






本篇是在上上篇(python 手势识别)的基础上多加了一部分函数,来显示识别手势表示的数字,并将识别结果显示在屏幕上
大概思路是:利用OpenCV(cv2)和mediapipe包,对图像做出一系列处理,比如图像的翻转、图像中手势的识别、手的21个结点的显示和坐标计算,最后通过对每个手指的指尖位置和第二个关节的x坐标(大拇指)或y坐标(其他四个手指)的大小判断来识别该手指是张开还是闭合,最后在代码中放入六张图片来显示0、1、2、3、4、5
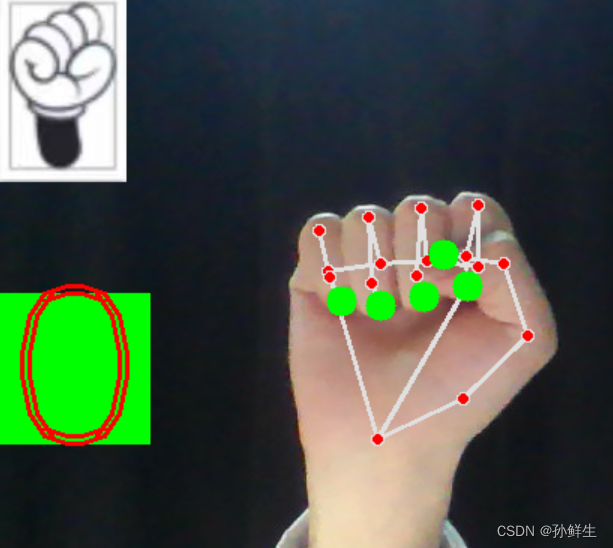
代码运行成功后大概是这样的:(以数字0为例)
hand.py
import cv2
# 从handms文件中导入HandDetector类
from handms import HandDetector
# 打开摄像头
cap = cv2.VideoCapture(0)
# 创建一个手势识别对象
detector = HandDetector()
# 6张手的图片,分别代表0~5
finger_img_list = [
'D:/project1/0.jpg',
'D:/project1/1.jpg',
'D:/project1/2.jpg',
'D:/project1/3.jpg',
'D:/project1/4.jpg',
'D:/project1/5.jpg',
]
# 创建一个列表来存放表示0~5的图片
finger_list = []
# 遍历finger_img_list列表
for gesture in finger_img_list:
# 用cv2.imread()函数把图片依次取出来
i = cv2.imread(gesture)
# 把取出来的图片存到finger_list列表中
finger_list.append(i)
# 指尖地表值,分别代表大拇指、食指、中指、无名指和小指的指尖
tip_ids = [4, 8, 12, 16, 20]
while True:
# 不断取出从摄像头捕获的视频图像,返回两个数,一个是是否成功取出,另一个是捕获到的图像
success, img = cap.read()
# 如果成功取出
if success:
# 先翻转图像,因为从摄像头取出图像是翻转,我们需要镜像的
img = cv2.flip(img, 1)
# 调用HandDetector类中的find_hands成员方法,识别出img中的手,并画出21个手势地标
img = detector.find_hands(img, draw=True)
# 调用find_positions成员方法,计算出21个手势地标的索引值和坐标
sun = detector.find_positions(img)
# 如果sun中有元素
if len(sun) > 0:
# 先定义一个空列表,用户存放0和1,0表示手指闭合,1表示手指张开
fingers = []
# 遍历5根手指的指尖
for tid in tip_ids:
# 取出指尖的x坐标和y坐标
x, y = sun[tid][1], sun[tid][2]
# 在指尖上画一个圆
cv2.circle(img, (x, y), 10, (0, 255, 0), cv2.FILLED)
# 如果是大拇指
if tid == 4:
# 如果大拇指指尖的x位置大于第二个关节的第二个位置,则认为大拇指打开
if sun[tid][1] > sun[tid - 1][1]:
# 给fingers列表添加一个1元素,表示一个手指张开,识别到的数字就加一
fingers.append(1)
else:
# 给fingers列表添加一个0元素,表示一个手指闭合,识别到的数字就不变
fingers.append(0)
# 如果是其他手指
else:
# 如果这些手指的指尖的y位置大于第二关节的位置,则认为这个手指打开,否则认为这个手指关闭
if sun[tid][2] < sun[tid - 2][2]:
fingers.append(1)
else:
fingers.append(0)
# 判断有几个手指打开
cnt = fingers.count(1)
# 找出对应的数字图片,并显示
finger_img = finger_list[cnt]
# 计算所要添加图片的长和宽
w, h, c = finger_img.shape
# 在img图像的左上角添加图片
img[0:w, 0:h] = finger_img
# 在对应img的对应坐标位置添加一个矩形(绿色),并填充该矩形
cv2.rectangle(img, (0, 200), (100, 300), (0, 255, 0), cv2.FILLED)
# 在矩形中添加识别到的数字(红色)
cv2.putText(img, str(cnt), (0, 300), cv2.FONT_HERSHEY_DUPLEX, 5, (0, 0, 255), 2)
# 将img显示在以Image命名的窗口
cv2.imshow('Image', img)
# 等待按下一个键,并将该键的ASCII码值赋值给变量k
k = cv2.waitKey(1)
