






Mybatis作为大家熟知的持久层框架,能够通过XML或注解方便地实现ORM和数据库操作,到底它是怎么实现的呢,这里通过源码带大家揭开它的神秘面纱。
首先创建srping boot的demo项目,添加mybatis依赖、数据库配置等,以下贴上部分代码
// 初始化mybatis的SqlSessionFactory,dataSource为数据库配置
@Configuration
public class MyBatisConfig {
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) {
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("dev", transactionFactory, dataSource);
org.apache.ibatis.session.Configuration configuration = new org.apache.ibatis.session.Configuration(environment);
configuration.addMapper(StudentMapper.class);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
return sqlSessionFactory;
}
}
// 通过注解定义mapper
public interface StudentMapper {
@Select({
"select * from student where id = #{id,jdbcType=INTEGER}"
})
@Results({
@Result(column = "id", property = "id", jdbcType = JdbcType.BIGINT, id = true),
@Result(column = "order_no", property = "orderNo", jdbcType = JdbcType.VARCHAR)
})
Student getById(@Param("id")Integer id);
}
@RestController
@SpringBootApplication
public class MybatisTestApplication {
@Autowired
private SqlSessionFactory sqlSessionFactory;
// main方法省略
// 查询数据库
@GetMapping("/test")
public String test() {
SqlSession sqlSession = sqlSessionFactory.openSession();
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
Student student = studentMapper.getById(1);
return student.getName();
}
}从demo可以看出Mybatis的操作顺序:
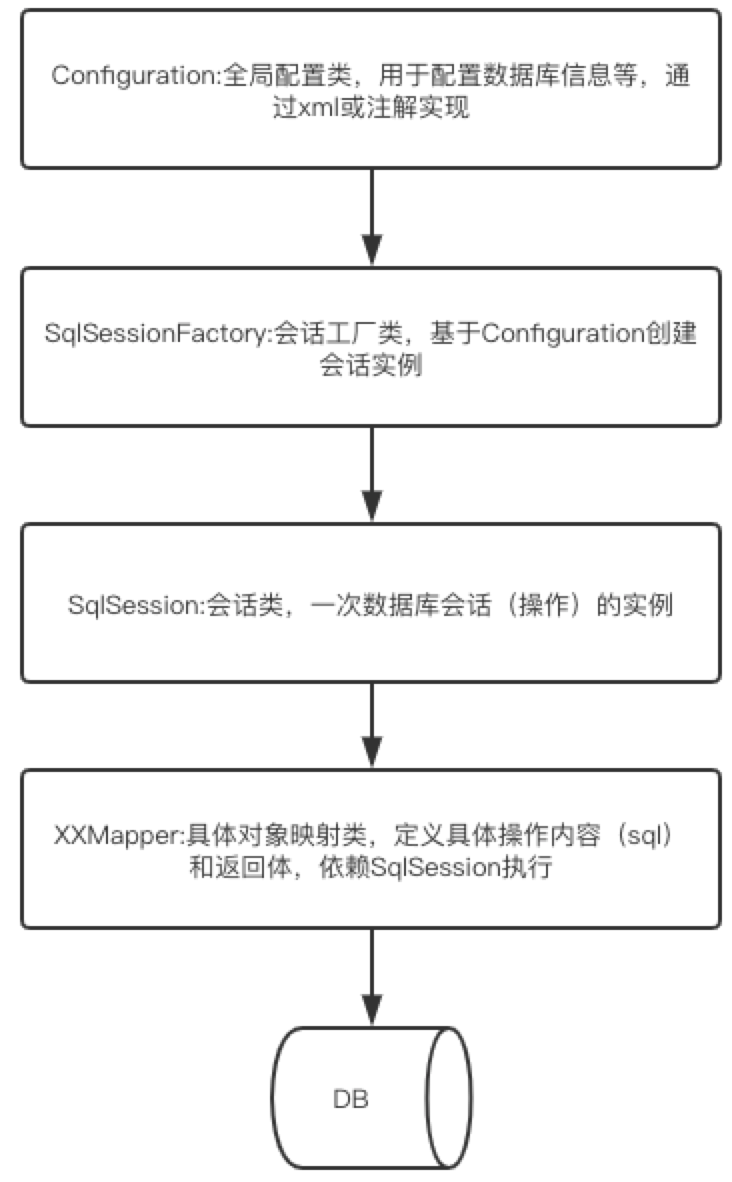
继续debug源码,看看mybatis主要通过哪些核心类进行操作,从StudentMapper.getById方法进入后,到达org.apache.ibatis.binding.MapperProxy#invoke方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// …… 省略不相关的类操作
// 创建mapper方法的缓存对象
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 执行操作
return mapperMethod.execute(sqlSession, args);
