







字符串匹配操作定义:
目标串S="S0S1S2...Sn-1" , 模式串T=“T0T1T2...Tm-1”
对合法位置 0<= i <= n-m (i称为位移)依次将目标串的字串 S[i ... i+m-1] 和模式串T[0 ... m-1] 进行比较,若:
1、S[i ... i+m-1] = T[0 ... m-1] , 则从位置i开始匹配成功,称模式串 T 在目标串 S 中出现。
2、S[i ... i+m-1] != T[0 ... m-1] ,则从位置i开始匹配失败。
1、字符串匹配算法一 —— Brute-Force 算法(很黄很暴力)
字符串匹配过程中,对于位移i (i在目标串中的某个位置),当第一次 Sk != Tj 时,i 向后移动1位 , 及 i = i+1,此时k退回到i+1位置 ;模式串要退回到第一个字符。该算法时间复杂度O(M*N),但是实际情况中时间复杂度接近于O(M + N),以下为Brute-Force算法的java实现版本:
public static int bruteForce(String target, String pattern, int pos) {
if (target == null || pattern == null) {
return -1;
}
int k = pos - 1, j = 0, tLen = target.length(), pLen = pattern.length();
while (k < tLen && j < pLen) {
if (target.charAt(k) == pattern.charAt(j)) {
j++;
k++;
} else {
k = k - j + 1;
j = 0;
}
}
if (j == pLen) {
return k - j + 1;
}
return -1;
}
2、字符串匹配算法二 —— KMP(D.E.Knuth 、J.H.Morris 和 V.R.Pratt)算法
其思想是每一次出现不匹配的字符时,尽可能的向前滑动位移,而这个滑动的位移取决于模式串(暂且称为next[j]),nextj的定义
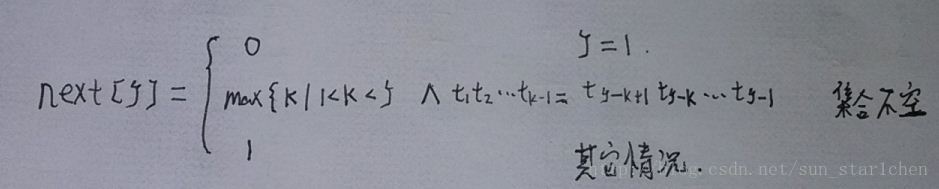
关于模式串nextj的求解示例可参见http://www.56.com/u59/v_NjAwMzA0ODA.html
下面运用上述原理求解模式串 T=“abcdsaaabcdsabbc”,next[1]=0;第一个字符始终为0。
对于位置 j = 2 , Tj = b,由于k不可能大于1 , 满足第三种情况:
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 |
对于位置 j = 3 , j前面的字符串T' = "ab",不存子序列T'' 开始的字符串相等 ,所以next[3]=1
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 |
同理对于位置 j = 4,5,6 ; next[j] = 1 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 |
对于位置 j = 7 , Tj = a , j前面的字符串T' = "abcdsa",存在一个最大长度为1的字串和开始的字符串相等,所以next[7] = 2:
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 |
同理对于位置 j = 8,9 ; next[j] = 2 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 |
对于位置 j = 10 , j 前面的字符串 T' = "abcdsaaab", 存在一个最大长度为2的子序列(ab)和开始的字符串相等,所以next[10] = 3 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 |
对于位置 j = 11 , j 前面的字符串 T' = "abcdsaaabc", 存在一个最大长度为3的子序列(abc)和开始的字符串相等,所以next[11] = 4 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 4 |
对于位置 j = 12 , j 前面的字符串 T' = "abcdsaaabcd", 存在一个最大长度为4的子序列(abcd)和开始的字符串相等,所以next[12] = 5 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 4 | 5 |
对于位置 j = 13 , j 前面的字符串 T' = "abcdsaaabcds", 存在一个最大长度为5的子序列(abcds)和开始的字符串相等,所以next[13] = 6 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 4 | 5 | 6 |
对于位置 j = 14 , j 前面的字符串 T' = "abcdsaaabcdsa", 存在一个最大长度为6的子序列(abcdsa)和开始的字符串相等,所以next[14] = 7 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 |
对于位置 j = 15 , j 前面的字符串 T' = "abcdsaaabcdsab", 存在一个最大长度为2的子序列(ab)和开始的字符串相等,所以next[15] = 3 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 | 3 |
对于位置 j = 16 , j 前面的字符串 T' = "abcdsaaabcdsabb", 不存在子序列和开始的字符串相等,所以next[16] = 1 :
| a | b | c | d | s | a | a | a | b | c | d | s | a | b | b | c |
| 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 | 3 | 1 |
上述按算法思想按照人类的语言来组织求解了,但是对于更长的模式串nextj又该如何求呢?肯定不会是人工来算的啦^_^,那么计算机如何来求这个nextj函数呢?求解nextj的原理其实这里面 http://www.56.com/u59/v_NjAwMzA0ODA.html已经有了,简单来说就是:
对于T[j] = k , 则说明对于j前面有一个字串 T [1,2...k-1] =T [ j-k+1 , j-k+2....j-1]相等。
如果 T[j] = T[k] , 那么必定存在一个字串 T[1,2,...k-1,k] = T [j-k+1 , j-k+2 ... j-1,j]相等。
则==> T[j+1] = k+1 ;
例如上面例子中的 T[10] = 3
j =10 , k = 3 , 又T10 = T3=c,所以 T[11] =4 ;
如果T[j] != T[k] , 则需要回溯,T[j] = T[?]
