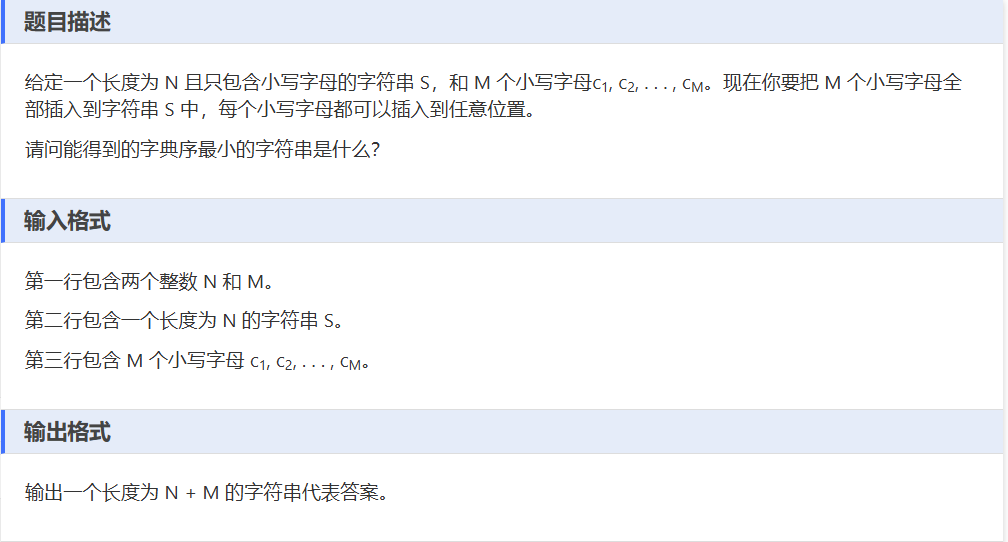
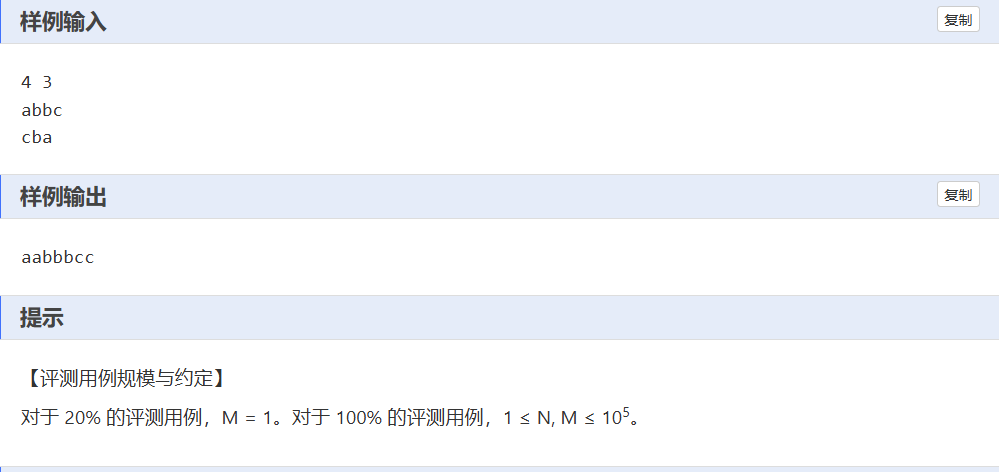
一、解题思路:
- 对要插入的 M 个字母字符串 s2 进行排序,使其字典序最小。
- 分别预处理字符串 s1 和 s2 ,记录每个字符后面第一个不同字符的位置(数组 a 记录 s1 ,数组 b 记录 s2 ),方便后续比较。
- 同时遍历 s1 和 s2 ,按字典序规则插入字符:若 s1 当前字符小,输出 s1 当前字符;若 s2 当前字符小,输出 s2 当前字符;若相等,比较二者后续第一个不同字符,按字典序输出。
- 遍历结束后,将剩余未处理的 s1 或 s2 字符输出。
二、代码展示
#include<bits/stdc++.h>
using namespace std;
const int N = 100001;
int a[N], b[N];
int main()
{
int n, m;
// 读取字符串s1的长度n和要插入字母的数量m
cin >> n >> m;
string s1, s2;
// 读取原始字符串s1和要插入的字母字符串s2
cin >> s1 >> s2;
// 对字符串s2进行排序,使其字典序最小
sort(s2.begin(), s2.end());
// 预处理数组a,记录s1中每个字符后面第一个不同字符的位置
a[n - 1] = n;
for (int i = n - 2; i >= 0; i--)
{
if (s1[i] == s1[i + 1])
{
a[i] = a[i + 1];
}
else
{
a[i] = i + 1;
}
}
// 预处理数组b,记录s2中每个字符后面第一个不同字符的位置
b[m - 1] = m;
for (int i = m - 2; i >= 0; i--)
{
if (s2[i] == s2[i + 1])
{
b[i] = b[i + 1];
}
else
{
b[i] = i + 1;
}
}
int i = 0, j = 0;
// 同时遍历s1和s2,按字典序规则插入字符
while (i < n && j < m)
{
if (s1[i] < s2[j])
{
cout << s1[i++];
}
else if (s1[i] == s2[j])
{
int ii = a[i];
int jj = b[j];
char temp1, temp2;
if (ii == n) {
temp1 = s1[i];
}
else {
temp1 = s1[ii];
}
if (jj == m) {
temp2 = s2[j];
}
else {
temp2 = s2[jj];
}
if (temp1 < temp2) {
cout << s1[i++];
}
else if (temp1 > temp2) {
cout << s2[j++];
}
else {
cout << s1[i++];
cout << s2[j++];
}
}
else
{
cout << s2[j++];
}
}
// 输出s1中剩余未处理的字符
while (i < n)
{
cout << s1[i++];
}
// 输出s2中剩余未处理的字符
while (j < m)
