







 本文详细介绍Java8中的StreamAPI,包括Stream的基本概念、操作步骤、创建方法、中间操作、终止操作等,并提供丰富的示例代码说明如何使用Stream进行数据处理。
本文详细介绍Java8中的StreamAPI,包括Stream的基本概念、操作步骤、创建方法、中间操作、终止操作等,并提供丰富的示例代码说明如何使用Stream进行数据处理。
版权声明:本文为 小异常 原创文章,非商用自由转载-保持署名-注明出处,谢谢!
本文网址:https://blog.csdn.net/sun8112133/article/details/88826272
文章目录
四、Stream API
1、Stream概述
Stream API是 Java8中重大的改变,称为“流”。它专门用来处理集合,对集合中的数据进行查找、过滤和映射等操作。
注意:
1)Stream 自己不会存储元素;
2)Stream 不会改变源对象,他们会返回一个持有结果的新Stream;
3)Stream 操作是延迟执行的。这意味着他们会等到结果的时候才执行。
2、Stream的操作步骤
1)创建Stream
通过一个数据源(如:集合、数组),获取一个流
2)中间操作
一个中间操作链,对数据源的数据进行处理
3)终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果

3、创建Stream
1)可以通过 Collection系列集合提供的 stream() 或 parallelStream()(并行流)
List<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
2)通过 Arrays中的静态方法 stream()获取数组
Employee[] emps = new Employee[10];
Stream<Employee> stream2 = Arrays.stream(emps);
3)通过 Stream类中的静态方法 of()
Stream<String> stream3 = Stream.of("aa", "bb", "cc");
4)创建无限流
// 迭代 iterate()
Stream<Integer> stream4 = Stream.iterate(0, (x) -> x+2);
stream4.limit(10).forEach(System.out::println);
// 生成 generate()
Stream.generate(() -> Math.random()).limit(5).forEach(System.out::println);
4、Stream中间操作
1)筛选与切片
filter(Predicate p)
过滤元素,从流中留下某些元素。
limit(long n)
截断元素,选取前n个元素
skip(long n)
跳过元素,扔掉了前n个元素的流,留下剩下的元素。若流中元素不足n个,则返回一个空流。
distinct()
筛选元素,去除重复元素(通过元素的hashCode()和equals()去除重复)
2)映射
map(Function<T, R> mapper)
将元素转换成其他形式或提取信息。
flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
将流中的每个值都换成另一个流,然后把所有流连接成一个流。
map与flatMap的区别:
map: { {a,a,a}, {b,b,b}, … }
flatMap: {a,a,a,b,b,b,…}
3)排序
sorted()
自然排序(Cmparable)
sorted(Comparator com)
比较器排序(Comparator)
5、Stream终止操作
1)查找与匹配
allMatch(Predicate p)
检查是否匹配所有元素
anyMatch(Predicate p)
检查是否至少匹配一个元素
noneMatch(Predicate p)
检查是否没有匹配所有元素
findFirst()
返回流中第一个元素
findAny()
返回当前流中的任意元素
count()
返回流中元素的总个数
max(Comparator c)
返回流中最大值
min(Comparator c)
返回流中最小值
forEach(Consumer c)
内部迭代,用于遍历,替代了增强for循环
2)归约
reduce(T identity, BinaryOperator bo)
可以将流中元素反复结合起来,得到一个值。返回T
reduce(BinaryOperator bo)
可以将流中元素反复结合起来,得到一个值。返回Optional<T>
3)收集
collect(Collector c)
将流转换为其他形式。对流中的数据进行收集汇总,接收一个 Collector接口的实现Collectors类是专门用来创建收集器的工具类,它里面提供了很多静态方法,可以方便地创建常见收集器实例:
List Collectors.toList()
List收集器
Set Collectors.toSet()
Set收集器
ArrayList Collectors.toCollection(ArrayList::new)
集合收集器,可指定任意集合
Long Collectors.counting()
计数收集器
Integer Collectors.summingInt(i -> i)
求和收集器
Double Collectors.averagingDouble(i -> i)
平均值收集器
IntSummaryStatistics Collectors.summarizingInt(i -> i)
收集流中Integer属性的统计值。
例如:
iss.getAverage(); // 平均值
iss.getCount(); // 总数
iss.getMax(); // 最大值
iss.getMin(); // 最小值
iss.getSum(); // 求和
String Collectors.joining()
连接流中每个元素
Optional Collectors.maxBy(Double::compareTo)
最大值
Optional Collectors.minBy(Double::compareTo)
最小值
Map<K, List<V>> Collectors.groupingBy(Function func[, Collector coll])
分组
Map<Boolean, List<T>> Collectors.partitioningBy(Predicate predicate)
分区
6、应用
备用数据:
List<Employee> emps = Arrays.asList(
new Employee("张三", 14, 3242.2, Status.ERROR),
new Employee("李四", 32, 5342.23, Status.OK),
new Employee("王五", 21, 64523.23, Status.OK),
new Employee("王五", 21, 64523.23, Status.OK),
