







聚类分析(cluster analysis)是把研究对象(样本或变量)分组成为由类似的对象组成多个类的一种统计方法。聚类结果一般在4-6类,不易太多,或太少。聚类分析目的在于将相似的事物归类,同一类中的个体有较大的相似性,不同类的个体差异性很大。两个个体间(或变量间)的对应程度或联系紧密程度的度量可以用两种方式来测量:1、采用描述个体对(变量对)之间的接近程度的指标,例如“距离”,“距离”越小的个体(变量)越具有相似性;2、采用表示相似程度的指标,例如“相关系数”,“相关系数”越大的个体(变量)越具有相似性。
聚类分析方法包括:系统聚类法、动态聚类法、有序样本聚类法和模糊聚类法等等。本文只介绍较常用的系统聚类法和动态聚类法。
1 系统聚类法
以R基础包自带的鸢尾花(Iris)数据进行聚类分析。分析代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
###### 代码清单 #######
data
(iris); attach
(iris)
iris
.
hc <-
hclust
(
dist
(iris
[
,1:4]))
# plot
( iris
.
hc,
hang = -1)
plclust
( iris
.
hc, labels = FALSE, hang = -1)
re <-
rect
.
hclust
(iris
.
hc, k = 3)
iris
.id <-
cutree
(iris
.
hc, 3)
table
(iris
.id, Species)
###### 运行结果 #######
>
table
(iris
.id
,Species)
Species
iris.id setosa versicolor virginica
1 50 0 0
2 0 23 49
3 0 27 1
|
聚类分析生成的图形如下:
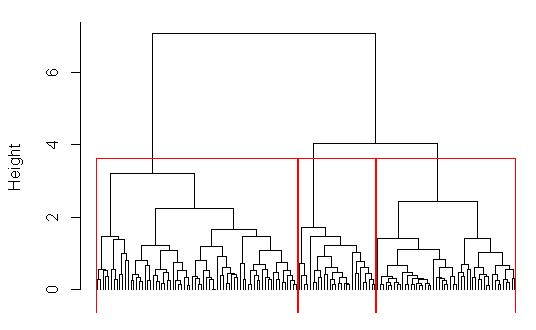
鸢尾花花萼及花瓣的长度和宽度系统聚类图
结果表明,函数cuttree()将数据iris分类结果iris.hc编为三组分别以1,2, 3表示,保存在iris.id中。将iris.id与iris中Species作比较发现:1应该是setosa类,2应该是virginica类(因为virginica的个数明显多于versicolor),3是versicolor。
2 动态聚类法
仍以R基础包自带的鸢尾花(Iris)数据进行K-均值聚类分析,分析代码如下:
|
1
2
3
4
5
6
7
8
9
|
###### 代码清单 #######
library
(
fpc)
data
(iris)
df<-iris
[
,c
(1:4)]
set.seed(252964) # 设置随机值,为了得到一致结果。
(kmeans <- kmeans(na.omit(df), 3)) # 显示K-均值聚类结果
plotcluster
(
na
.omit
(
df), kmeans$cluster) # 生成聚类图
|
生成的图如下:
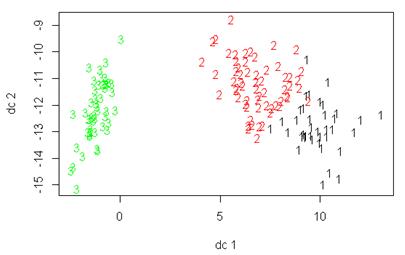
动态聚类结果
转载自:http://blog.sciencenet.cn/blog-1114360-735780.html















 2618
2618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









