







推荐算法主要分为3类:基于内容的推荐,协同过滤和混合推荐。
协同过滤主要利用user和item之间的互动信息。分为三种类型:user-based, item-based和model-based。
数据集
根据数据集的性质,可以分为显式反馈(评分,星级)和隐式反馈(浏览,点击,加入购物车)。
movielens数据集中,用户对电影的打分在1-5,是显式反馈。movielens-100k中有943个用户和1682个电影的交互信息。
import pandas as pd
import numpy as np
filename = "../Data/ml-100k/u.data"
separator = "\t"
col_names = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv(filename, sep=separator, names=col_names)
n_users = df.user_id.unique().shape[0]
n_items = df.item_id.unique().shape[0]
print(str(n_users) + ' users') #943 users
print(str(n_items) + ' items') #1682 items将其转为user-item矩阵。注意虽然把缺失的评分项置为0,但不代表真实的评分为0,只是空项。接着需要将数据划分为训练集和测试集,对于每个用户,从用户的所有评分中选出10个作为测试集。
ratings = np.zeros((n_users, n_items))
for row in df.itertuples():
ratings[row[1]-1, row[2]-1] = row[3]
sparsity = float(len(ratings.nonzero()[0]))
sparsity /= (ratings.shape[0] * ratings.shape[1])
sparsity *= 100
print('Sparsity: {:4.2f}%'.format(sparsity))
# Sparsity: 6.30%
def train_test_split(ratings):
test = np.zeros(ratings.shape)
train = ratings.copy()
for user in range(ratings.shape[0]):
test_ratings = np.random.choice(ratings[user, :].nonzero()[0],
size=10,
replace=False)
train[user, test_ratings] = 0.
test[user, test_ratings] = ratings[user, test_ratings]
# Test and training are truly disjoint
assert (np.all((train * test) == 0))
return train, test
train, test = train_test_split(ratings)user-based & item-based
在user-based和item-based协同过滤中,需要建立一个相似矩阵。用户相似矩阵中是每对用户间的相似度,项相似矩阵中是每对项的相似度。一种常用的计算相似度的方法是cosine。
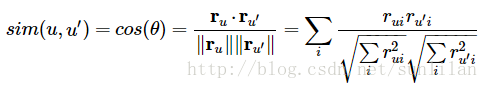
def fast_similarity(ratings, kind='user', epsilon=1e-9):
# epsilon -> small number for handling dived-by-zero errors
if kind == 'user':
sim = ratings.dot(ratings.T) + epsilon
elif kind == 'item':
sim = ratings.T.dot(ratings) + epsilon
norms = np.array([np.sqrt(np.diagonal(sim))])
return (sim / norms / norms.T)
user_similarity = fast_similarity(train, kind='user')
item_similarity = fast_similarity(train, kind='item')得到相似度矩阵后,可以进行预测。对于user-based推荐,用户对项的评分被预测为其他用户对该项评分的加权和,权值为其他用户与该用户的相似度,用其他用户与该用户的相似度的和进行规范。
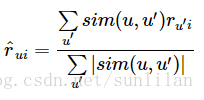
def predict_fast_simple(ratings, similarity, kind='user'):
if kind == 'user':
return similarity.dot(ratings) / np.array([np.abs(similarity).sum(axis=1)]).T
elif kind == 'item':
return ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])使用mean squared error对模型进行评价。mse的计算公式如下:
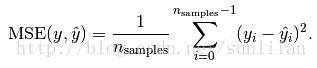
from sklearn.metrics import mean_squared_error
def get_mse(pred, actual):
# Ignore nonzero terms.
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
item_prediction = predict_fast_simple(train, item_similarity, kind='item')
user_prediction = predict_fast_simple(train, user_similarity, kind='user')
user_mse = get_mse(user_prediction, test)
item_mse = get_mse(item_prediction, test)
print('User-based CF MSE: ' + str(user_mse))
print('Item-based CF MSE: ' + str(item_mse))top-k推荐
与上一种方法不同的是,top-k推荐只考虑与输入用户最相似的k个其他用户。调整参数k的取值获得最优解。
def predict_topk(ratings, similarity, kind='user', k=40):
pred = np.zeros(ratings.shape)
if kind == 'user':
for i in range(ratings.shape[0]):
top_k_users = [np.argsort(similarity[:,i])[:-k-1:-1]]
for j in range(ratings.shape[1]):
pred[i, j] = similarity[i, :][top_k_users].dot(ratings[:, j][top_k_users])
pred[i, j] /= np.sum(np.abs(similarity[i, :][top_k_users]))
if kind == 'item':
for j in range(ratings.shape[1]):
top_k_items = [np.argsort(similarity[:,j])[:-k-1:-1]]
for i in range(ratings.shape[0]):
pred[i, j] = similarity[j, :][top_k_items].dot(ratings[i, :][top_k_items].T)
pred[i, j] /= np.sum(np.abs(similarity[j, :][top_k_items]))
return pred
pred = predict_topk(train, user_similarity, kind='user', k=40)
print('Top-k User-based CF MSE: ' + str(get_mse(pred, test)))
pred = predict_topk(train, item_similarity, kind='item', k=40)
print('Top-k Item-based CF MSE: ' + str(get_mse(pred, test)))
# Top-k User-based CF MSE: 6.47059807493
# Top-k Item-based CF MSE: 7.75559095568bias-subtracted推荐
该方法的思想是:一些用户对电影进行评分时倾向于打高分或低分。因此在对相似用户的评分进行加和时,会减去每个用户的平均评分,最后再加回平均评分。
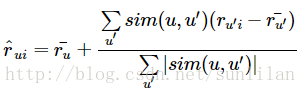
def predict_nobias(ratings, similarity, kind='user'):
if kind == 'user':
user_bias = ratings.mean(axis=1)
ratings = (ratings - user_bias[:, np.newaxis]).copy()
pred = similarity.dot(ratings) / np.array([np.abs(similarity).sum(axis=1)]).T
pred += user_bias[:, np.newaxis]
elif kind == 'item':
item_bias = ratings.mean(axis=0)
ratings = (ratings - item_bias[np.newaxis, :]).copy()
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
pred += item_bias[np.newaxis, :]
return pred
user_pred = predict_nobias(train, user_similarity, kind='user')
print('Bias-subtracted User-based CF MSE: ' + str(get_mse(user_pred, test)))
item_pred = predict_nobias(train, item_similarity, kind='item')
print('Bias-subtracted Item-based CF MSE: ' + str(get_mse(item_pred, test)))
# Bias-subtracted User-based CF MSE: 8.67647634245
# Bias-subtracted Item-based CF MSE: 9.71148412222matrix factorization
传统的奇异值分解要求矩阵不能有缺失数据,必须是稠密的。而用户物品评分矩阵是一个很典型的稀疏矩阵,直接使用传统的SVD进行协同过滤是比较复杂的。
推荐中的矩阵分解算法有:FunkSVD,BiasSVD,SVD++。这些算法和传统SVD的最大区别是不再将矩阵分解为
UΣVT
U
Σ
V
T
,而是两个矩阵
PTQ
P
T
Q
。
ALS SGD
。。。 。。。
参考文献:
http://www.cnblogs.com/pinard/p/6349233.html
http://blog.ethanrosenthal.com/2015/11/02/intro-to-collaborative-filtering/














 7603
7603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