{
cout << s2[j++];
}
}三、感悟:
当时第一遍做这一题的时候,想的很简单,直接判断s1和s2当前下标位置i,j所对应的字符大小,依次比较打印较小字符,但是有一点我没有考虑到,如果当前两个下标位置的字符相同,那先打印谁,这个时候根据题目意思,打印字典序最小的字符串,所以需要判断这两个字符后面紧接着一个不同的字符谁更小,谁就优先输出。
F——数位翻转
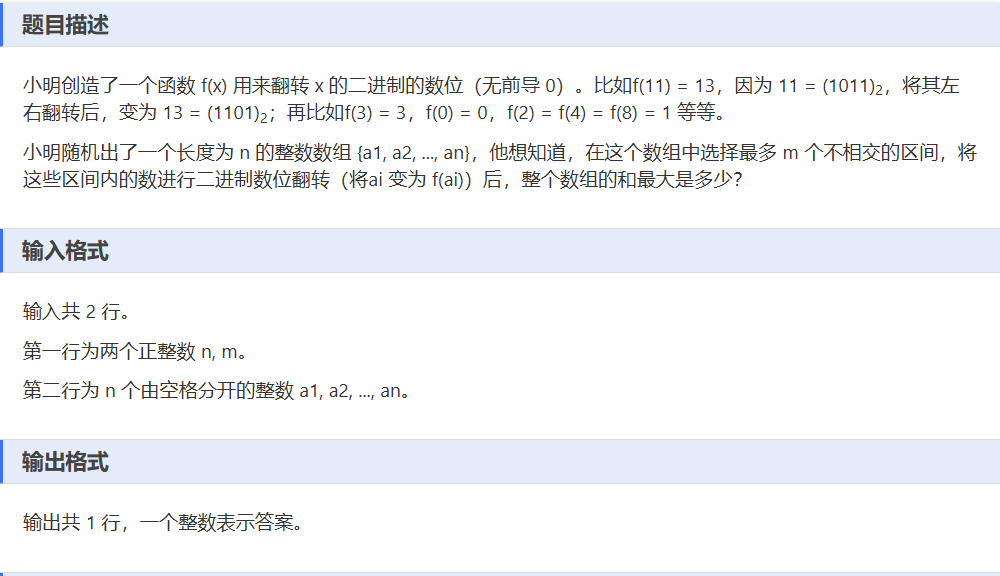
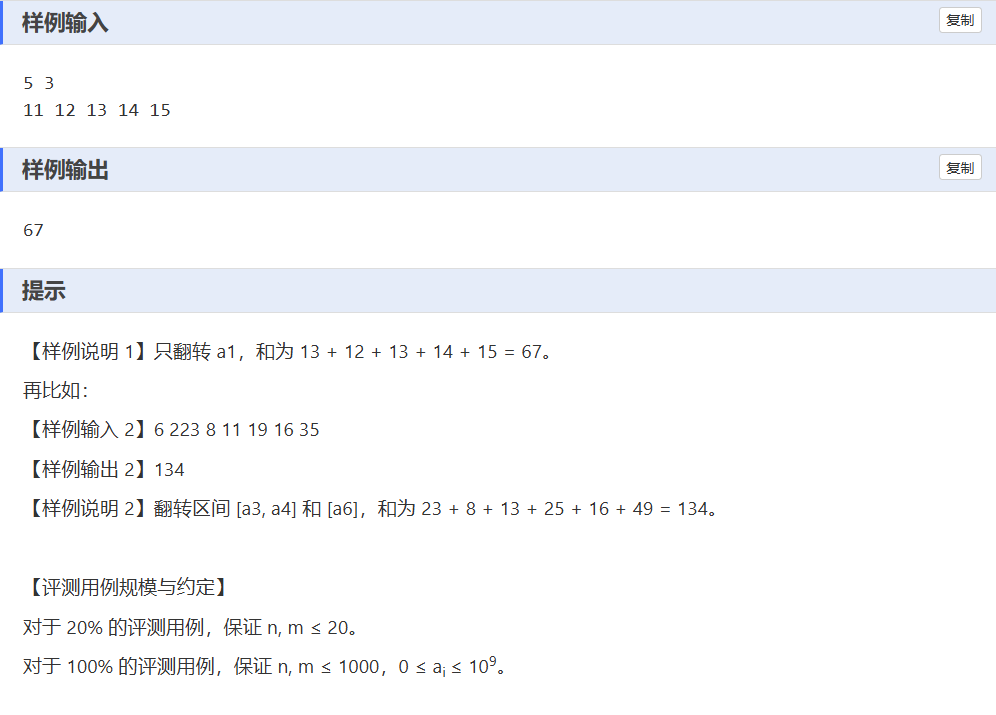
一、解题思路:
- 先定义函数
fun,将数组元素转为二进制并翻转,计算翻转后的值,得到翻转前后的差值数组c。 - 遍历差值数组
c,找出其中值非负的连续区间,将这些区间的起始、结束位置及区间内差值总和记录到结构体数组v中。 - 对结构体数组
v按区间总和从大到小排序。 - 取前
min(m, v.size())个区间,将这些区间内的元素更新为翻转后的值。 - 计算更新后数组元素总和并输出。
二、代码展示
#include<bits/stdc++.h>
typedef long long int ll;
using namespace std;
const int N = 1001;
ll a[N], b[N], c[N];
int n, m;
// 定义结构体node,记录区间起始位置i、结束位置j和区间内差值总和sum
struct node {
ll i, j, sum;
};
vector<node> v;
// 比较函数,用于对结构体数组按sum从大到小排序
bool cmp(node a, node b) {
return a.sum > b.sum;
}
// 函数fun将a[i]转为二进制并翻转,计算翻转后的值存到b[i]
void fun(ll i) {
ll temp = a[i];
string s;
while (temp) {
s = (char)(temp % 2 + '0') + s;
temp /= 2;
}
ll k = 1;
ll sum = 0;
ll len = s.size();
for (ll j = 0; j < len; j++) {
if (s[j] == '1') sum += k;
k *= 2;
}
b[i] = sum;
}
int main() {
cin >> n >> m;
for (ll i = 0; i < n; i++) {
cin >> a[i];
fun(i);
// 计算翻转后与翻转前的差值存到c[i]
c[i] = b[i] - a[i];
}
ll begin = 0;
ll end = 0;
ll sum = 0;
for (ll i = 0; i < n; i++) {
if (c[i] >= 0) {
end = i;
sum += c[i];
}
else if (c[i] < 0) {
if (sum > 0) {
node temp;
temp.i = begin;
temp.j = end;
temp.sum = sum;
v.push_back(temp);
sum = 0;
}
begin = i + 1;
end = i + 1;
}
}
