







1、Spark Streaming本质
Input Output
Computation
例子:
def
main(args: Array[
String]):
Unit = {
val conf = new SparkConf().setAppName( "SccOps").setMaster( "local[2]")
val ssc = new StreamingContext(conf , Seconds( 1))
val lines = ssc.socketTextStream( "localhost" , 9999)
val words = lines.flatMap(_.split( " "))
val pairs = words.map(word => (word , 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
val conf = new SparkConf().setAppName( "SccOps").setMaster( "local[2]")
val ssc = new StreamingContext(conf , Seconds( 1))
val lines = ssc.socketTextStream( "localhost" , 9999)
val words = lines.flatMap(_.split( " "))
val pairs = words.map(word => (word , 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
显示输出的结果

下面对sparkStreaming的官方文档进行了阅读:
http://spark.apache.org/docs/latest/streaming-programming-guide.html

Spark Streaming的流处理是基于时间间隔的批处理(一个连续的过程)
把特定时间的数据封装成RDD,跟从文件中读取是一个意思

如上图所示,Spark Streaming接收到输入数据流并且将其进行分批处理,然后被Spark Engine处理,最后生成最后的处理结果
Spark Streaming提供了一个高层次的抽象叫做
discretized stream
(
DStream),代表了一个连续的数据流,DStream的两个创建方式:1、从Kafka、Flume、Kinesis等过来的输入流;2、其他的DStream的操作产生
NetworkWordCount的例子:
首先,运行Netcat
nc -lp 9999
新建一个terminal,运行例子
./bin/run-example streaming.NetworkWordCount localhost 9999 //spark安装目录下
然后在nc server端输入一些单词,就会出来统计的结果

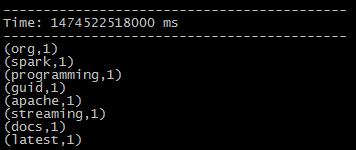
初始化StreamingContext
import
org.apache.spark._
import
org.apache.spark.streaming._
val
conf
=
new
SparkConf
().
setAppName
(
appName
).
setMaster
(
master
)
val
ssc
=
new
StreamingContext
(
conf
,
Seconds
(
1
)) //注意,内部实际上创建了一个SparkContext,可以通过ssc.sparkContext访问
/**
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf , batchDuration: Duration) = {
this(StreamingContext. createNewSparkContext(conf) , null , batchDuration)
}
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf , batchDuration: Duration) = {
this(StreamingContext. createNewSparkContext(conf) , null , batchDuration)
}
private[streaming]
def
createNewSparkContext(conf: SparkConf): SparkContext = {
new SparkContext(conf)
}
new SparkContext(conf)
}
这里的批处理时间间隔必须根据应用程序的延迟要求进行设置
StreamingContext也可以从一个存在的SparkContext创建
import org.apache.spark.streaming._
val
sc
=
...
// existing SparkContext
val
ssc
=
new
StreamingContext
(
sc
,
Seconds
(
1
))
创建完成StreamingContext之后,你可以做如下操作:
(1)、通过创建input DStreams来定义输入源
(2)、具体逻辑的编写,包括transformation和output操作
(3)、使用streamingContext.start(),开始接受数据并且进行数据处理
(4)、使用streamingContext.awaitTermination(),等待程序被停止(手动或者遇到错误)
(5)、可以使用streamingContext.stop()终止程序
注意:
一但一个context started,不能添加或者建立新的流计算
一但一个context stopped,就不能重新启动
同一个时间在一个JVM中只能有一个StreamingContext是active状态
stop()操作会同时stop SparkContext,
To stop only the StreamingContext, set the optional parameter of
stop()
called
stopSparkContext
to false
A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created
Discretized Streams (DStreams)
Spark Streaming提供的基本抽象,内部由一系列连续的RDD表示,每个RDD包含了一个时间间隔的数据,如下图所示:
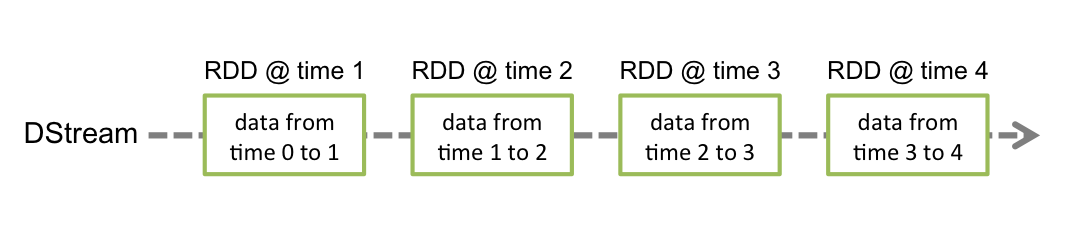
任何应用于DSream上的操作会转换成在底层的RDD上的操作,例如下图所示,flatMap作用于每个lines DStream下的RDD上,然后生成words DStream下的RDD
