







引言
最近受AlphaGo的刺激,开始从google新开源的Tensorflow库学习DeepLearning。便匆匆忙忙的把环境搭建好,配合官网教程学习源代码,但是由于之前没在意机器学习这块的知识,感觉拉下了不少功课,在Image Recognition章的CNN小节遇到了不少挫折。所以,我就花了两天业余时间精读了一下Alex Krizhevsky的发表文章,感觉获益良多,所以在这做点笔记给大家分享一下。另外,Alex Krizhevsky还有一篇关于RBM的大论文《Learning Multiple Layers of Features from Tiny Images》,这篇论文我略读了一下,里面概率公式特别多,因为我学业背景的关系,概率统计学方面的基础不是特别扎实,所以这篇的阅读只能暂时搁置了,等基础巩固好了再给大家分享。
正文
现在我们来看看《ImageNet Classification with Deep Convolutional Neural Networks》这篇文章在讲什么。首先论文发表惯例性引言,接着介绍他的实验数据集,主要是用ImageNet的ILSVRC比赛的样本,后面会稍微详细的介绍这部分的处理,然后是两个比较精彩的篇章,分别是网络架构(The Architecture)和减少过拟合的处理方法(Reducing Overfitting),想必也是很多机器学习学者比较关注的两个地方,最后就是实验结果与实验分析,这部分我们也会稍微简单讨论一下。
实验数据集
引言一般都是讲一些背景概况之类的,而且我是带着学习CNN的目的来看这篇文章的,所以引言部分我就先忽略了。那为什么引言都跳过了,还得看数据集呢?我觉得对作者使用的数据集与实验环境进行一定的了解,对复现他的实验成果有积极作用。作者使用的数据库是ImageNet的一个叫做ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)的比赛库。
首先ImageNet是一个包含22,000个类别,总共15 million张标记好的高分辨率图像的大型数据集。图像是通过网络收集,并被工作人员使用Amazon’s Mechanical Turk crowd-sourcing工具标记,这个工具貌似挺牛的,但我没细究过,所以不讨论这个工具。然后ILSVRC比赛集是,从ImageNet里抽出的1000个类别,而且每个类别大概1000张,总共差不多1,000,000张图片构成的样本集。文章表示,其中大概1.2 million是训练集,50,000张是验证集,还有150,000张是测试集。这里文章貌似不是很严谨,所以我们后面暂且将三个数认为是实验的样本比例构成,对于训练集,如果1000个类别的话,每个类别大概1200个数据。
另外,ImageNet有个评价惯例是top-1和top-5,其中top-5可以理解为真实类别在网络预测类别排行榜的前五的情况。比方说,输入一张哈士奇的图像,网络预测出一个类别得分向量,向量中分数从大到小的排名是“拉布拉多、斑点、哈士奇、波斯猫、狮子、老虎…“,这里哈士奇排名第三,即符合top-5的情况。但如果输入的是一张老虎的照片,还是输出这个结果,那么便不符合top-5。