new Employee("王五", 21, 64523.23, Status.OK),
new Employee("赵六", 83, 541.2, Status.ERROR)
);
1)内部迭代与外部迭代
// 内部迭代:迭代操作由 Stream API 完成
@Test
public void test1() {
// 中间操作:不会执行任何操作
Stream<Employee> stream1 = emps.stream().filter((x) -> {
System.out.println("Stream API 中间操作");
return x.getAge() > 30;
});
// 终止操作:一次性执行全部内容,即“惰性求值”
stream1.forEach(System.out::println);
}
// 外部迭代
@Test
public void test2() {
Iterator<Employee> it = emps.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
2)Stream中间操作之【筛选与切片】
/*
* filter(Predicate p):过滤元素,从流中留下某些元素。
* limit(long n):截断元素,选取前n个元素。
* skip(long n):跳过元素,扔掉了前n个元素的流,留下剩下的元素。
* distinct():筛选元素,去除重复元素
*/
@Test
public void test() {
emps.stream()
//.filter((e) -> e.getAge() > 20)
.filter((e) -> {
System.out.println("短路");
// 当找到满足条件的2条数据,后面的数据就不再执行了,
// 相当于短路了,提高了效率
return e.getAge() > 20;
})
.limit(2) // 取前两个
.forEach(System.out::println); // [李四…] [王五…]
emps.stream()
.filter((e) -> e.getAge() > 20)
.skip(2) // 除了前两个
.forEach(System.out::println); // [王五…] [王五…] [赵六…]
emps.stream()
.distinct() // 去除重复
.forEach(System.out::println); // [张三…][李四…][王五…][赵六…]
}
3)Stream中间操作之【映射】
/*
* map(Function<T, R> mapper):将元素转换成其他形式或提取信息。
* flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
* 将流中的每个值都换成另一个流,然后把所有流连接成一个流。
*/
@Test
public void test() {
List<String> list = Arrays.asList("aaaa", "bbb", "cccc", "ddd");
list.stream()
//.map((x) -> x.length() > 3)
.map((str) -> str.toUpperCase())
.forEach(System.out::println);
System.out.println("--------------------"); // [AAAA,BBB,CCCC,DDD]
emps.stream()
//.map((e) -> e.getName())
.map(Employee::getName)
.forEach(System.out::println);
System.out.println("---------------------"); // 张三 李四 王五 王五 王五 赵六
// map: { {a,a,a}, {b,b,b}, ... }
// flatMap: {a,a,a,b,b,b,...}
// 原理类似:add(Object obj) 与 addAll(Collection coll)
// add: [11, 22, [aa, bb, cc]]
// addAll: [11, 22, aa, bb, cc]
Stream<Stream<Character>> map = list.stream()
.map(TestLambda7::filterChar);
map.forEach((sm) -> sm.forEach(System.out::println));
System.out.println("---------------------");
Stream<Character> map2 = list.stream()
.flatMap(TestLambda7::filterChar);
map2.forEach(System.out::println);
}
public static Stream<Character> filterChar(String str) {
List<Character> list = new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch);
}
return list.stream(); // [a,a,a]
}
4)Stream中间操作之【排序】
/*
* sorted():自然排序(Cmparable)
* sorted(Comparator com):比较器排序(Comparator)
*/
@Test
public void test() {
List<String> list = Arrays.asList("ddd", "bbb", "aa", "eee", "ccc");
list.stream().sorted().forEach(System.out::println); // [aa, bbb, ccc, ddd, eee]
emps.stream()
.sorted((e1, e2) -> {
int num = e1.getAge() - e2.getAge();
return num == 0 ? e1.getName().compareTo(e2.getName()) : num;
}) // 先按年龄排,年龄相同,再按姓名排
.forEach(System.out::println);
}
5)Stream终止操作之【查找与匹配】
/*
* allMatch(Predicate p):检查是否匹配所有元素
* anyMatch(Predicate p):检查是否至少匹配一个元素
* noneMatch(Predicate p):检查是否没有匹配所有元素
* findFirst():返回流中第一个元素
* findAny():返回当前流中的任意元素
* count():返回流中元素的总个数
* max(Comparator c):返回流中最大值
* min(Comparator c):返回流中最小值
*/
@Test