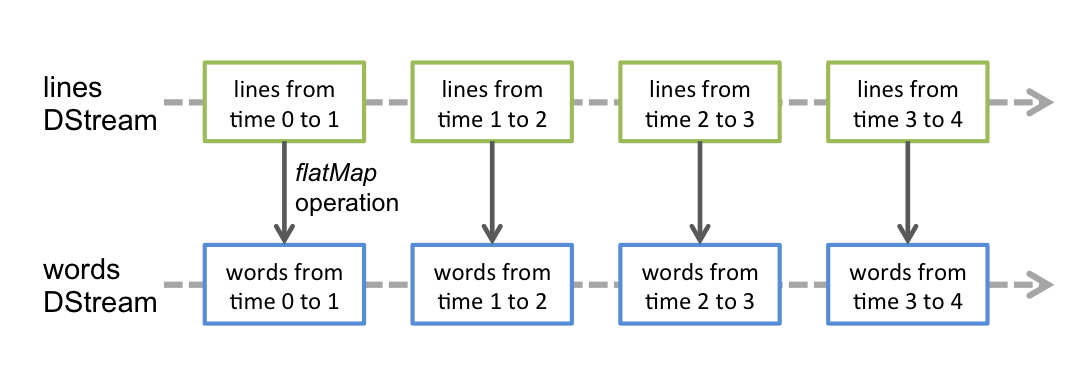
底层的RDD transformations操作被Spark engine操作,DStream操作隐藏了这些细节,提供了开发者更高级别的API,使开发更加便捷。
Input DStreams and Receivers
每一个input DStream(除了file stream)会和Receiver相关联,Receiver接收数据并把它存储在Spark的内存中以供计算。
Spark Streaming提供了两种内建的数据流来源
- Basic sources: Sources directly available in the StreamingContext API. Examples: file systems, and socket connections.
- Advanced sources: Sources like Kafka, Flume, Kinesis, etc. are available through extra utility classes. These require linking against extra dependencies as discussed in the linking section
在一个streaming application中,可以创建多个input DStreams,来并行的接收多个流数据。这样会创建多个receivers同时接收数据流。需要注意的是一个Worker/executor是一个长期运行的task,于是它占有一个core,因此要记得分配足够的cores(如果是local模式,就是线程)
注意:
local模式下,不要使用"local"或者"local[1]"作为master URL,否则会只有一个线程被用来running task locally。如果使用了一个基于receiver(e.g. sockets,kafka,flume,etc.)的input DStream,那么这个单线程会用来运行receiver,就没有线程用来运行处理received data的程序,所以一般使用"local[n]" as the master URL,n大于需要运行的receivers的数量
同样的,运行在集群上时cores的数量必须大于receivers的数量,否则系统只会接受数据,不会处理数据
数据的基本来源
1、File Streams:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
Spark Streaming will monitor the directory
dataDirectory
and process any files created in that directory (files written in nested directories not supported). Note that
- The files must have the same data format.
- The files must be created in the
dataDirectoryby atomically moving or renaming them into the data directory. - Once moved, the files must not be changed. So if the files are being continuously appended, the new data will not be read.
For simple text files, there is an easier method
streamingContext.textFileStream(dataDirectory)
. And file streams do not require running a receiver, hence does not require allocating cores.
2、Streams based on Custom Receivers:
DStreams can be created with data streams received through custom receivers. See the
Custom Receiver Guide
and
DStream Akka
for more details.
3、Queue of RDDs as a Stream:
For testing a Spark Streaming application with test data, one can also create a DStream based on a queue of RDDs, using
streamingContext.queueStream(queueOfRDDs)
. Each RDD pushed into the queue will be treated as a batch of data in the DStream, and processed like a stream.
Advanced Sources
包括Kafka、Flume、Kinesis,
不能再Spark shell中测试,除非下载相关的依赖包,并且加到classpath中
Custom Sources
自定义来源,
Input DStreams can also be created out of custom data sources. All you have to do is implement a user-defined
receiver
(see next section to understand what that is) that can receive data from the custom sources and push it into Spark. See the
Custom Receiver Guide
for details.
类似RDD的操作,DStreams的操作分为
Transformations on DStreams和Output Operations on DStreams
Design Patterns for using foreachRDD
dstream.foreachRDD
is a powerful primitive that allows data to be sent out to external systems. However, it is important to understand how to use this primitive correctly and efficiently. Some of the common mistakes to avoid are as follows.
