






Topics and Logs
首先我们深入Kafka为一串记录提供的核心抽象概念:Topic
Topic是一个record发行的类型或者流入名称。Kafka中topic经常有多高订阅者。同时,topic可以拥有零个、一个或者多个消费者来订阅这个topic来消费record.
每一个topic,Kafka集群中保持着一个分区的log 如下图所示:
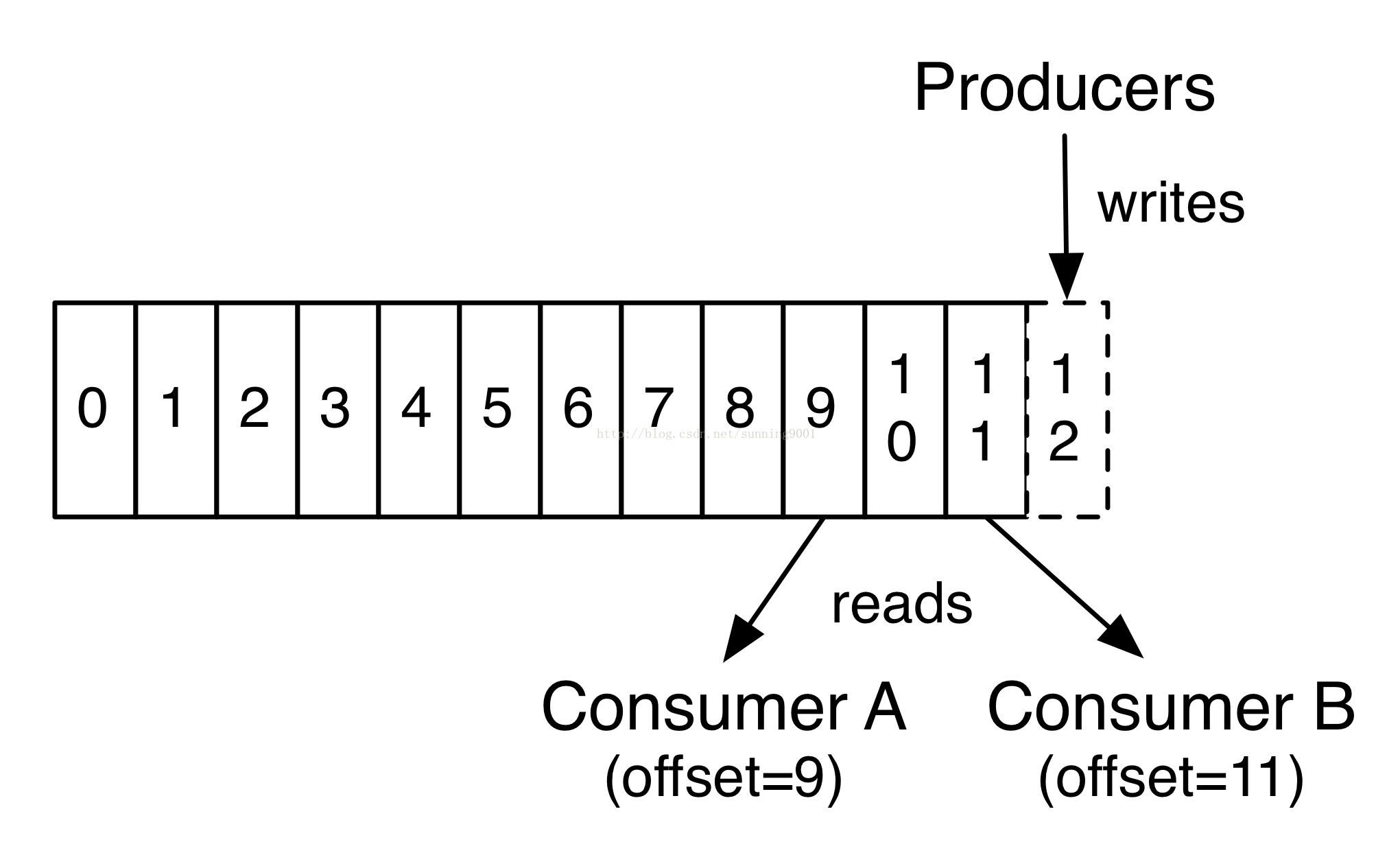
每一个partition 是一个有序的、拥有不变序列的记录,而且可以不断增加结构化的commit log.在partition中的record都被附有一个序列ID,被称作offset. offset在可以partion中区别不同的record
Kafka集群保留所有的发布的消息、这些消息根据配置文件来保留一段时间。无论这个record是否已经被消费了。如果这个保留策略被设置成2天,如果一个消息被发送到Kafka集群中,那边这个消息就被等待消息。如果,2天过去了,无论这个消息是否被消费,这个消息都会被丢弃,然后释放磁盘空间。Kafka有存够的能力存储数据,所以不用担心数据存储问题。
实际上,每一个consumber 仅仅保存metadat中offset或者position数据,offset是指消费的记录位置。
这个offset 被consumber 控制,一般情况下,当consumber读取都records时,consumber会线性增加offset.但是,实际上,consumber可以根据自己的喜欢来消费record,来任意控制offset的位置。
例如:consumber 可以重置offset位置到一个旧位置这样可以消费已经消费过的record,或者从now开始消费,这样就可以跳过最近已经消费过的记录。
log的分区可以有多个目的。第一个目的,可以灵活的调整消息在单个server上面的数量。每一topic可以有多个分区,这样就可以处理大量的数据。
第二个目的,分区可以作为并行处理的单元。
Producer
Producer 根据他们的选择发送record到topic.producer 负责选择topic下面的哪一个分区,以被发送数据。这样,可以选择一个随机算法来简单的实现负载均衡。
Consumber
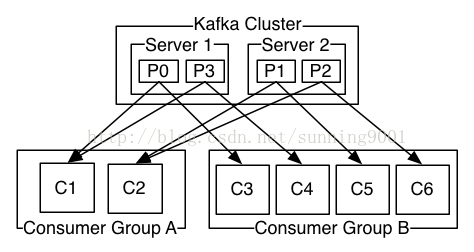
consumber 根据一个consumber group 名称把他们自己区分为不同的组。一个被发送到topic的消息会分发到每一个订阅这个topic的consumber group ,但是只会分发到consumber group 中的一个实例。comsumber的实例可以在不同的进程中或者在不同的机器上面。
如果,所有的consumber 实例拥有同一个consumber group ,那么消息会被有效的负载到所有的consumber实例上面。
如果,所有的consumber 实例拥有完全不同的consumber group中,那么,消息会被广播到所有的consumber 实例上面。