最后,我们看下这个实验集的一个重点,就是输入网络的图像分辨率和一些预处理。首先作者根据长宽中较短的边长到256的比例,对图像进行缩放操作,结果会出来一张长或宽是256的图片。然后剪取中间部分,得到一张256x256分辨率的样本。值得注意的是,作者在文中表示除了会让训练样本图像减去图像均值以外,不做任何其他的预处理操作,但后面又说是在raw RGB值的像素上做训练。而在convnet的convdata.py文件中确实,有self.batch_data - self.batch_mean类似的字眼,但当我细查batch_meta[‘mean’]的赋值也没找着,所以我这里也暂时认为他是做过减均值处理的。而实际上,tensorflow里的alexnet在数据模拟的时候用的是0均值的truncated normal distribution,cifar10中还做了不少random增强操作。关于增强操作在后面过拟合的处理中也会有相关介绍。
网络架构
ReLU的非线性
一般的的神经元模型输出会用
f
(
x
)
=
t
a
n
h
(
x
)
f(x)=tanh(x)
f(x)=tanh(x)或者
f
(
x
)
=
(
1
+
e
−
x
)
−
1
f(x)=(1+ e^{-x})^{-1}
f(x)=(1+e−x)−1作为输入
x
x
x的激活函数。然而,这些非线性饱和函数在梯度下降的训练时间上,往往会比
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x)=max(0,x)
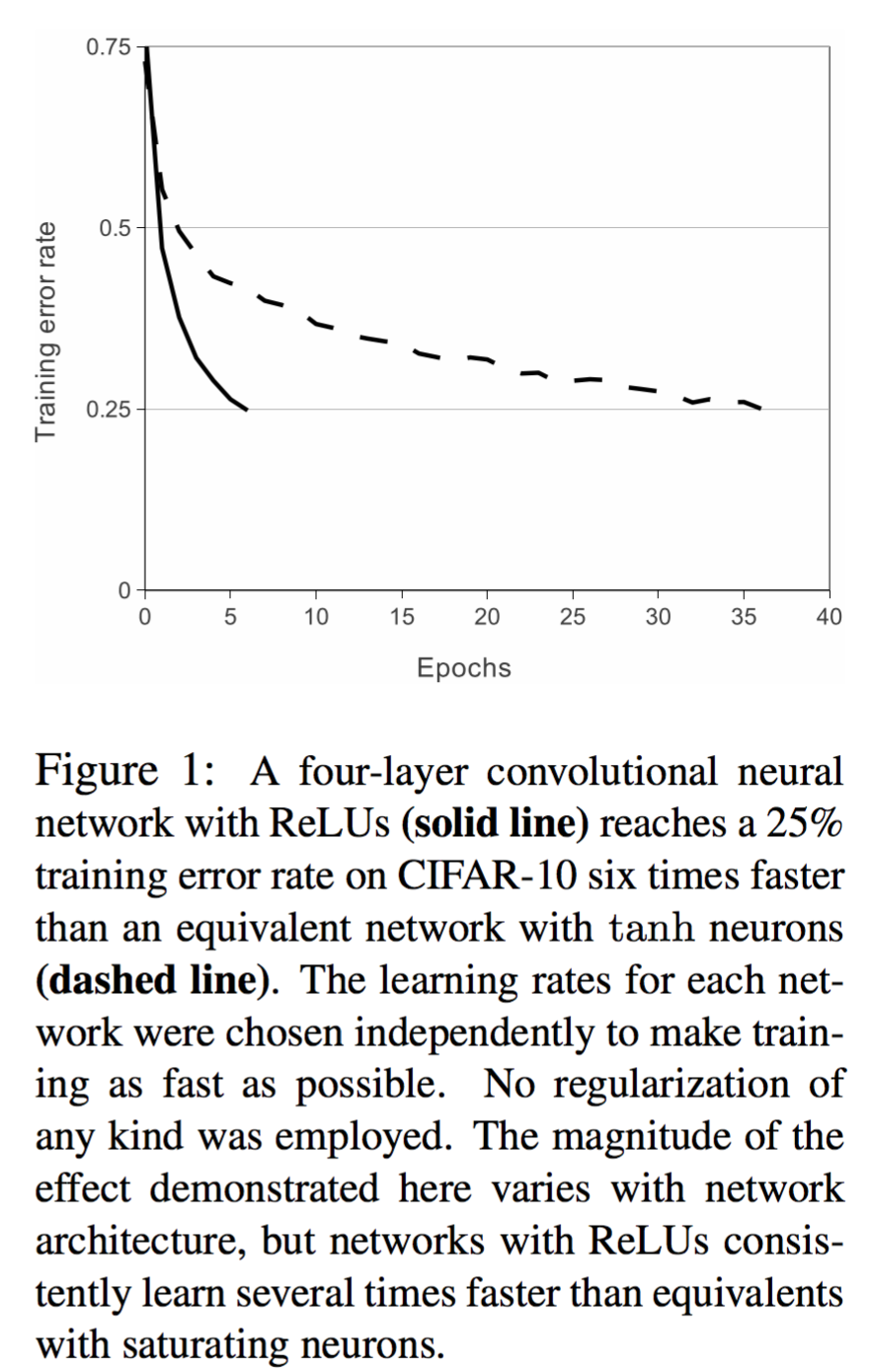
f(x)=max(0,x),即ReLU,这类非线性不饱和函数慢很多。我们看下面的实验数据结果,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代。
那是不就暗示着ReLU一定比其他非线性饱和函数在寻找全局最优点上绝对优势呢?其实不是这样的,Alex也表示他并不是第一个考虑调整CNN的传统神经元模型的人。此前,Jarrett等人的一份研究表明,用他们的对比度标准化方法结合
f
(
x
)
=
∣
t
a
n
h
x
)
∣
f(x)=\left\lvert tanhx) \right\lvert
f(x)=∣tanhx)∣的非线性,再做局部均值Pooling的效果在Caltech-101数据集上也有突出表现。不过,Alex对此还有一套说辞。他认为Caltech-101数据集的规模不够大,其实隐晦表达这个库不够科学,要在这个库获得好成绩更多的是需要担心过拟合的问题,跟咱们现在搞ImageNet的规模不是一个层次的,网络学习效率在大规模训练起着重要的影响作用,所以那套说不定已经过时了。所以,我认为如果在样本规模不是特别大的时候,引入非线性饱和函数来加强网络的泛化能力,未尝不是一种好方法。但是,在样本数量规模巨大的情况下,采用不饱和非线性函数(其实就是线性函数的局部选择性)才是主流,毕竟计算量就放在那了。
关于mutli-GPUs并行训练
这部分作者其实只是简单介绍了一下他的GPU并行架构实现。我们可以先看下AlexNet的网络架构图。