# 如果按下的是q,则退出循环
if k == ord('q'):
break
# 释放VideoCapture对象,防止程序占用摄像头,以释放资源
cap.release()
# 关闭所有由OpenCV创建的窗口
cv2.destroyAllWindows()handms.py
import cv2
import mediapipe as mp
class HandDetector:
def __init__(self):
# 先定义results和handsjh两个成员变量,先将其定义为空
self.results = None
self.handsjh = None
# 给mp.solutions.hands.Hands()函数一个较为简单的名字hands,使后续代码比较简短
self.hands = mp.solutions.hands.Hands()
def find_hands(self, img, draw=True):
# 将img图像由BGR转换成RGB
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 处理手部检测和追踪的数据,并返回一个mp.solutions.hands.Hands()对象,其中包含了检测到的手部数据
self.results = self.hands.process(imgRGB)
if draw:
# 确定是否有多只手的检测结果
if self.results.multi_hand_landmarks:
# 遍历multi_hand_landmarks中的数据
for handlms in self.results.multi_hand_landmarks:
# 画出21个手势地标并其连起来
mp.solutions.drawing_utils.draw_landmarks(img, handlms, mp.solutions.hands.HAND_CONNECTIONS)
return img
def find_positions(self, img, hand_no=0):
# 先将handsjh定义为空列表
self.handsjh = []
if self.results.multi_hand_landmarks:
# 选择索引值为hand_no的手部地标数据,并将其赋值给变量hand
hand = self.results.multi_hand_landmarks[hand_no]
# 使用enumerate()函数对该手的每一个地标进行遍历,并将地标的索引值赋值给id,,并将每个地标的x、y值赋值给lm
for id, lm in enumerate(hand.landmark):
# 计算图像img的长和宽
h, w, c = img.shape
# 计算每个地标在img图像对应位置的x、y坐标
cx, cy = int(lm.x * w), int(lm.y * h)
# 将计算到的数据存放到handsjh列表中
self.handsjh.append([id, cx, cy])
return self.handsjh注:该代码只有在左手手心朝屏幕和右手手背朝屏幕时,识别到的数字才是正确的,具体原因等你读懂了代码就知道是什么原因了
扩展
对新增的两个函数做出一下解释:
cv2.rectangle()
一个用于在图像上绘制矩形框的函数。它可以用于标记、选择或突出显示图像中的特定区域。
以下是cv2.rectangle()函数的参数说明:
必需参数:
img:图像数据,可以是一个整数,表示图像的灰度值,或者是一个三维数组,表示图像的 RGB 颜色值。
pt1:矩阵的顶点。
pt2:与pt1相对的矩阵顶点。
可选参数:
color:矩阵颜色。
thickness:构成矩形的线条的粗细,如果为负值则为填充矩形。
lineType:行类型,可以为 4、8 以及 16。
shift:点坐标中的小数位数。
这个函数将在给定的图像上绘制一个矩形,其左上角坐标为pt1,右下角坐标为pt2。你可以根据需要调整这些坐标来指定矩形的位置和大小。
cv2.putText()
OpenCV 库提供的一个用于在图像上添加文本的函数。它可以将文本信息显示在图像上,常用于图像的标注、注释或可视化。
以下是cv2.putText()函数的参数说明:
必需参数:
img:图像数据,可以是一个整数,表示图像的灰度值,或者是一个三维数组,表示图像的 RGB 颜色值。
text:要添加的文本内容。
可选参数:
org:文本的初始位置。这是一个包含文本左下角坐标的元组(x,y)。
fontFace:字体的名称。
fontScale:字体的大小。
color:文本的颜色。
thickness:文本的线条粗细。
lineType:文本的线型。
bottomLeftOrigin:如果为真,则坐标(0,0)表示图像的左下角。否则,它表示图像的左上角。
使用cv2.putText()函数,你可以在图像上指定的位置添加文本,并设置文本的字体、大小、颜色等属性。
















 7263
7263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