if (sum > 0) {
node temp;
temp.i = begin;
temp.j = end;
temp.sum = sum;
v.push_back(temp);
}
// 对记录区间信息的结构体数组v按sum从大到小排序
sort(v.begin(), v.end(), cmp);
int vv = v.size();
// 取前min(m, vv)个区间
ll minn = min(m, vv);
for (ll i = 0; i < minn; i++) {
node temp = v[i];
for (ll k = temp.i; k <= temp.j; k++) {
// 将区间内元素更新为翻转后的值
a[k] = b[k];
}
}
sum = 0;
for (ll i = 0; i < n; i++) sum += a[i];
// 输出更新后数组元素总和
cout << sum;
return 0;
}三、感悟:
这一题纯就是考察大家的动手能力,算法倒是没考察什么,主要要实现的功能太多,你得先得到每个数字的二进制翻转后的十进制,然后还要得到与对应的初始十进制的差值,看看是否是正数,正数就是增加,然后看看有几个增加区间,然后根据增加的量进行排序,然后确定用哪几个区间才能和增加的最多,所以大家平时一定要多做题,锻炼自己的动手能力。
G——数星星
一、解题思路:
- 预处理与初始化:读入树的节点数
n后,初始化阶乘数组fac和逆元数组inv,用于后续计算组合数。接着读入树的边,统计每个节点的度数deg,再读入区间[l, r]。 - 计算星星数量:
- 单独处理节点数为1和2的星星数量,节点数为1的星星有
n颗,节点数为2的星星有n - 1颗。 - 对于每个度数大于等于2的节点
i,枚举以它为中心的星星节点数j(3到deg[i] + 1),利用组合数计算能构成的星星数量并累加到ans[j]。
- 单独处理节点数为1和2的星星数量,节点数为1的星星有
- 统计结果:遍历区间
[l, r],将对应节点数的星星数量ans[i]累加起来,对mod取模后输出。
二、代码展示
#include <bits/stdc++.h>
#define MOD 1000000007
using namespace std;
typedef long long LL;
const int MAXN = 1e5 + 10;
int n, deg[MAXN]; // n 表示节点数量,deg 数组记录每个节点的度数
int l, r; // l 和 r 分别为区间的左右边界
LL fac[MAXN], inv[MAXN], starCnt[MAXN]; // fac 存储阶乘,inv 存储逆元,starCnt 存储不同节点数的星星数量
// 快速幂函数,计算 a 的 b 次幂对 p 取模的结果
// 作用:高效地计算幂运算,避免直接计算幂导致的时间复杂度高的问题
// 原理:利用二进制拆分指数,将幂运算的时间复杂度从 O(b) 降低到 O(log b)
LL fastPow(LL a, LL b, LL p) {
LL res = 1;
while (b) {
if (b & 1) res = res * a % p; // 如果 b 的二进制当前位为 1,将当前的 a 累乘到结果中