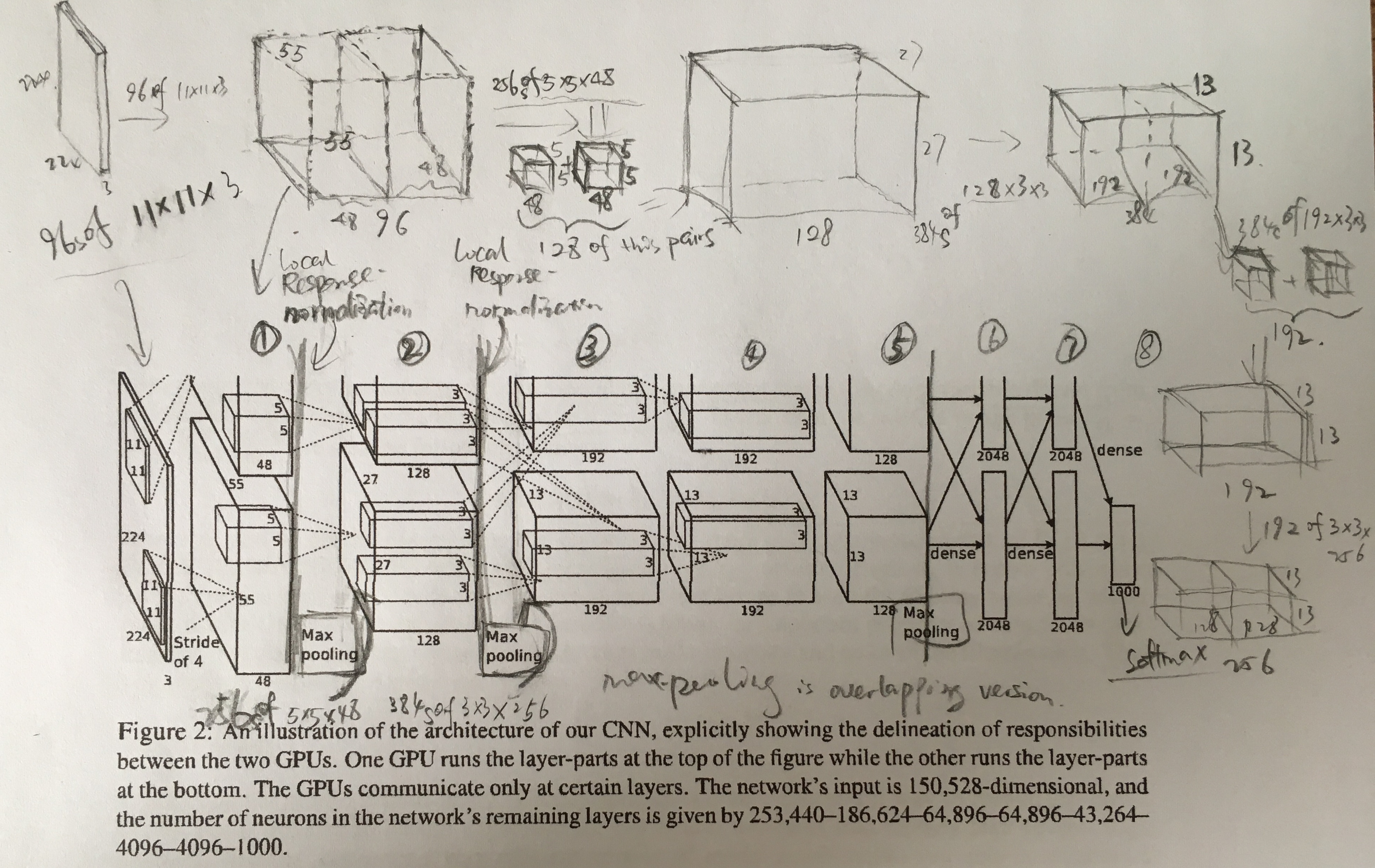
值得注意的是,我觉着这张图是Alex这篇文章的一个极大的亮点。其实,我刚开始不太舍得在这个小节摆出这图来,后面我会结合图中的笔记点出他的这个并行加速的重要思路。
作者之所以设计这个双GPU方案,是因为一个GTX 580 GPU只有3G内存,限制了网络规模的大小,ImageNet的1.2百万数据在这不好搞。再之,现在GPU都很适合做相互并行,因此他将网络拓展到两个GPU里面。如上图所示,他的并行方案是网络中的一半卷积核放到每个GPU上运行,这其实是利用了“GPU只与相应的某些卷积核交互”的一个trick。例如,图中第三层的卷积核会用第二层的所有卷积的映射结果作为输入,但第四层的卷积核只用到同一个GPU上的第三层卷积映射结果作为输入。尽管这种连接模式仍是交叉验证上的一个问题,但我们至少还能以这种分布式/并行计算方式,计算这个大规模数据。另外,作者的实验数据表示,two-GPU方案会比只用one-GPU跑半个上面大小网络的方案,在准确度上提高了1.7%的top-1和1.2%的top-5。值得注意的是,虽然one-GPU网络规模只有two-GPU的一半,但其实这两个网络其实并非等价的,one-GPU采用的实际上是上图铅笔笔记部分的图,后面会详细讨论它俩儿的等价性。
局部响应归一化
ReLU单元本身其实是不对输入做归一化,从而避免函数出现饱和现象。这里稍微明确我对函数饱和概念的理解,所谓函数饱和性,应该是指函数的有界性,比如,sigmoid函数的上下界分别是-1和1,因此也过说sigmoid函数会饱和到-1和1。那么如果训练样本经过卷积网络产生正响应输入到ReLu单元的话,该单元的相应参数就能够在这次进行学习。不过,Alex他们发现ReLu后面如果跟上一个局部相应归一化部分,会让网络达到更好的泛化效果。
a
x
,
y
i
a^i_{x,y}
ax,yi表示输入的(x,y)位置做第i次卷积并通过relu单元的结果,而
b
x
,
y
i
b^i_{x,y}
bx,yi是对应的归一化相应结果。 n是指相同位置的第i 次前后附近的n次卷积,而N是总的卷积次数。而且,这个卷积核作用的次序是在训练前就已经定好了。实际上,这个局部响应归一化是模拟生物神经元的侧抑制作用,当前神经元的作用受附近神经元作用的抑制,这样我们就理解为何上图公式,在归一化阶段仅仅除以相同位置附近前后几次的神经元响应的平方,而不是N次结果响应的平方。另外,图中公式的k=2,n=5,
α
=
1
0
−
4
,
β
=
0.75
\alpha=10^{-4}, \beta=0.75
α=10−4,β=0.75都是预设参数,不做详述。响应归一化的效果,对top-1和top-5分别提高了1.4%和1.2%,在CIFAR10中的结果也有提高,具体数据可以看下原文。

带交叠的Pooling
