










整个引擎代码在github上,地址为:https://github.com/sun2043430/RegularExpression_Engine.git
nullable, firstpos, lastpos, followpos函数介绍
接着上两篇文章
《正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——1 概述》
《正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——2 构造抽象语法树》
本篇将讲解对抽象语法树上的每一个节点计算对应的4个函数:nullable, firstpos, lastpos, followpos。
鉴于龙书已经对这一部分的理论和实现步骤进行了详细文字、图表描述。我就不在赘述了。只摘取其中一些重要的概念、难点谈谈我的理解。并结合具体的例子来演示一下函数的计算过程。
nullable, firstpos, lastpos, followpos这4 个函数在龙书上是这样解释的:

这4个函数里面,其中nullable函数是为计算firstpos, lastpos函数而做准备的。而firstpos, lastpos函数又是为计算followpos函数而做准备的。
实际上在DFA中,只有对于星号运算符的节点nullable函数才返回TRUE,因为星号运算符可以匹配空串。
对于nullable, firstpos函数的求法,龙书上给出的表格如下:
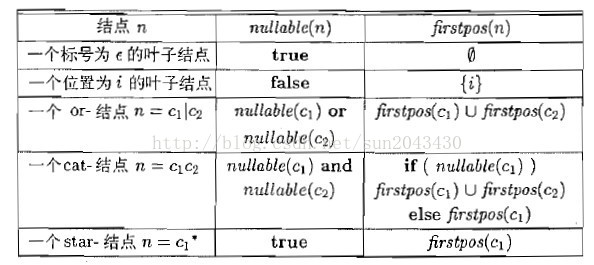
对于lastpos的求法,和firstpos的求法类似,差别只在对于cat结点时候,求法为
if( nullable(c2) )
{ lastpos(c1) 并上 lastpos(c2) }
else { lastpos(c2) }。
计算完firstpos和lastpos函数后,就可以计算最后的followpos函数了。followpos函数的简单理解就是,对于一个结点P,哪些结点是可能出现在节点P后面的,所有可能出现在P后面(紧随其后,相邻)的节点构成的集合就是followpos。
只有在遇到cat节点和star节点(星号节点)才有必要计算followpos值:
1. cat节点表示两个节点的连接,所以两个节点中,后一个节点的firstpos集合是前一个节点的lastpos集合中每一个节点的followpos集合。
2. 对于star节点,考虑到其后可以跟随自身,所以自身节点的firstpos集合是自身节点的lastpos集合中每一个节点的followpos集合。
在具体代码实现中,nullable可以用一个布尔变量表示,firstpos, lastpos, followpos为3个向量(或链表):
BOOL m_bNullAble;
vector<CNodeInTree*> m_vecFirstPos;
vector<CNodeInTree*> m_vecLastPos;
vector<CNodeInTree*> m_vecFollowPos;
结合具体实例讲解4个函数的计算方法
上面说的都很抽象,我们结合具体的实例来说明对应的值和集合,对于正则表达式(a|b)*abb,共有5个叶子节点,5个非叶子节点。构成的语法树如下:

我们来填写一下对应的集合,需要说明的一点是,在计算这些值和集合的时候,是对整个语法树进行深度优先遍历的,所以会先处理叶子节点再处理中间节点,最后才到整个树的根节点。
我们按照遍历过程中节点被处理的先后顺序列出下表:
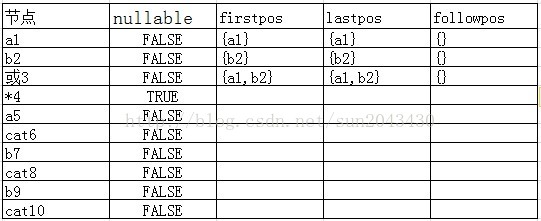
请注意,在表中,处理完 a1,a2,或3 这3个节点后,这3个节点的followpos集合都是空的,因为可以跟随的节点还不知道。