例如上例中的 T[14] = 7 , j=14 , k=7 , 但是T7 =a ,T14 = b , a != b , 此时就需要回溯,怎么回溯呢? j 不变 , k 回溯到 T[k] , k=7 ,
k = T[7] = 2 ,
再判断 Tj 是否等于 Tk , T14 = b , T2 = b ; ==>T15 = t2
所以 T[15] = T[2] +1 ; ==> T[15] = 3
再来看看上例中的T[15] = 3, j =15 , k =3 ;
T3 = c , T15 = b ; ==> T3 != T15
回溯,k = T[k] = T[3] , T[3] = 1 ; ==> k = 1 ;
但是T15 = b 不等于 T1 = a ;
继续回溯: k = T[1] = 0 ;
通过nextj的定义可以知道只有第一个字符的nextj值为0 , 此时表明已经回溯到了第一个字符,此时 k 和 j 都要向后移动一位。
下面给出nextj 的Java实现代码:
private static int[] next(String t) {
String s = " " + t;
int k = 1, j = 0, sLen = s.length();
int real_next[] = new int[t.length()];
int next[] = new int[sLen];
while (k < sLen) {
if (j == 0 || s.charAt(k) == s.charAt(j)) {
k++;
j++;
if (k >= sLen)
break;
next[k] = j;
// nextj 函数的优化部分
// if (s.charAt(k) != s.charAt(j)) {
// next[k] = j;
// } else {
// next[k] = next[j];
// }
// 优化代码结束
}
else {
j = next[j];
}
}
System.arraycopy(next, 1, real_next, 0, real_next.length);
// for (int i = 0; i < real_next.length; i++) {
// System.out.print(real_next[i] + " ");
// }
// next = null;
return real_next;
}在上述代码中看到了对next部分优化的代码,为什么要优化呢?上述链接的视频中讲得很清楚了。具体说就是要考虑源字符串了:
对于源串S ,模式串T :
如果Si != Tj , 那么此时 j 就会回溯到 位置 k 上 , k = T[j] (上述例子就是这种方法啦 )。
但是如果 Tj = Tk , ==> Si != Tk
此时 就该比较 k' , k' = T[k] , 这么说来 比较 Si 和 Tk 相当于是脱了裤子放屁,多此一举。我们就应该直接用 Si 和 T[k'] 进行比较
即是: Si = Tk' , k' = T[ T[j] ] ==> T[j] = T[ T[j] ];
nextj 函数求解完了, 下面接着看 KMP算法
KMP搜索部分的代码网上也很多了, 其代码结构和 Brute-Force 搜索算法的代码结构类似,下面直接看代码:
/**
* 字符串匹配,KMP算法
*
* @param s 源字符串
* @param t 匹配的目标字符串
* @param pos 匹配字符串的初始位置 , pos = 1, 2, .... , s.len
* @return 模式串在源字符串中从pos位置开始搜索第一次出现的位置
*/
public static int stringMatchKmp(String s, String t, int pos) {
if (s == null || t == null || s.length() < t.length() + pos) {
return -1;
}
int k = pos - 1, j = 0, tLen = t.length(), kPos = s.length() - tLen;
int[] nextj = next(t);
while (k <= kPos && j < tLen) {
if (j == 0 || s.charAt(k) == t.charAt(j)) {
k++;
j++;
} else {
if(j == nextj[j]){
k++;
}
j = nextj[j];
}
}
if (j >= tLen) {
return k - tLen + 1;
}
return -1;
}if(j == nextj[j]){
k++;
}
朋友们使用过程中若发现出问题了,别忘了告诉我一声哦^_^...
关于字符串匹配的算法暂时就写到这里,更多内容后续再补充。















 2949
2949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