刚开始学习tensorflow的时候,我原以为Pooling层都是没有overlap的,即相邻的两个pooling单元的输入没有任何关系。因为CNNs的Pooling层是对相同卷积核的映射结果里面的邻近的几组输出做总结,从而提取特征。或者,也可以理解成以 s s s大小为步长对前面卷积层的结果进行分块,对块大小为 z × z z\times z z×z的卷积映射结果做总结,这时有 s = z s=z s=z。然而,Alex说还有 s < z s<z s<z的情况,也就是带交叠的Pooling,顾名思义这指Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元的输入影响,也就是提取出来的结果可能是有重复的(对max pooling而言)。而且,实验表示使用 s = 2 , z = 3 s=2,z=3 s=2,z=3 带交叠的Pooling的效果比 s = 2 , z = 2 s=2,z=2 s=2,z=2的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用。(这里稍作说明,原文的top-1和top-5主要描述的是error rate,属于一种损失,所以用reduce这个词,也就是减少top-1和top-5的error rate。而我的笔记是从与其相反层面上,描述这两个指标,表示击中率类似的含义,所以我用的是提高。)
网络架构分析
这小节是本文的精彩点之一。我们开始讨论AlexNet的网络结构,先看看前面GPU章节所展示的AlexNet架构图。从图中,我们可以看到这是是一个8层网络架构,我在笔记里用带圈数字给每一层都标了号,前5层是卷积层,后3层是全连接层。其中最后的全连接层输出是一个1000通道softmax映射归一化结果,表示输入在1000类别的响应情况,或者说在归属类上的概率分布,再细致的说就是每个通道的softmax输出表示输入属于该类的可能性(而不是得分,见后文说明)。我们网络训练的目标是最大化多项的logistic回归,其实就是最大化这个网络所有输出正确类别的响应的平均值,即 m a x 1 N ∑ i = 0 N l o g ( p ( y i ∣ x i ) ) max \frac{1}{N}\sum_{i=0}^N log(p(y_i|x_i)) maxN1∑i=0Nlog(p(yi∣xi)),其中N是样本数, y i y_i yi代表第i个样本的标记, x i x_i xi代表第i个样本的输入, p ( y i ∣ x i ) p(y_i|x_i) p(yi∣xi)表示网络输入第i个样本,输出其样本标记的可能性,也就是标记通道对应的那个值。
关于softmax,虽然我不想做详细介绍,但我想用知乎上的一段话来总结一下它的作用。“看名字就知道了,就是如果某一个zj大过其他z,那这个映射的分量就逼近于1,其他就逼近于0,主要应用就是多分类,sigmoid函数只能分两类,而softmax能分多类,softmax是sigmoid的扩展”,这里z指的是所有全连接的结果。还有一句“softmax模型是logistic模型在多分类问题上的推广, logistic 回归是针对二分类问题的”。也就是说,由于前面提到过的sigmoid函数对于每个神经元是一个二值饱和函数,在多分类问题上其实挺容易遇到两类的得分很高也接近的情况,这时输出容易模糊(Fuzzy)。而softmax是一个类别的得分的分布情况,要么一起低,要不就有高有低,所以在多分类的时候,容易落实。详细可参考http://www.zhihu.com/question/23765351.