a = a * a % p; // a 自乘,为下一位二进制做准备
b >>= 1; // b 右移一位,处理下一位二进制
}
return res;
}
// 初始化阶乘和逆元数组
// 作用:为后续计算组合数做准备,组合数计算需要用到阶乘和逆元
// 原理:阶乘通过递推计算,逆元通过费马小定理(a^(p - 2) ≡ a^(-1) (mod p),p 为质数)结合快速幂计算
void init() {
fac[0] = inv[0] = 1;
for (int i = 1; i <= n; ++i) {
fac[i] = fac[i - 1] * i % MOD; // 递推计算阶乘
}
for (int i = 1; i <= n; ++i) {
inv[i] = fastPow(fac[i], MOD - 2, MOD); // 利用费马小定理和快速幂计算逆元
}
}
// 计算组合数 C(n, m)
// 作用:根据组合数公式 C(n, m) = n! / (m! * (n - m)!) 计算组合数,同时取模避免溢出
// 原理:利用预处理好的阶乘和逆元,直接代入公式计算
LL comb(int n, int m) {
return fac[n] * inv[m] % MOD * inv[n - m] % MOD;
}
int main() {
cin >> n;
init();
for (int i = 1; i < n; ++i) {
int u, v;
cin >> u >> v;
++deg[u], ++deg[v]; // 统计节点的度数,因为星星图的中心节点度数影响能构成的星星数量
}
cin >> l >> r;
starCnt[1] = n, starCnt[2] = n - 1; // 初始化节点数为 1 和 2 的星星数量
// 节点数为 1 的星星,每个节点都可以单独构成一个星星,所以有 n 个
// 节点数为 2 的星星,每条边都可以构成一个星星,树有 n - 1 条边,所以有 n - 1 个
for (int i = 1; i <= n; ++i) {
if (deg[i] >= 2) {
// 当节点度数大于等于 2 时,该节点有可能作为星星图的中心
for (int j = 3; j <= deg[i] + 1; ++j) {
// j 表示星星图的节点数,从 3 开始,最大为该节点度数加 1
// 以节点 i 为中心,选择 j - 1 条边构成星星图,根据组合数原理,有 C(deg[i], j - 1) 种选择方式
starCnt[j] = (starCnt[j] + comb(deg[i], j - 1)) % MOD;
}
}
}
LL sum = 0;
for (int i = l; i <= r; ++i) {
sum = (sum + starCnt[i]) % MOD; // 累加区间 [l, r] 内星星的数量
}
cout << sum << endl;
return 0;
}三、感悟:
当时在考场上并没有想出来,这个是看了借鉴了其他作者的思路才理解的,的确不好想,需要懂一些数论知识。
H——套手镯
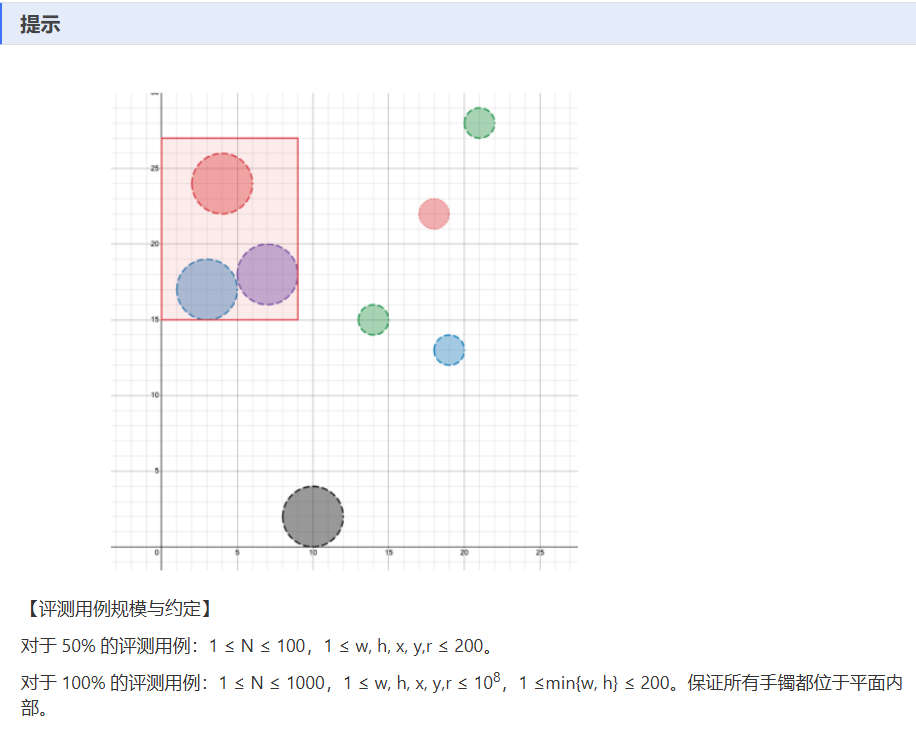
一、解题思路:
- 定义函数