}进入cachedMapperMethod,发现MapperMethod的构造函数是实例化SqlCommand和MethodSignature,而SqlCommand的属性是通过MappedStatement获取,MethodSignature则是通过 Configuration、Mapper类和方法 计算返回相关信息,因此我们重点关注下MappedStatement
public final class MappedStatement {
// 部分属性
private Configuration configuration;
private String id;
private StatementType statementType;
private ResultSetType resultSetType;
private SqlSource sqlSource;
private Cache cache;
private ParameterMap parameterMap;
private List<ResultMap> resultMaps;
private SqlCommandType sqlCommandType;
private String[] resultSets;
// ……
}从MappedStatement的属性大致可以猜到它是记录sql、输入参数、输出结果类型等信息,有了这些信息后再回到mapperMethod.execute就可以真正发起数据库操作了。
以SELECT为例,首先包装参数,统一调用 SqlSession.selectList方法:
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);可以看出还是需要MappedStatement,而具体执行则通过Executor来操作。
进入Executor方法,首先BoundSql boundSql = ms.getBoundSql(parameterObject);,从其属性可以看出包含sql和输入参数
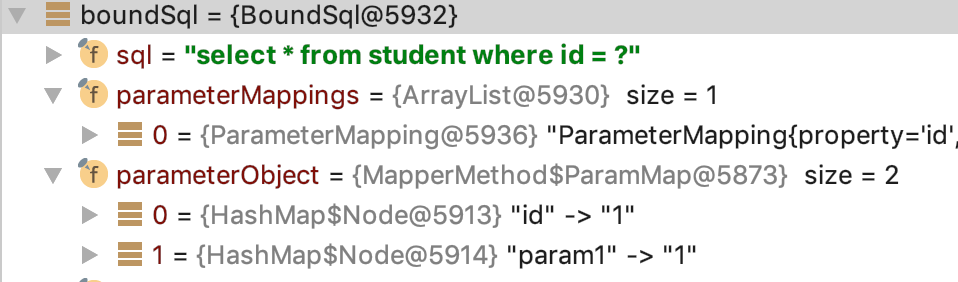
最终跳到org.apache.ibatis.executor.SimpleExecutor#doQuery方法
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 到这里就是我们熟悉的jdbc对象了
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
// handler最终到达的方法
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 是不是十分熟悉了
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
// 返回结果处理器
return resultSetHandler.handleResultSets(ps);
}至此,mybatis一次数据库操作完成,结合以上代码重新将开头的时序图补充完整:
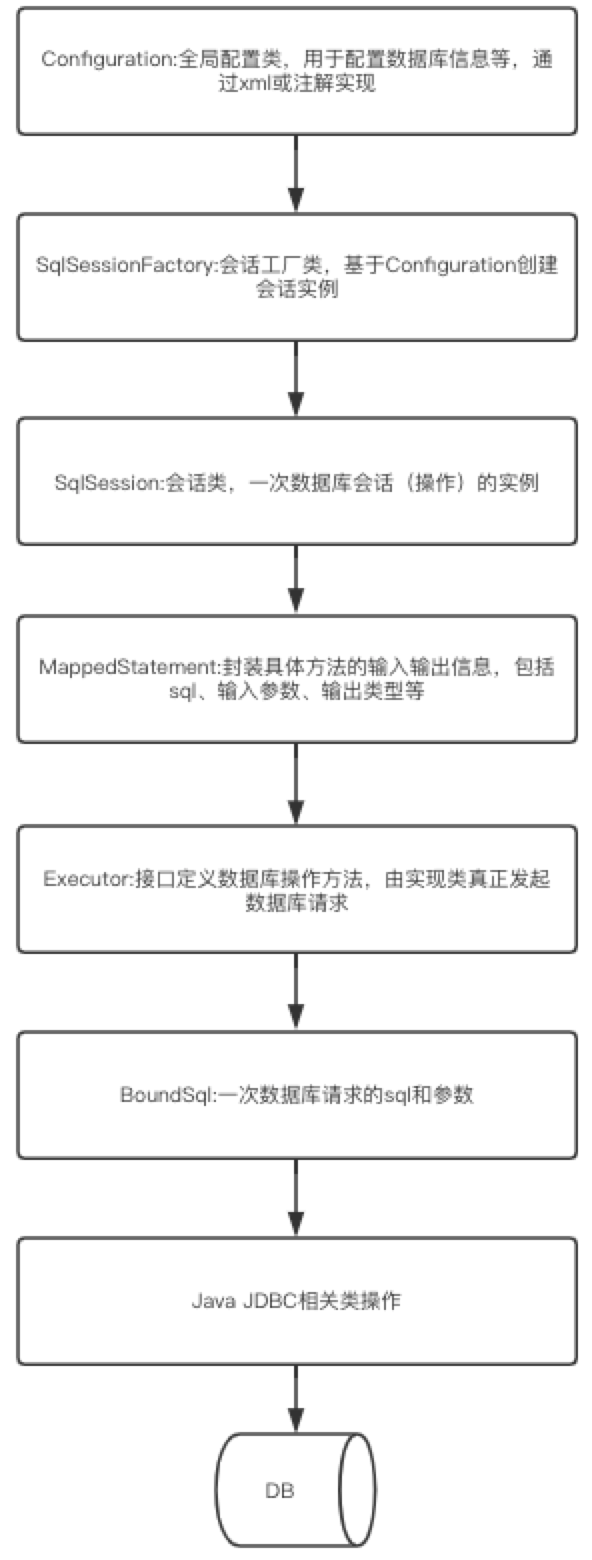
因此,mybatis的原理还是通过JDBC实现的。这时候大家是不是依然存在不少疑问,具体sql到底什么时候生成,mapper接口又是如何实例化,不用急,下一篇将继续带大家一起解开这些疑问
彩蛋:创建会话所使用的设计模式——工厂模式
从SqlSessionFactory的命名我们都能看出用的是工厂模式,那到底为什么要使用工厂模式呢?
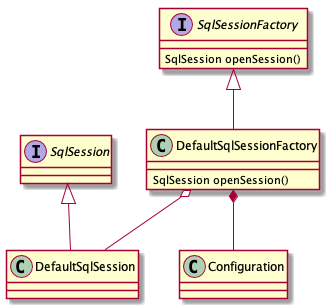
首先,每次数据库操作必须是线程独立的,自然需要每次操作时实例化一次;但是数据库的配置、操作方法和定义的sql等都是相同的,只是参数不相同,因此在实例化会话时将配置加载进来即可,即需要定制其实例化过程。
通过工厂模式可以定制SqlSession实例化过程,另外不同的工厂生产特定的SqlSession实现类,从而 明确区分了各自的职责和权力,有利于整个软件体系结构的优化。















 18
18











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