我们再从架构图中观察一些这8层网络的特点。不难发现,第2、4、5个卷积层的输入竟然只跟同一个GPU下前级输出有关系,与之前提到过的一样,而仅有第3层跟前级的所有输出,包括另一个GPU的输出,有关系。这样几乎整个卷积层都实现了并行了,但并非毫无代价的,稍后再解释。然后全连接层肯定是所有输入都得跟所有的前级输出有关,这是毋庸置疑的。之前提到的带交叠的Max-pooling层,我们将它放到1、2、5层。局部归一化(侧抑制)我们让它作用在1、2层跟在Max-pooling的前面。而ReLU是对每层的卷积和全连接作用结果进行激活。
激动人心的时刻到了!经过前三段枯燥的铺垫,我们已经掌握了AlexNet的基本流程与相关的组成部分。现在我们要分析它的具体规模,并且还要分析接近它规模的单GPU网络做对比。
看下用铅笔画的单GPU网络图的规模,输入层大小是 224 × 224 × 3 224\times224\times3 224×224×3,第一层卷积层的大小是 55 × 55 × 96 55\times55\times96 55×55×96,第二层为 27 × 27 × 128 27\times27\times128 27×27×128,第三层为 13 × 13 × 384 13\times13\times384 13×13×384,第四层为 13 × 13 × 192 13\times13\times192 13×13×192,第五层是 13 × 13 × 256 13\times13\times256 13×13×256,最后三个全连接层分别是 4096 × 1 4096\times1 4096×1, 4096 × 1 4096\times1 4096×1, 1000 × 1 1000\times1 1000×1。利用这些数据,我们又可以分析一些卷积层之间的卷积核信息。比如,输入层的深度为3,而第一卷积层的深度是96,也就是说我们这两层之间需要96个 ? × ? × 3 ?\times?\times3 ?×?×3大小的卷积核。可是我们还没有办法知道这个核的大小是多少,因为没有卷积核遍历输入层的步长信息。幸好,作者说这个步长是4,所以我们通过方程 224 + ? 2 − ? 4 = 55 \frac{224+\frac{?}{2}-?}{4}=55 4224+2?−?=55得到?=11。然而,其他卷积核的大小没这好办了,卷积层大小的压缩主要由Max-pooling实现,比如3、4、5层的大小都没有变化(这三层之间没有Max-pooling),而卷积核的大小一般是不直接影响卷积映射结果的大小,因此卷积核大小其实是一个待设定参数。不过,卷积核的深度和个数都是可以计算的,我这里直接按顺序给出剩下3个卷积核,128个 5 × 5 × 96 5\times5\times96 5×5×96,384个 3 × 3 × 128 3\times3\times128 3×3×128, 192个 3 × 3 × 384 3\times3\times384 3×3×384,256个 3 × 3 × 192 3\times3\times192 3×3×192。你可能已经发现规律!是的,每一层卷积核的个数会变成下一层卷积核的深度,这是由卷积形式所决定的。因为每一个卷积核(注意概念,不是一层的卷积核,而是一层卷积核里面的其中一个)对上一层的结果进行操作,都会出来一个属于这个卷积核的结果,那么如果我有128个核就有128个结果,每个结果是一个特征图,然后它们放在一起形成一个多维特征结构,所以我们能看出,CNN卷积层的特征提取操作可以理解为一个多维度分析过程,其实也就是小波变换(如果将卷积核理解成滤波器的话)。那么特征学习其实就是在学习到底哪些维度更能描述这个分类问题。
然后我们回到AlexNet的架构图(印刷图),如果你注意到我的单GPU架构图部分的一些长方体的虚线以及两个小正方体相加的图案,并开始琢磨这俩的含义时,我会说“恭喜你,你看到了点子上!”。其实AlexNet的双GPU架构是,从我所画的这个单GPU架构,通过窍门将它分成两部分。如果还能注意到我跟Alex这个架构图的在规模上的差别的话,你还会发现其实这个窍门的本质几乎所有程序猿都认识——空间换时间。我拿前三层打个比方,第一个卷积层实际上是“无损的”,他只将我原来的 55 × 55 × 96 55\times55\times96 55×55×96的卷积层模型从深度上切分成两块 55 × 55 × 48 55\times55\times48 55×55×48的模型,放到两个不同的GPU位置而已(这里要注意一下哈,我说的卷积层是指感受野或hidden layer,请区别与前面的每层的卷积核,kernel)。逻辑严谨的朋友会发现,这里有一个问题:卷积的时候,一个卷积核需要用到两个GPU的结果,那么多卷积核,GPU之间的交互不应该很频繁么?哪能像Alex 图那样的还光GPU自己里面能倒腾出来,轻松并行呀?(提醒一下,有的人可能没注意到一个卷积核是有深度的)我觉着这个问题非常到位,那要不咱们也把卷积核按照对应深度切开呢?诶,好像有戏!