public void test() {
boolean bool1 = emps.stream().allMatch((e) -> e.equals(Status.OK));
System.out.println(bool1); // false
boolean bool2 = emps.stream().anyMatch((e) -> e.equals(Status.ERROR));
System.out.println(bool2); // false
boolean bool3 = emps.stream().noneMatch((e) -> e.equals(Status.ERROR));
System.out.println(bool3); // true
Optional<Employee> op = emps.stream().findFirst();
System.out.println(op.get()); // 张三…
Optional<Employee> op2 = emps.stream().findAny();
System.out.println(op2.get()); // 张三…
long count = emps.stream().count();
System.out.println(count); // 6
Optional<Employee> op3 = emps.stream()
.max((e1, e2) -> {
int num = e1.getAge() - e2.getAge();
return num == 0 ? e1.getName().compareTo(e2.getName()) : num;
});
System.out.println(op3.get()); // 赵六
Optional<Employee> op4 = emps.stream()
.min((e1, e2) -> {
int num = e1.getAge() - e2.getAge();
return num == 0 ? e1.getName().compareTo(e2.getName()) : num;
});
System.out.println(op4.get()); // 张三
}
6)Stream终止操作之【归约】
/*
* reduce(T identity, BinaryOperator bo):可以将流中元素反复结合起来,得到一个值。返回T
* reduce(BinaryOperator bo):可以将流中元素反复结合起来,得到一个值。返回Optional<T>
*/
@Test
public void test() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream()
.reduce(0, (t1, t2) -> t1+t2); // 初值为0,所以相加后的结果不会是空指针异常
/*
* 第一次:t1=0,t2=1, 0+1=1
* 第二次:t1=1,t2=2, 1+2=3
* 第三次:t1=3,t2=3, 3+3=6
* ...
*/
System.out.println(sum); // 55
double s = Double.sum(10.203, 24.12);
System.out.println(s); // 34.323
Optional<Integer> op = list.stream().reduce(Integer::sum);
System.out.println(op.get()); // 没有给定初值,所以可能会出现空指针异常,所以返回Optional对象 // 55
Optional<Double> op2 = emps.stream().map(Employee::getSalary).reduce(Double::sum);
System.out.println(op2.get()); // 202695.32000000004
}
7)Stream终止操作之【收集】
/*
* collect(Collector c):将流转换为其他形式。
对流中的数据进行收集汇总,接收一个 Collector接口的实现
* Collectors类是专门用来创建收集器的工具类,
它里面提供了很多静态方法,可以方便地创建常见收集器实例
*
* List<T> Collectors.toList():List收集器
* Set<T> Collectors.toSet():Set收集器
* ArrayList Collectors.toCollection(ArrayList::new):集合收集器(可以指定任意集合)
*/
@Test
public void test1() {
List<String> list = emps.stream()
.map(Employee::getName)
.distinct()
.collect(Collectors.toList()); // 将流中的数据转换为List集合
System.out.println(list); // List:[张三, 李四, 王五, 赵六]
System.out.println("------------------");
String[] arr = {"aaa", "bb", "dddd", "cc", "eeeeeeee"};
List<String> list2 = Arrays.stream(arr)
.filter((str) -> str.length() > 3)
.collect(Collectors.toList());
list2.forEach(System.out::println); // List:dddd eeeeeeee
System.out.println("---------------------");
Set<String> set = emps.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
set.forEach(System.out::println); // Set:[李四 张三 王五 赵六]
System.out.println("---------------------");
ArrayList<String> list3 = emps.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(ArrayList::new));
list3.forEach(System.out::println); // ArrayList: [张三 李四 王五 王五 王五 赵六]
}
/*
* Long Collectors.counting():计数收集器
* Integer Collectors.summingInt(i -> i):求和收集器
* Double Collectors.averagingDouble(i -> i):平均值收集器
* Optional Collectors.maxBy(Double::compareTo):最大值