接下来在处理*4节点时,因为在前面我们说过star节点需要计算followpos集合。具体的计算方法是这样的,遍历*4节点的lastpos集合,对其中的每一个节点N(也就是a1,a2两个节点),设置N的followpos节点为*4节点的firstpos集合。也就是说a1节点的followpso集合为{a1,a2},a2节点的followpso集合也是{a1,a2}。处理完成之后的结果如下表:
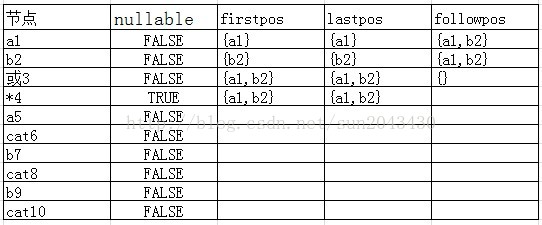
可以看出,在处理followpos集合时,并不是处理 *4 节点本身的followpos集合,而是对 *4 节点的firstpos集合中每一个节点进行处理。我们接着往下处理,看看cat节点的情况。
当处理到cat6节点时,其firstpos集合和lastpos集合如下:
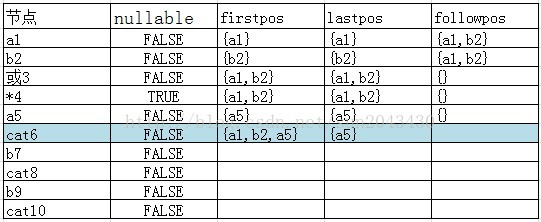
因为cat6节点表示*4节点和a5节点的连接。所以cat6节点的firstpos集合首先要包含*4节点的firstpos集合(也就是a1,a2),然后又因为*4节点的nullable函数为TRUE(star运算符可匹配空串),所以还得加上a5节点的firstpos集合(a5节点)。所以cat6节点的firstpos集合为{a1,a2,a5}。
cat6节点的lastpos集合就是a5节点的lastpos集合。且因为a5节点的nullable函数为FALSE,所以不用再加上*4节点的lastpos集合了。最终得到的结果就是上面的表格。
下面我们在来看如何在cat节点处处理followpos集合。
还是根据我们前面提到的,"cat节点表示两个节点的连接,所以两个节点中,后一个节点的firstpos集合是前一个节点的lastpos集合中每一个节点的followpos集合。"
具体在这里,也就是对于cat6节点所连接的两个节点来说,将前一个节点*4节点的lastpos集合({a1,a2})取过来,对里面的每一个节点(a1,a2)设置followpos集合。用什么来设置followpos集合呢?用后一个节点(a5节点)的firstpos集合({a5})来设置。也就是说,在a1节点和a2节点的followpos集合中再加入a5节点。处理完毕后的结果见下表:
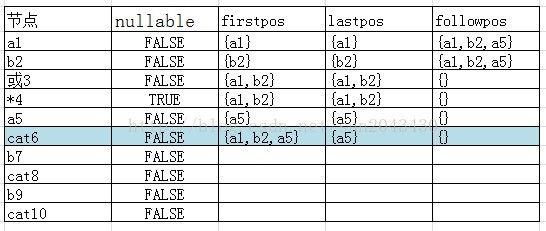
可以看出,在对cat6进行followpos函数的处理时,改变的是*4节点的firstpos集合中的节点(a1,a2)的followpos集合,和cat6节点自身的followpos集合无关。
接下来的节点处理情况和以上过程类似,最终得到的结果如下表:
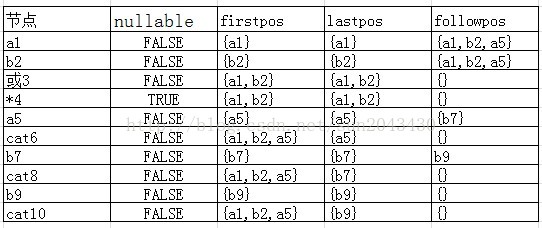
至此,结合实例讲解的4个函数计算方法就讲完了。下一章将介绍DFA的构建。
整个引擎代码在github上,地址为:https://github.com/sun2043430/RegularExpression_Engine.git
关键代码
以下是计算本文中4个函数的关键代码
BOOL CNodeInTree::CalculateFunction(CNodeInTree *pNode)
{
BOOL bRet = FALSE;
if (!pNode)
return TRUE;
CHECK_BOOL ( CalculateFunction(pNode->m_Node1) );
CHECK_BOOL ( CalculateFunction(pNode->m_Node2) );
switch (pNode->m_pToken->GetType())
{
case eType_END:
case eType_NORMAL:
case eType_WILDCARD:
pNode->m_bNullAble = FALSE;
try
{
pNode->m_vecFirstPos.push_back(pNode);
pNode->m_vecLastPos.push_back(pNode);
}
catch (...)