如果确实我们现在看第2层,将原来128个 5 × 5 × 96 5\times5\times96 5×5×96切分成两组128个 5 × 5 × 48 5\times5\times48 5×5×48,得到256个 5 × 5 × 48 5\times5\times48 5×5×48卷积核,分别作用在两个不同GPU上的结果的到两个 27 × 27 × 128 27\times27\times128 27×27×128的卷积层结果。(大家应该都注意到了,这里所需的存储空间已经比之前翻倍了,后文详述。)但是,主要矛盾还没解决,本来两结果要做运算和在一起的,现在还分居两地呢。“要做啥运算啊?”,“好像是直接相加!”,“那很淡定!不还有加法分配律么?”。如果我们将384个 3 × 3 × 128 3\times3\times128 3×3×128复制一份,变成两组相同384个 3 × 3 × 128 3\times3\times128 3×3×128,即一组深度为256的核,分别作用再相加应该就跟原来单GPU一样了。然而,拷贝在训练阶段可能是不靠谱的,因为我们只用了一半的特征做学习而已,到底哪一半数据可行度最高还是未知(不过这个问题可以考虑通过不同时刻利用不同GPU的特征,切换着来训练从而减少核数据的存储压力),而且Alex和我的模型有着本质上的区别,就是ReLU和Max-pooling对每个分离层的作用引入了非线性因素,导致叠加与原来单GPU的情况有很大差别,但我们也能看出选择ReLU的非饱和线性因素在这个地方有点意义。因此我觉着Alex在这依然选择依然采取双核是有他的道理的。经过这点改造后,我们就能得到单GPU的 13 × 13 × 384 13\times13\times384 13×13×384(即深度为384)的卷积层。再将其从深度切成两块放到两个不同的GPU,就是AlexNet的第三层。将上述功夫重复一遍,就是AlexNet的卷积网络部分,这里不做详细介绍Alex的剩下网络,有兴趣看下原文第3章。
最后,我们再点评一下AlexNet的并行架构设计。它实际上只是一个单GPU网络的切割分离,核心技巧是“空间换时间”,它的美妙之处是Alex是刚刚好让卷积网络的分离并行流程做了两次而已,前面介绍的第1、2、3层是一次,第4、5、6层又是一次。而且分离合并的时机也很恰当,假设第2和3层之间不做数据交互合并的话,估计与单GPU模型有着很大的差别,因为非线性因素引入太多了,核也很难再切了。另外,通过对比分析这俩个模型,我怀疑作者前面的单GPU实验设计是有点问题的。他只用了一半AlexNet的kernels来做实验,就暗示单GPU的精度没有双GPU高的结论,我觉得有些欠妥。实际上,单GPU的kernels在其中两层的数目是应比AlexNet的对应的一半要多的,所以这里应该补充一组实验数据。
减少过拟合
我们的这个网络有6千万个参数,尽管ILSVRC的1000个类可以仅用10比特来表示,但这远不足以让我们学习这么大的一个网络。因此我们需要一些手段来处理过拟合问题。下面我们介绍两种基本的减少过拟合方法。
数据增强
在数据集上减少过拟合的最简单的方法就是增加数据集的多样性。然而,我们在比赛中要再额外地收集新样本做训练是很不现实的,一个比赛规则可能不允许,还有就是竞赛组织者也也不会再为我们在比赛中继续收集。那么这就暗示我们应该对现有的数据进行处理,使其具备更强的多样性。而Alex介绍了一种标记保留变换(label-preserving transformation。因为对原数据这种处理的计算量很小,没必要把变换后的结果存放到磁盘(disk)上,所以Alex就把这些计算放在CPU,让CPU独立处理这些数据。如此一来,数据增强就能供得上CNN的训练。再说明一下,CPU是不参与网络训练的,因为整个CNN都放到了两个GPU里面,由GPU负责训练。
标记保留变换的方式又分两种,一种是图像的平移和水平镜像,另一种RGB通道的亮度的改变。我们先看图像的平移和水平镜像。我们在原大小 256 × 256 256\times256 256×256的样本(及其水平镜像的结果)中随机抽取 224 × 224 224\times224 224×224的部分作为训练样本,从而是样本数目激增至原来的2048(即 ( 256 − 224 ) 2 × 2 (256-224)^2\times2 (256−224)2×2)倍。Alex觉着如果不这么做,网络就会收到本身过拟合的影响,从而只好将网络变小。然而,最近一篇16年CVPR的文章,关于行人检测的综述——“How Far are We from Solving Pedestrian Detection”,表示AlexNet这种CNN深度学习分类器容易导致行人局部误检的出现。因此即便该方法能处理过拟合,但我认为在某些情况还是不太应该用这种样本局部抽取的方式来增加多样性。回到原文,由于我们的抽取使得我网络的输入变成了 224 × 224 224\times224 224×224,我们需要对网络测试方法稍作变动,我们先抽取测试集图像的四个角以及中间的 224 × 224 224\times224 224×224部分,还包括镜像共有10个部分(Patch)结果,再对对这10个输入的测试结果做平均作为我们对该测试集图片的最终测试结果。