work来计算在给定矩形框位置(左上角坐标为(x0, y0),宽为w,高为h)时,框内手镯的数量。 - 在
main函数中,读取手镯数量n、矩形框宽w和高h,以及每个手镯的圆心坐标和半径。 - 通过多次调用
work函数,以手镯的圆心坐标结合半径来枚举矩形框可能的放置位置(共 8 种不同的起始位置枚举方式 )(矩形框有两周放置方式,然后手环分别在四个角落,所以是8中枚举方式),计算每种情况下框内手镯数量,并更新最大手镯数量ans。
二、代码展示
#include <bits/stdc++.h>
using namespace std;
typedef long long int ll;
ll ans,n, w, h;
const int N=1001;
vector<int> x(N), y(N), r(N);
void work(int x0, int y0, int h, int w) {
ll x1 = x0 + h, y1 = y0 + w;
ll res = 0;
for (int i = 0; i < n; i++) {
if (x[i] - r[i] >= x0 && x[i] + r[i] <= x1) {
if (y[i] - r[i] >= y0 && y[i] + r[i] <= y1) {
res++;
}
}
}
ans = max(ans, res);
};
int main() {
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
cin >> n >> w >> h;
for (int i = 0; i < n; i++) {
cin >> x[i] >> y[i] >> r[i];
}
for (int i = 0; i < n; i++) {
work(x[i] - r[i], y[i] - r[i], h, w);
work(x[i] - r[i], y[i] - r[i], w, h);
work(x[i] + r[i] - h, y[i] + r[i] - w, h, w);
work(x[i] + r[i] - w, y[i] + r[i] - h, w, h);
work(x[i] - r[i], y[i] + r[i] - h, w, h);
work(x[i] - r[i], y[i] + r[i] - w, h, w);
work(x[i] + r[i] - h, y[i] - r[i], h, w);
work(x[i] + r[i] - w, y[i] - r[i], w, h);
}
cout<<ans;
return 0;
}三、感悟:
这种思路有些情况没有考虑到,并不是一定存在有手镯在矩形方框的四个角落中,只能过64%的测试点,求大神指教
I——跳石头
一、解题思路:
直接暴力,依次以每个点为出发点来试(能过60%)
- 定义状态与搜索规则:从每一块石头出发,根据跳跃规则(跳到第\(j + c_j\)块石头或者第2j块石头 ,需满足相应条件 )进行深度优先搜索。在搜索过程中,用集合记录经过石头的权值。
- 遍历起始点:遍历每一块石头作为起始点,分别进行深度优先搜索,每次搜索完更新当前能得到的最大权值数量(即集合大小 )。
- 得出结果:遍历完所有起始点后,最终得到的最大权值数量就是小明最多能获得的分数。