{
goto Exit0;
}
break;
case eType_STAR:
pNode->m_bNullAble = TRUE;
CHECK_BOOL ( AppendVector(pNode->m_vecFirstPos, pNode->m_Node1->m_vecFirstPos) );
CHECK_BOOL ( AppendVector(pNode->m_vecLastPos, pNode->m_Node1->m_vecLastPos) );
CHECK_BOOL ( CalcFollowPos(pNode) );
break;
case eType_UNION:
pNode->m_bNullAble = pNode->m_Node1->m_bNullAble || pNode->m_Node2->m_bNullAble;
CHECK_BOOL ( AppendVector(pNode->m_vecFirstPos, pNode->m_Node1->m_vecFirstPos) );
CHECK_BOOL ( AppendVector(pNode->m_vecFirstPos, pNode->m_Node2->m_vecFirstPos) );
CHECK_BOOL ( AppendVector(pNode->m_vecLastPos, pNode->m_Node1->m_vecLastPos) );
CHECK_BOOL ( AppendVector(pNode->m_vecLastPos, pNode->m_Node2->m_vecLastPos) );
break;
case eType_CONCAT:
pNode->m_bNullAble = pNode->m_Node1->m_bNullAble && pNode->m_Node2->m_bNullAble;
// firstpos(n)
CHECK_BOOL ( AppendVector(pNode->m_vecFirstPos, pNode->m_Node1->m_vecFirstPos) );
if (pNode->m_Node1->m_bNullAble)
{
CHECK_BOOL ( AppendVector(pNode->m_vecFirstPos, pNode->m_Node2->m_vecFirstPos) );
}
// lastpos(n)
if (pNode->m_Node2->m_bNullAble)
{
CHECK_BOOL ( AppendVector(pNode->m_vecLastPos, pNode->m_Node1->m_vecLastPos) );
}
CHECK_BOOL ( AppendVector(pNode->m_vecLastPos, pNode->m_Node2->m_vecLastPos) );
CHECK_BOOL ( CalcFollowPos(pNode) );
break;
default:
goto Exit0;
}
bRet = TRUE;
Exit0:
return bRet;
}
BOOL CNodeInTree::CalcFollowPos(CNodeInTree *pNode)
{
BOOL bRet = FALSE;
switch (pNode->m_pToken->GetType())
{
case eType_STAR:
for (vector<CNodeInTree*>::iterator it = pNode->m_vecLastPos.begin();
it != pNode->m_vecLastPos.end();
it++)
{
AppendVector((*it)->m_vecFollowPos, pNode->m_vecFirstPos);
}
break;
case eType_CONCAT:
for (vector<CNodeInTree*>::iterator it = pNode->m_Node1->m_vecLastPos.begin();
it != pNode->m_Node1->m_vecLastPos.end();
it++)
{
AppendVector((*it)->m_vecFollowPos, pNode->m_Node2->m_vecFirstPos);
}
break;
default:
goto Exit0;
}
bRet = TRUE;
Exit0:
return bRet;
}














 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