接着我们来看看改变RGB通道亮度的方法。我们对训练集中的每张图片都做PCA,得到对应的特征向量 [ p 1 , p 2 , p 3 ] [p_1,p_2,p_3] [p1,p2,p3]和特征值 [ λ 1 , λ 2 , λ 3 ] [\lambda_1,\lambda_2,\lambda_3] [λ1,λ2,λ3]。在训练过程中,每当这张样本被重复一次,我们就对张样本的每一个像素按照公式: I x y ′ = I x y + [ p 1 , p 2 , p 3 ] [ α 1 λ 1 , α 2 λ 2 , α 3 λ 3 ] T I_{xy}'=I_{xy}+[p_1,p_2,p_3][\alpha_1\lambda_1,\alpha_2\lambda_2,\alpha_3\lambda_3]^T Ixy′=Ixy+[p1,p2,p3][α1λ1,α2λ2,α3λ3]T 进行变换,得到一张“新”样本做下一轮的训练。其中 α i \alpha_i αi每次到这样样本时,都需要用均值为0,标准差为0.1的高斯随机数发生器产生一个新的值,从而获得富有多样性的样本。Alex在文中表示这个方法能使Top-1误差率减少1%。
掉线机制(Dropout)
之前我一直把dropout理解成丢弃,即训练过程中偶尔对某些网络节点进行丢弃,知道Alex这篇文章点醒了我,应该理解为掉线,或者是逃学,甚至是休学,而非辍学。毕竟这部分节点只是在某轮迭代逃学了而已,但还是有上学的情况,而辍学直接放弃了。其实休学是最贴切的,因为这些节点是为了避免过拟合的需要而暂时停止更新而已。这个掉线机制也是Alex这篇文章的又一亮点。
运用多个不同的网络模型组合起来预测结果,确实能提高不少准确率,但是对于一个训练一次差不多要好几天的网络看来,这貌似太不实际了。然而,我们可以用一种很巧妙的方式来实现这种效果,既组合了各种不同的网络模型,而且代价也就跟训练一个网络一样没有多大差别。这种方式就是掉线机制,即每轮迭代时,网络中每个隐含层的输出节点都有一半的可能性被置为0,使其掉线不参与此轮迭代,包括前向传播与反向传播。如此一来,我们每一轮的训练都是在不同架构的网络下进行的,并且还实现权值的共享,减少了神经节点的共适应复杂度,因为一个节点并不依赖于其它特定节点们的作用。我们通过下图笔记部分的例子进一步体验下掉线机制的美!
比如,现在我们希望的输入样本为
x
x
x时,输出结果是
y
1
y_1
y1。换句话说,其实是我们希望得到条件概率
P
(
y
1
∣
x
)
P(y_1|x)
P(y1∣x)最大几乎等于1,而
P
(
y
2
∣
x
)
P(y_2|x)
P(y2∣x)最小几乎为0。假设模型是完全线性的,现在我们只管把
P
(
y
1
∣
x
)
P(y_1|x)
P(y1∣x)搞大,从笔记上公式
P
(
y
1
∣
x
)
=
m
1
ω
11
+
m
2
ω
21
P(y_1|x)= m_1\omega_{11}+m_2\omega_{21}
P(y1∣x)=m1ω11+m2ω21 计算上看,我们知道
y
1
y_1
y1上的输出跟中间层的两个节点输出
m
1
m_1
m1和
m
2
m_2
m2都有关系。笔记上列举三种情况,分别是
(
m
1
,
0
)
(m_1,0)
(m1,0),
(
0
,
m
2
)
(0,m_2)
(0,m2),
(
m
1
,
m
2
)
(m_1,m_2)
(m1,m2),这里不讨论(0, 0)的情形,至于为什么请你静静思考一下。我们看下
(
m
1
,
0
)
(m_1,0)
(m1,0)的情形,这其实就相当于图{1->m1, 2->m1, m1->y1}的模型,而
(
m
1
,
0
)
(m_1,0)
(m1,0)就相当于图{1->m2, 2->m2, m2->y1}的情形。
(
m
1
,
m
2
)
(m_1,m_2)
(m1,m2)实际上就是全图{1->m1, 2->m1, m1->y1, 1->m2, 2->m2, m2->y1}的情形。话说为啥忽略y2呢?因为我比较爱用cross-entropy作为loss来训练,加权平均的时候,表示y1类别的one-vector在y2上的值肯定为零,自然就没了。
这么看来掉线机制其实也是挺不错的一种避免过拟合的训练机制。不过因为我们在训练阶段采取了这种手段,所以在测试的时候应注意对每个参与掉线机制的节点的输出乘上一个0.5因子,合理地逼近预测输出分布的几何均值,毕竟这个预测分布多少会受点掉线机制的影响。Alex主要在前两个全连接层(FC)使用了这项训练机制。

训练详情