在一个分区中Kafka提供一个有序的record,同一个topic下的不同paatition不确保顺序。对于应用程序来说,确保顺序非常重要。
如果需求一个全局性的消息顺序,那么可以设置一个topic只有一个分区,这样就意味着每一个consumber group 只有一个consumber实例
Kafka as Messaging System Kafka 作为消息系统
Kafka 多个概念和传统的消息系统对比?
传统的消息概念有2个模型:Queue和publis-subscribe .在queue模型中,多个消费者订阅主题,但是只有一个消费者可以获取到消息。
在publish-subscribe 模型中,消息被广播到所有的消费者中。这两个模型中都有一个缺点和一个优点。
queue的优点是允许在多个消费者实例中分割出来数据的处理。不幸运的是,队列中的数据一旦被消费了,消息就消失了。
在publish-subscribe模型中,允许你广播消息到多个消费者中,但是因为每一个消息被发送到每一个订阅者中,这样就没办法灵活分离消息的处理啦。
在Kafka中的consumber group 衍生出两个概念:
作为queue模型,consumber group允许把消费分发到consumber group 中的一个实例中。作为publish-subscribe 模型,Kafka允许你把消息分发到多个consumber group中。
Kafka模型的优点是每一个topic都有queue 和publish-subscribe 属性。可以灵活的划分消息的处理,同时,他有多个订阅者。
Kafka有更严格的消息顺序确保来比其他传统的消息系统。
传统的消息系统,在服务器上面保留有序的记录队列。并且,多个消费者从有序队列中消费这些数据。服务器安装保存的顺序来输出这些记录。
但是,虽然这些服务器按照顺序的输出消息,但是消息异步分发到消息者那里,所以,当消费者接受到的消息可能是乱序的。尤其,在并行消费过程中,这些有顺序的记录将会丢失顺序。
传统消息系统经常使用一个 exclusive consumber 的概念,这样允许只有一个进行来不断消费这个队列,这样就导致在处理的过程中并发就没有了。
Kafka在这个方便处理的就比较好。通过在同一个topic下面有partition,这样来实现并行。kafka可以同时提供有序的消息顺序和负载均衡在多个消费者池中。
通过把topic分成不同的partition 分配到consumber group中的consumber,这样每一个partion有且只有一个consumber 可以消费这个partition,并且消费这个queue是按照顺序的。
因为,同一个topic中用于多个partion中,这样,依然可以在多个comsumber 实例上面做到负载均衡。















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