演变过程:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
这样的话connection object需要被序列化,并且从driver传到worker,错误会表现出序列化错误、初始化错误等等。正确的方法是在worker端创建connection object
但是这样又会导致另一个错误:为每个record 创建一个connection
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
但是这样每创建一个connection object都会占用时间和资源,因此会增加不必要的资源消耗,并且降低系统的整体吞吐量,一个更好的方法是使用rdd.foreachPartition,创建一个connection object,然后使用这个connection发送所有的records到一个RDD partition。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
最后通过重用connection objects来优化
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}}
Other points to remember:
-
DStreams are executed lazily by the output operations, just like RDDs are lazily executed by RDD actions. Specifically, RDD actions inside the DStream output operations force the processing of the received data. Hence, if your application does not have any output operation, or has output operations like
dstream.foreachRDD()without any RDD action inside them, then nothing will get executed. The system will simply receive the data and discard it. -
By default, output operations are executed one-at-a-time. And they are executed in the order they are defined in the application.
Accumulators and Broadcast Variables不会从checkpoint中恢复,因此需要创建lazily instantiated singleton instances for them
DataFrame and SQL Operations
/** DataFrame operations inside your streaming program */
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SparkSession
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()}
2、Structured Streaming本质
Input Table 和 Output Table
Structured Streaming预计在Spark 2.3的时候成熟
Output Table
# TERMINAL 2: RUNNING StructuredNetworkWordCount
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+
...
流处理数据服务中心
数据可以带有原始的时间戳
Structured Streaming根据数据创建时的时间戳
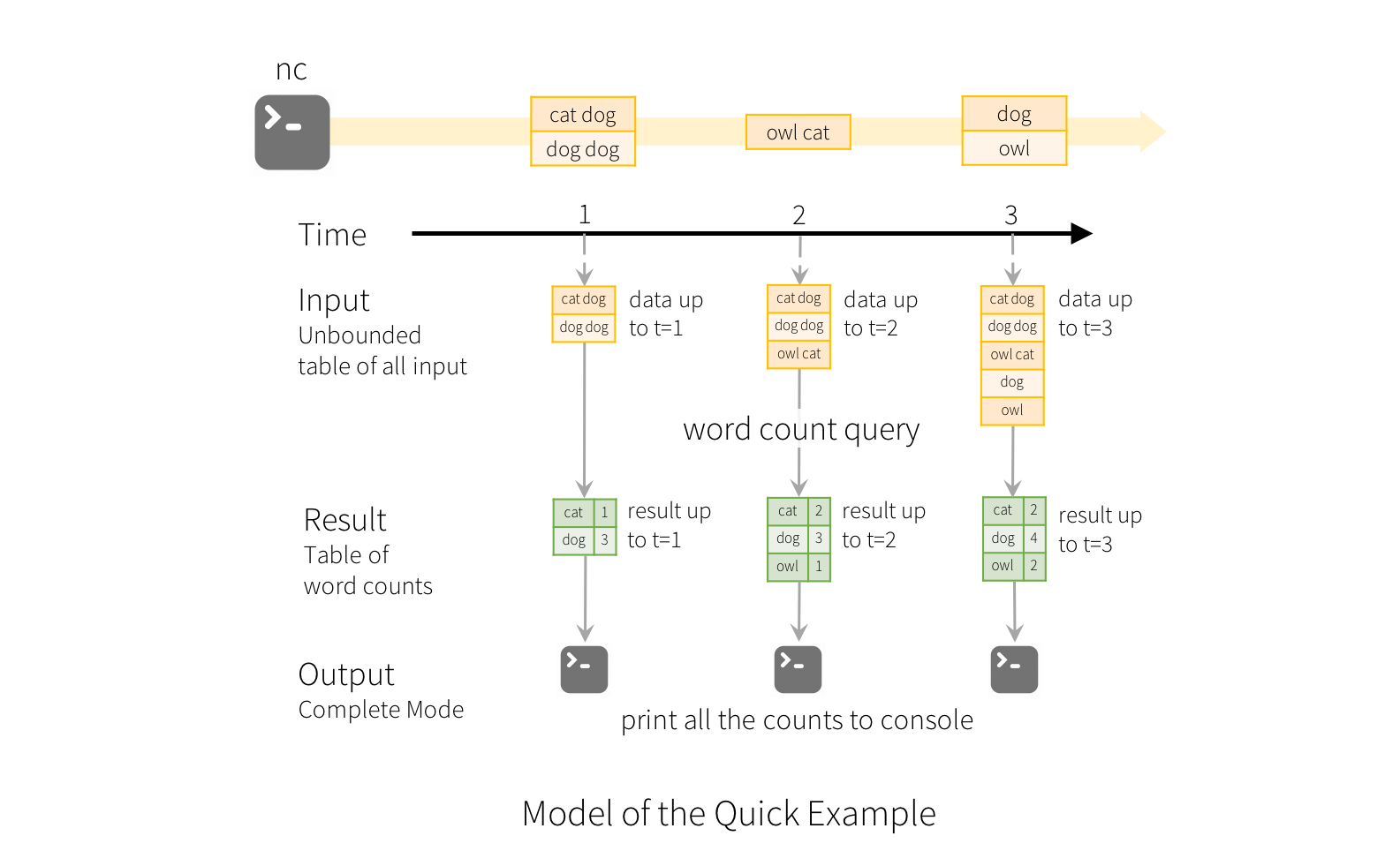
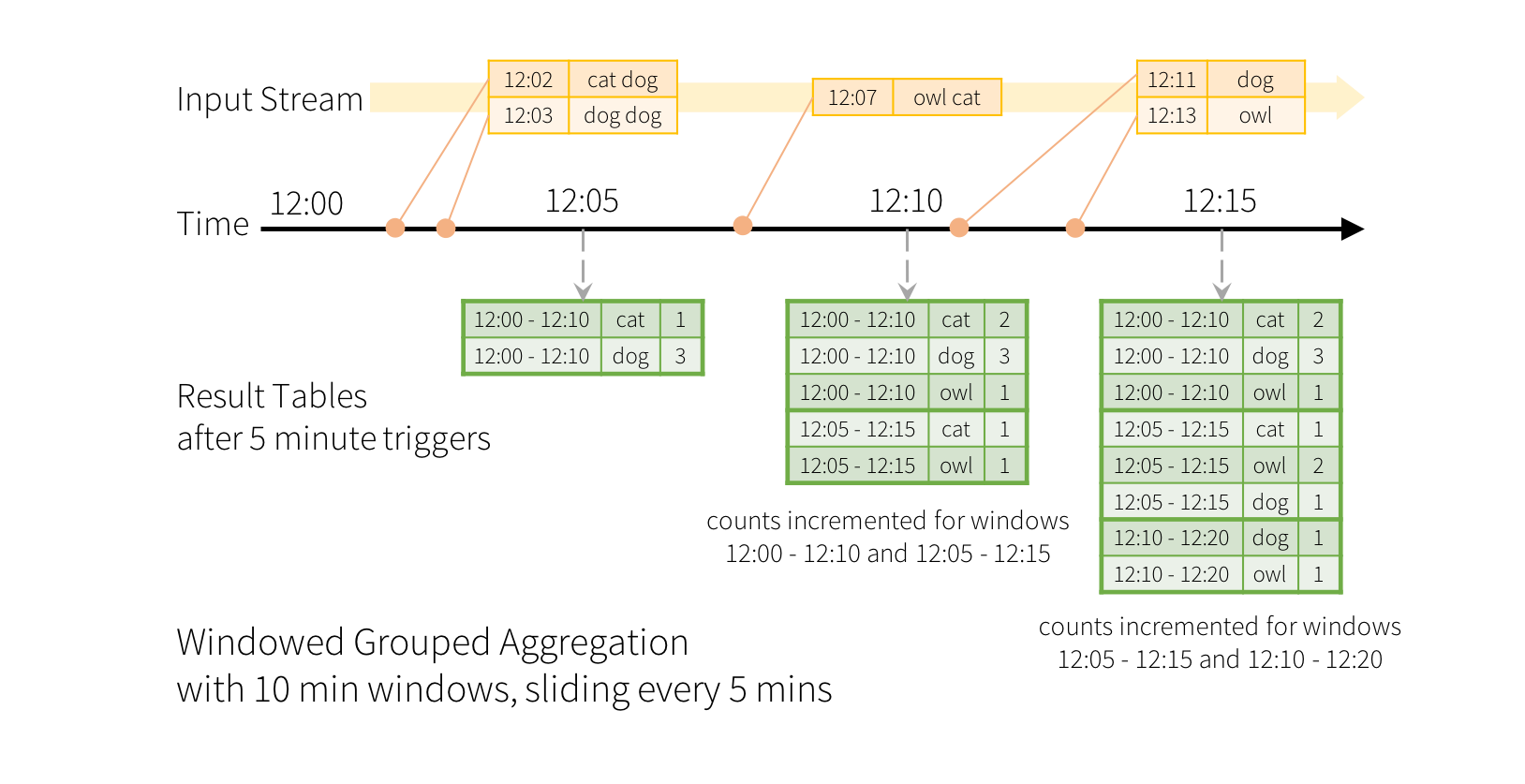
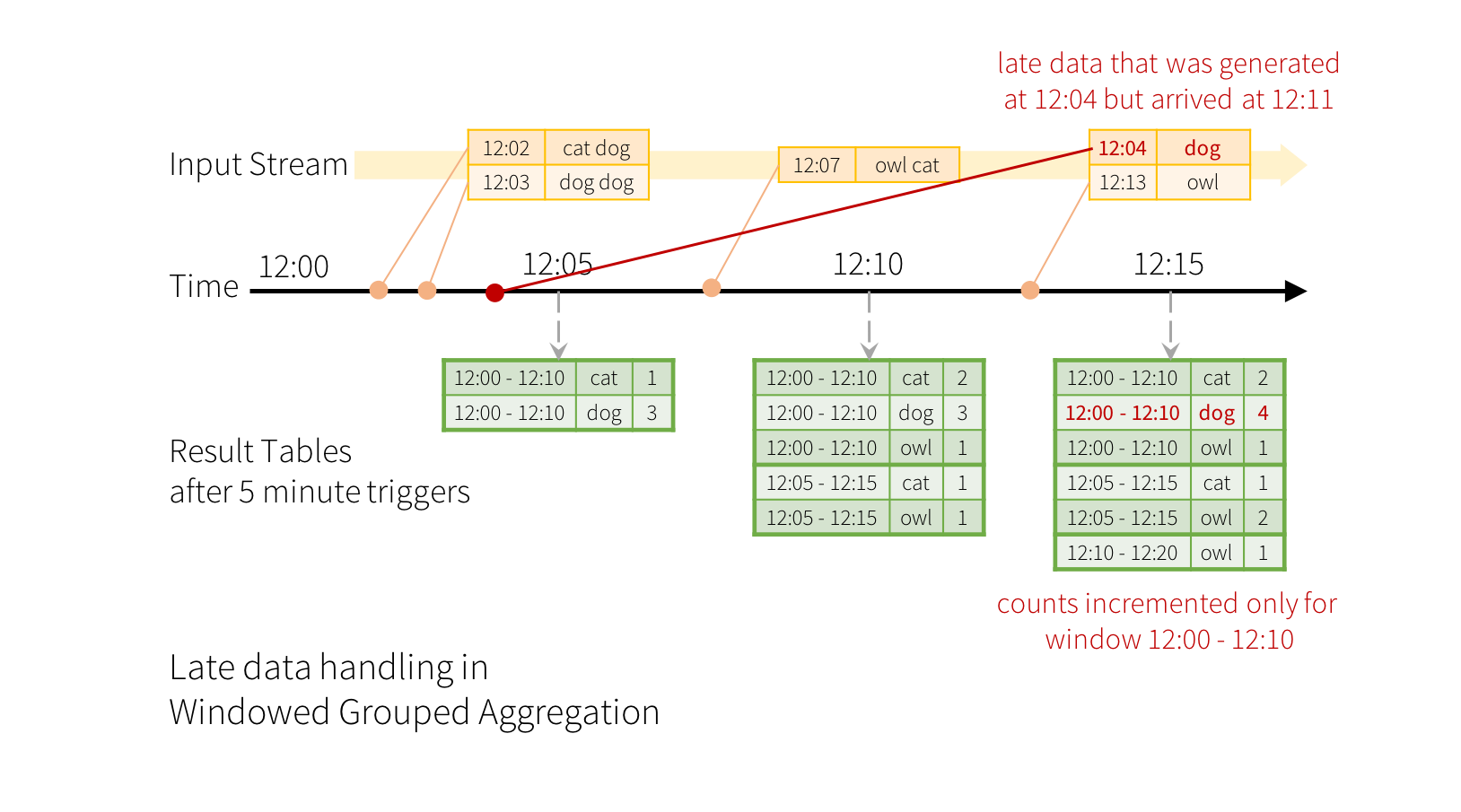
基于表的增量计算!

从总体上而言,推出了一个新概念 Continuous Application或者说端到端的Application
加微信
18611576994 或者官方报名咨询QQ群 163728659可以获得更多DT大数据梦工厂大数据Spark蘑菇云行动准备课程的视频、源代码和文档资料等,老师的微博:http://weibo.com/ilovepains/,获得大量的大数据最新和最干货的信息并与老师互动。















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