Alex的训练采用常见的随机梯度下降法,他使用的batch size参数是128。关于batch处理,我顺带讨论一些个人见解。深度神经网络所使用的样本量是超级巨大的,如果想过去那样先把数据都加载到内存再运行程序的话,内存(包括显存)的资源很容易被耗尽,相当吃不消。因此就引入了batch处理技术,它其实算是一种分组处理方式,只是多了一个机会均等的随机抽取机制。而且,适合的batch size不仅有利于充分利用内存资源,还能优化训练时长,减缓过拟合的影响。这是因为batch采样机制的随机引入了均匀分布的采样噪声,那些被重复采样多次的样本过拟合得到的参数,会被首次采样的样本破坏而影响其过拟合效应,某种层面上看,这也有利于拟合找到全局最优点,所以同时也优化了训练时长。
继续回到AlexNet训练参数的介绍,他的学习冲量(momentum)更新率设置为0.9,参数权值衰减(weight decay)学习率为0.0005。关于这个学习率,Alex认为它很重要,它能够减少训练引入的误差,是一个regualrizer。这里直接给出更新规则公式:
v
i
+
1
=
0.9
∙
v
i
−
0.0005
∙
ϵ
∙
ω
i
−
ϵ
∙
⟨
∂
L
∂
ω
∣
ω
i
⟩
D
i
v_{i+1}=0.9\bullet v_i-0.0005\bullet\epsilon\bullet\omega_i-\epsilon\bullet{\left\langle{\frac{\partial L}{\partial \omega}|_{\omega_i}}\right\rangle }_{D_i}
vi+1=0.9∙vi−0.0005∙ϵ∙ωi−ϵ∙⟨∂ω∂L∣ωi⟩Di
ω
i
+
1
=
ω
i
+
v
i
+
1
\omega_{i+1}=\omega_i+v_{i+1}
ωi+1=ωi+vi+1
其中,
i
i
i是迭代的轮数,表示这次是第几次的迭代,
v
v
v是更新冲量,
ϵ
\epsilon
ϵ是学习率,以及
⟨
∂
L
∂
ω
∣
ω
i
⟩
D
i
{\left\langle{\frac{\partial L}{\partial \omega}|_{\omega_i}}\right\rangle }_{D_i}
⟨∂ω∂L∣ωi⟩Di训练
D
i
D_i
Di(第
i
i
i个batch)时,目标函数关于
ω
\omega
ω的方向导数在
ω
i
\omega_i
ωi时的值。
还有就是,每层网络的权值(weights)都用标准差为0.01的零均值高斯分布来初始化,而2、4、5卷积层的偏置(biases),以及全连接层的偏置,我们都用1来初始化,剩下没提到的偏置都用0来初始化。这种初始化方式起着一定的训练加速作用。
至于学习率,我们所有网络都应该采用相同的学习率,这个学习率是一个经验值。有一个获取这个经验值的启发式方法,就是每次都对当前的学习率除以10,直到交叉验证的error rate不再改善为止。Alex他们初始化的学习率为0.01,验证了3次就停止了。他们对imageNet的1.2百万张图片训练的大概90次,在NVIDIA GTX 580 3G GPUs上跑了五到六天。不过迭代90次样本就出这么好的结果,也算是不错了。
实验分析
由于时间关系,我这里只能给出原文的实验结果和讨论相对重要的实验分析,但并不代表这部分不重要,文章的实验部分能让我们明白这一领域算法改善的评价体系,我们通过分析这一评价体系的合理性,也就能分析出该文章的含金量。
<img src=“https://img-blog.csdn.net/20160924091759566”, width=45% /> <img src=“https://img-blog.csdn.net/20160924092026176”, width= 50% />
<img src=“https://img-blog.csdn.net/20160924092322231”, width=100%/>
<img src=“https://img-blog.csdn.net/20160924092957243”, width=100% />
Figure3给出了第一个卷积层的卷积核图片,很多文章都爱把这个给出来,不过一般没多少人看得懂。Table1是ILSVRC-2010的测试结果,Table2是ILSVRC-2012的测试结果。其中值得一提的是,Table2中的“1 CNN*”表示的是在原来第六层的pooling后面添加了一个所谓的第六卷积层,并对ImageNet 2011 Fall的数据做pre-training,暗示pre-training对网络的效果一点积极总用。不过,我认为这里的还不能完全说明这一点,毕竟“5 CNNs”和“7 CNNs”也说定有1%的区别,因此我觉着他这组对比实验的说服力不是很够。
最后,我认为比较有趣的是Figure4右边的数据。Alex将全连接层最后一个隐含层的特征数据拿出来做对比,发现这4096维数据的欧氏距离比较接近的Raw输入数据竟然都长得相当接近。我认为这充分表明AlexNet的特征提取能力的有效性,深度学习有足够的能力找到多类数据的规律。
(FIN)















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