* Optional Collectors.minBy(Double::compareTo):最小值
*/
@Test
public void test2() {
// 收集流中元素的总数
String[] arr = {"aaa", "bb", "dddd", "cc", "eeeeeeee"};
Long count = Arrays.stream(arr).collect(Collectors.counting());
System.out.println(count); // 5
System.out.println("-----------------------------");
// 平均值
Double[] arr2 = {1.0,2.0,3.0,4.0,5.0,6.0};
Double avg = Arrays.stream(arr2).collect(Collectors.averagingDouble((i) -> i));
// 注意:数组的类型是引用数据类型,而且在这里不会进行自动封装,元素也必须是对应的数据类型。
System.out.println(avg); // 3.5
System.out.println("-----------------------------");
emps.stream()
.collect(Collectors.averagingDouble((e) -> e.getSalary()));
// 求和
Double sum = Arrays.stream(arr2).collect(Collectors.summingDouble(i -> i));
System.out.println(sum); // 21.0
System.out.println("-----------------------------");
// 最大值
Optional<Double> op = Arrays.stream(arr2).collect(Collectors.maxBy(Double::compareTo));
System.out.println(op.get()); // 6.0
// 最小值
Optional<Double> op2 = Arrays.stream(arr2).collect(Collectors.minBy(Double::compareTo));
System.out.println(op2.get()); // 1.0
}
/*
* IntSummaryStatistics Collectors.summarizingInt(i -> i):收集流中Integer属性的统计值。
* 如:iss.getAverage(); // 平均值
* iss.getCount(); // 总数
* iss.getMax(); // 最大值
* iss.getMin(); // 最小值
* iss.getSum(); // 求和
*/
@Test
public void test3() {
Integer[] arr = {1,2,3,4,5};
IntSummaryStatistics iss = Arrays.stream(arr).collect(Collectors.summarizingInt(i -> i));
System.out.println(iss);
// IntSummaryStatistics{count=5, sum=15, min=1, average=3.000000, max=5}
System.out.println(iss.getAverage()); // 平均值
System.out.println(iss.getCount()); // 总数
System.out.println(iss.getMax()); // 最大值
System.out.println(iss.getMin()); // 最小值
System.out.println(iss.getSum()); // 求和
}
/*
* 合并成字符串
* String Collectors.joining():连接流中每个元素
*/
@Test
public void test4() {
String str1 = emps.stream().map(Employee::getName).collect(Collectors.joining());
System.out.println(str1); // 张三李四王五王五王五赵六
String str2 = emps.stream().map(Employee::getName).collect(Collectors.joining(","));
System.out.println(str2); // 张三,李四,王五,王五,王五,赵六
String str3 = emps.stream().map(Employee::getName)
.collect(Collectors.joining(",", "====前====", "----后----"));
System.out.println(str3); // ====前====张三,李四,王五,王五,王五,赵六----后----
}
/*
* 分组
* Map<K, List<V>> Collectors.groupingBy(Function func[, Collector coll]):分组
*/
@Test
public void test5() {
// 按状态分组
Map<Status, List<Employee>> map = emps.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(map);
// {ERROR=[Employee [name=张三...], ...], OK=[Employee [name=李四...], ...]}
}
// 多级分组
@Test
public void test6() {
Map<Status, Map<String, List<Employee>>> map =
emps.stream().collect(Collectors.groupingBy(
Employee::getStatus, Collectors.groupingBy((e) -> {
if (((Employee) e).getAge() < 20) {
return "少年英雄";
} else if (((Employee) e).getAge() < 40) {
return "中年";
} else {
return "老当益壮";
}
})));
// {ERROR={老当益壮=[Employee...], 少年英雄=[Employee...]}, OK={中年=[Employee...]}
}
/*
* 分区
* Map<Boolean, List<T>> Collectors.partitioningBy(Predicate predicate):分区
*/
@Test
public void test7() {
Map<Boolean, List<Employee>> map = emps.stream()
