






- 时间 2016.5.4~2016.7.20
- 成果:
- 基于Voice Conversion的demo:VC demo百度网盘分享
- 基于TTS adaption的demo:TTS adaption demo百度网盘分享
- TTS demo:基于HMM的TTS demo百度网盘分享
- AHOcoder(Linux 64bit):AHOcoder、AHOdecoder
- 方案:
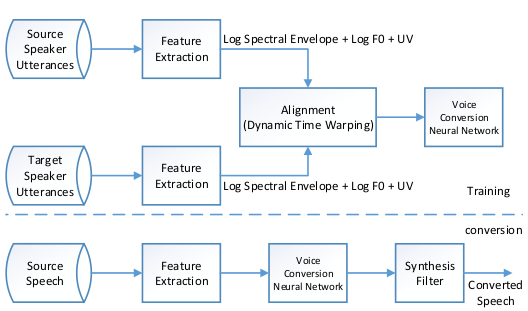
- 基于Voice Conversion 的语音序列转换
- 总体思路
- 总体思路
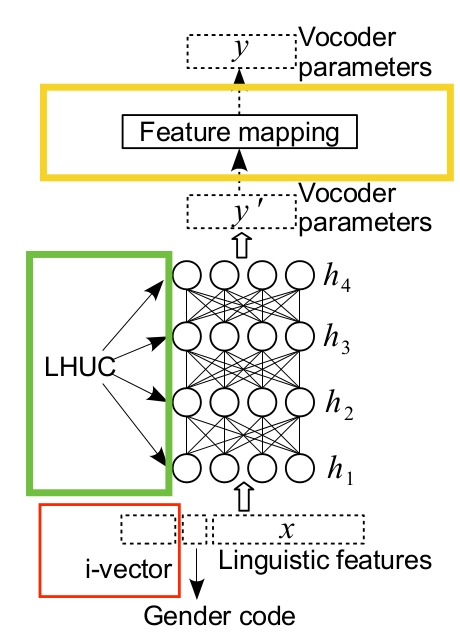
- 基于TTS的adaption(使用DNN或HTS demo中方法)
- 基于Voice Conversion 的语音序列转换
可行性分析
Voice Conversion 方法可以尝试,但效果达不到在工业界上应用的标准,学术界有利用GMM、DNN、RNN进行特征转换的尝试,最少能利用5句话进行训练,demo效果一般。链接如下:
- 微软:DNN VC
- 香港科技大学:BLSTM VC
- 印度OHSU:Joint AE VC
- 日本东京大学:GMM VC
- 法国tut:基于DKPL回归
- Voice Morphing:Voice Morphing
TTS方法较VC方法效果更好,百度和微软使用,如百度的个性化TTS,没有找到相关产品链接。学术界的demo链接如下:
- 关键点
- 声音编码解码器:AHOcoder,STRAIGHT,HTK,Sphinx,Kaldi
- 时间序列对齐算法:SPTK中dtw,或一些matlab代码
- 参数生成算法:考虑global variance的parameter generation algorithm,参考hts_engine源码
- 模型:GMM,FFNN,SJAE,RNN(BLSTM)
- TTS:HMM+神经网络
- adaption算法:参考hts_engine源码,或一些基于DNN的adaption算法
- 。。。等
GMM方法介绍
- 对cmu语料库,使用wav2raw将16khz的raw文件转换为wav文件,再使用sox命令将wav文件转换为AHOcoder所要求的格式的文件
- 用./ahocoder .wav .lf0 .mgc生成lf0和mgc文件,可分别选5句话作为train,其余作为test
- 使用adaption.sh对lf0进行adaption转换,首先要选好train和test的list,之后进行adaption
- 对mgc进行dtw
- 生成gmm模型function [G,P]=gmmtrain(X,m)
- 进行blfwas转换训练function [alfa,R]=blfwastrain(X,Y,P)
- 进行测试:
- 对向量分类function [P,L]=gmmprobs(G,X)
- 进行blf转换,并把c0加进去,function Y=blfwasconv(X,alfa,R,P))
个性化语音——总结
最新推荐文章于 2022-06-07 06:09:10 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