二、代码展示
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1000010;
int stoneVal[N], n; // stoneVal数组存储每块石头的权值,n为石头数量
set<int> scoreSet; // scoreSet集合用于记录经过石头的权值
// u表示当前所在石头的编号
void fun(int u) {
// 如果当前石头编号超过了总石头数,结束本次搜索
if (u > n) return;
// 如果能跳到2 * u 号石头
if (u * 2 <= n) {
// 将2 * u 号石头的权值加入集合
scoreSet.insert(stoneVal[u * 2]);
// 从2 * u 号石头继续搜索
fun(u * 2);
}
// 如果能跳到u + stoneVal[u] 号石头
if (u + stoneVal[u] <= n) {
// 将u + stoneVal[u] 号石头的权值加入集合
scoreSet.insert(stoneVal[u + stoneVal[u]]);
// 从u + stoneVal[u] 号石头继续搜索
fun(u + stoneVal[u]);
}
return;
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> stoneVal[i]; // 读取每块石头的权值
}
int maxScore = -1; // 记录最大分数,初始化为 -1
for (int i = 1; i <= n; i++) {
scoreSet.clear(); // 清空集合,准备从新的起始点开始检测
scoreSet.insert(stoneVal[i]); // 将起始石头的权值加入集合
fun(i); // 从第i块石头开始进行深遍历
maxScore = max(maxScore, (int)scoreSet.size()); // 更新最大分数
}
cout << maxScore << endl;
return 0;
}
三、感悟:
因为题目比较靠后,可能做到这里时间紧剩无几,不必追求正解(大神除外),它是可遇而不可求的,在赛场上如果没有想到正解先用暴力做了拿到一部分分数再说
J——最长回文前后缀
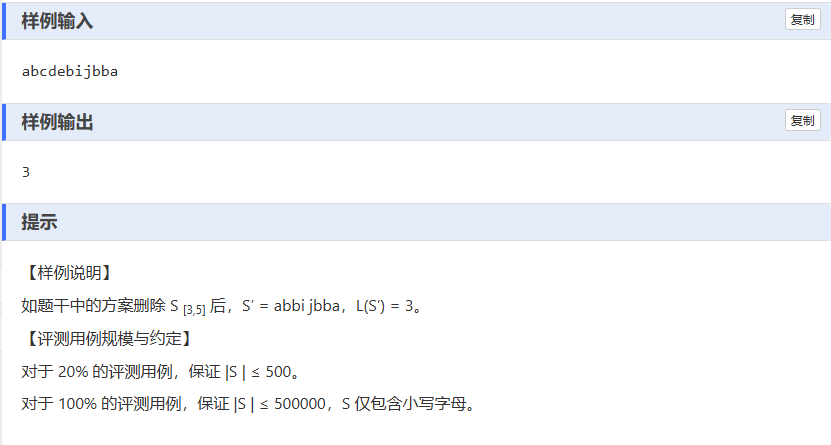
一、解题思路:
本题的目标是找出给定字符串经过删除中间某一子串后,其前后缀能构成的最长回文串的长度。解题的整体思路可以分为以下几个步骤:
- 预处理:对输入的字符串进行初步处理,先找出原字符串中原本就对称的前后缀,记录下这部分对称前后缀的长度。
- 提取中间子串:将原本对称的前后缀删除后,得到中间的子串。
- 字符串哈希与二分查找:对于中间子串及其反转后的字符串,使用字符串哈希来快速判断不同长度的前后缀是否相等。通过二分查找找出前后缀能构成的最长相等长度。
- 结果计算:将原本对称的前后缀长度与中间子串及其反转后得到的最长前后缀相等长度中的最大值相加,得到最终结果。
二、代码展示
#include <bits/stdc++.h>
// 宏定义rep,用于正向循环,从a到n