.collect(Collectors.partitioningBy((e) -> e.getStatus().equals(Status.OK)));
System.out.println(map);
// {false=[Employee...], true=[Employee...]}
}
五、并行流与串行流
1、并行流概述
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过 parallel() 与sequential() 在并行流与顺序流之间进行切换。
2、Fork/Join 框架
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
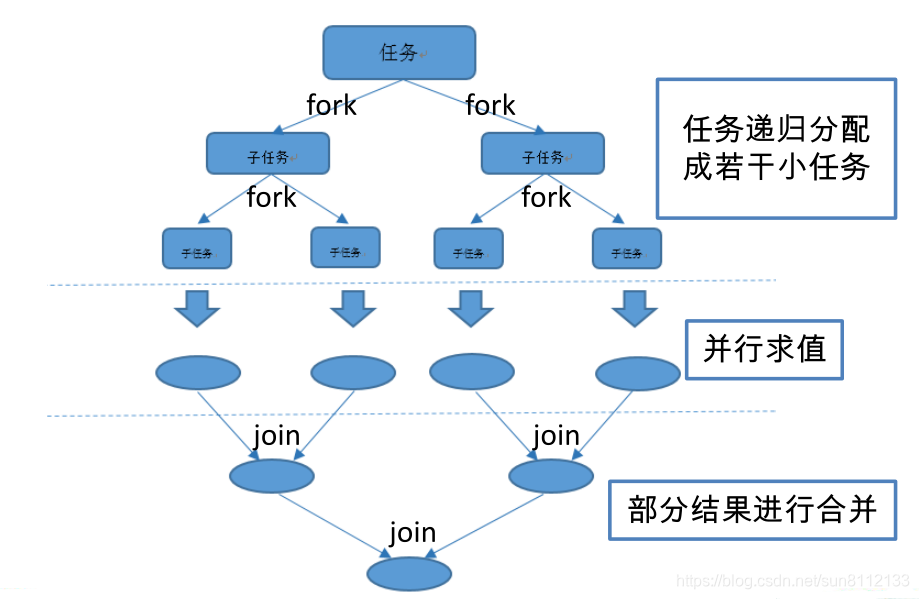
3、Fork/Join 框架与传统线程池的区别
采用 “工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上。在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态。而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行,那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行。这种方式减少了线程的等待时间,提高了性能。
4、应用
public class TestForkJoin {
// 普通for
@Test
public void test2() {
Instant start = Instant.now();
long sum = 0l;
for (long i = 0; i <= 10000000000L; i ++) {
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗费时间:" + Duration.between(start, end).toMillis()); // 6149
}
// ForkJoin框架
@Test
public void test() {
Instant start = Instant.now();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinCalculate(0, 10000000000L);
Long sum = pool.invoke(task);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗费时间:" + Duration.between(start, end).toMillis()); // 4667
}
// Java8并行流
@Test
public void test3() {
Instant start = Instant.now();
long sum = LongStream.range(0, 10000000000L)
.parallel()
.reduce(0, Long::sum);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗费时间:" + Duration.between(start, end).toMillis()); // 4232
}
}
六、Optional 类
1、Optional类概述
Optional<T> 类(java.util.Optional) 是一个容器类,代表一个值存在或不存在,原来用 null 表示一个值不存在,现在 Optional 可以更好的表达这个概念。并且可以尽最大努力避免空指针异常。
2、常用方法
Optional.of(T t)
创建一个 Optional实例
Optional.empty()
创建一个空的Optional实例
Optional.ofNullable(T t)
若t不为null,创建Optional实例,否则创建空实例
isPresent()
判断是否包含值
orElse(T t)
如果调用对象包含值,返回该值,否则返回t
orElseGet(Supplier s)
如果调用对象包含值,返回该值,否则返回s获取的值
map(Function f)
如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty()
flatMap(Function mapper)
与map类似,要求返回值必须是Optional
3、注意事项
使用Optional容器来包装可能为空的对象,但需要注意创建Optional实例时如果没有对象,则要保证是一个空实例(Optional.empty)。
4、应用
// 女孩类
public class Girl {
private String name;
public Girl() { }
public Girl(String name) { ... }
get()...&set()...
toString() ...
}
// 男孩类
public class Boy {
// Girl这个对象可能为空,所以用Optional包装,但此时没有具体实例,则需要初始化一个空实例
private Optional<Girl> girl = Optional.empty();
public Boy() { }
public Boy(Optional<Girl> girl) { ... }
get()...&set()...
toString() ...
}
@Test // 测试类
public void test() {
Optional<Boy> op = Optional.ofNullable(new Boy());
String girlName = getGirlName(op);
System.out.println(girlName); // 会输出默认值
}
// 需求:获取一个男孩心中女孩的名字
// 现在的写法
public String getGirlName(Optional<Boy> boy) {
return boy.orElse(new Boy()) // 如果不包含,则使用默认的
.getGirl() // 此时boy肯定不会为空
.orElse(new Girl("苍老师"))
.getName();
}
// 以前的写法
public String getGirlName(Boy boy) {
// return boy.getGirl().getName(); // 这样容易报空指针异常
// boy与girl都可能为空,所以要用if语句进行判断
if (boy != null) {
Girl g = boy.getGirl();
if (g != null) {
return g.getName();
}
}
return "苍老师";
}


















 3221
3221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