#define rep(i,a,n) for(int (i)=(a);(i)<=(n);(i)++)
// 宏定义pre,用于反向循环,从a到n
#define pre(i,a,n) for(int (i)=(a);(i)>=(n);(i)--)
// 定义无符号长整型ull
#define ull unsigned long long
// 定义长整型int
#define int long long
using namespace std;
const int N = 1000000 + 10;
// 哈希基数,911是质数,用于防止哈希冲突
const ull Hash = 911;
// ha数组存储前缀哈希值,hb数组存储后缀哈希值,pw数组存储哈希基数的幂次方
ull ha[N], hb[N], pw[N];
// 获取区间[l, r]的字符串哈希值
ull gethash(ull t[], int l, int r)
{
// 利用前缀哈希值计算区间哈希值,自然溢出省去取模操作
return t[r] - t[l - 1] * pw[r - l + 1];
}
// 求解函数,计算字符串s中前后缀能构成的最长相等长度
int solve(string s)
{
int n = s.size();
// 在字符串s前插入一个空格,使下标从1开始
s = " " + s;
// 初始化哈希基数的0次幂为1
pw[0] = 1;
// 预处理哈希基数的幂次方数组和前缀、后缀哈希值数组
rep(i, 1, n)
{
// 计算哈希基数的i次幂
pw[i] = pw[i - 1] * Hash;
// 计算前缀哈希值
ha[i] = ha[i - 1] * Hash + s[i];
// 计算后缀哈希值
hb[i] = hb[i - 1] * Hash + s[n - i + 1];
}
// 记录最大的前后缀相等长度
int mx = 0;
// 枚举所有可能的起始位置
rep(i, 1, n)
{
// 二分查找的左右边界,r初始为剩余长度的一半
int l = 1, r = (n - i) / 2;
while (l <= r)
{
// 取中间长度
int mid = l + r >> 1;
// 判断长度为mid的前后缀哈希值是否相等
if (gethash(ha, 1, mid) == gethash(hb, i + 1, i + mid))
// 若相等,尝试更大的长度
l = mid + 1;
else
// 若不相等,尝试更小的长度
r = mid - 1;
}
// 更新最大长度
mx = max(mx, r);
}
return mx;
}
signed main()
{
// 关闭输入输出流的同步,提高输入输出效率
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
string s;
cin >> s;
int n = s.size();
// 左右指针,用于找出原本对称的前后缀
int l = 0, r = n - 1;
// 找出原本对称的前后缀
while (s[l] == s[r] && l <= r) l++, r--;
// 如果l > r,说明整个字符串是回文串,直接输出长度
if (l > r) cout << l;
else
{
// 取出删掉前后缀的中间子串
s = s.substr(l, r - l + 1);
// 复制中间子串
string t = s;
// 反转中间子串
reverse(t.begin(), t.end());
// 计算结果,取中间子串及其反转后得到的最长前后缀相等长度的最大值,再加上原本对称的前后缀长度
cout << max(solve(s), solve(t)) + l;
}
return 0;
}三、感悟:
这一题是借鉴其他人的,大家如果有兴趣可以去看一下这位大神讲的:(这题我后期会在国赛前更新出我自己的做法,现在时间太紧了,没有时间做题了,大家见谅啦)https://www.luogu.com.cn/problem/solution/P10915

总结:
祝今年大家都可以取得理想的成绩,然后在国赛相见,弥补之前的遗憾。
希望大家可以多参加一些算法比赛,就我而言,我认为算法的学习是一种数学思维能力的培养。
不同算法比赛赛制不同,目前主要分为:OI赛制,IOI赛制,ACM赛制。
ACM 赛制
- 提交后反馈:提交代码后会即时得到评判结果,能看到 “通过(Accepted)”“运行错误(Runtime Error)”“答案错误(Wrong Answer)” 等,但看不到错误的测试样例 。
- 评分标准:每道题有多个测试点,需通过全部测试点才算得分。未通过时多次提交会有罚时(一般每次 20 分钟 ),最终排名依据解题数量,解题数相同则比较总用时(答题时间 + 罚时 ),总用时少的队伍排名靠前。
- 常见比赛:ICPC(国际大学生程序设计竞赛) 、CCPC(中国大学生程序设计竞赛) 、Codeforces 部分比赛、AtCoder 部分比赛,leetcode周赛,传智杯等 。
OI 赛制
- 提交后反馈:提交题目后没有任何反馈,比赛过程中也看不到实时排名 。
- 评分标准:每道题含多个测试点,按通过测试点的数量获得相应分数,不限制提交次数,即使提交错误也无惩罚,最终分数仅以最后一次提交为准 ,赛后按总得分排名。
- 常见比赛:NOI全国青少年信息学奥林匹克竞赛、蓝桥杯大赛软件组、全国高校计算机能力挑战赛 的比赛 。
IOI 赛制
- 提交后反馈:每道题提交后有反馈,能看到 “通过”“运行错误”“答案错误” 等结果,甚至可实时看到每道题得分情况,但看不到错误的测试样例 。
- 评分标准:每道题依据通过测试点的数量计分 ,不限制提交次数,提交错误无惩罚,仅以最后一次提交为准 ,比赛过程中一般可看到实时排名(考试形式可能看不到 ),最终按总得分排名。
- 常见比赛:CCF CSP认证考试 、CCF CCSP、PAT(浙江大学计算机程序设计能力测试) 、团体程序设计天梯赛 、RAICOM 机器人编程大赛等 。
三者区别总结
- 比赛反馈与排名:ACM 赛制提交后即时知结果和排名;OI 赛制比赛中无反馈和排名信息;IOI 赛制提交有即时反馈和实时排名(部分情况除外 )。
- 评分侧重:ACM 赛制注重题目是否完全正确及解题速度;OI 赛制关注通过测试点数量得部分分;IOI 赛制结合前两者,既看结果正确也有部分分机制 。

















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









