







一、学习大数据需要学什么
拉钩学习
Java、Python、Scala
Linux、
Hadoop、Storm、Spark、Flink、HBase、Hive、Impala、ElasticSearch、Kafka、Flume、Scribe、mahout、ElasticSearch、mysql、mongodb、redis、Zookeeper、sqoop
学习大数据需要的基础
Java SE:
大数据技术框架中90%都是用Java语言写的。
MySQL:
SQL
Linux:
大数据技术框架都是部署在Linux系统上
需要学习什么
1. 第一方面:大数据离线分析
Hadoop 2.x(Common、HDFS、MapReduce、Yarn):存储、分析
环境搭建
处理数据思想
Hive(数据库仓库):分析
通过SQL语句对数据进行操作,SQL和MySQL的SQL基本一样
协作框架:
Sqoop:桥梁(HDFS <–> RDBMS )
Flume:通过flume采集数据
调度框架azkaban:
Crontab(Linux自带)
Zookeeper:
分布式应用程序协调服务
HBASE数据库:
NOSQL数据库
redis
扩展前沿框架
Impala
游戏公司用的多,耗内存
用来做数据分析
ElasticSearch(ES)
检索的框架
相当于数据库,即可存储数据库,也可以检索数据
2 . 第二方面:大数据实时分析
Scala:OOP+FP
Spark Core、SQL、Streaming
Kafka:消息队列
前沿框架:Flink
**
3.第三方面:机器学习
**
Spark MLib
二、环境搭建
配置虚拟机
确保虚拟机的网段59,修改vMnet8适配器网段地址192.168.59.0
虚拟机配置约束规定
普通用户:huadian/huadian
主机名:bigdata.huadian.com
基本操作
创建用户名
useradd huadian
passwd huadian
修改主机名
vi /etc/sysconfig/network
配置Ip、DNS
 配置完成之后,使用Linux的命令终端可以查看:ifconfig
配置完成之后,使用Linux的命令终端可以查看:ifconfig
主机名映射
Linux:
vi /etc/hosts
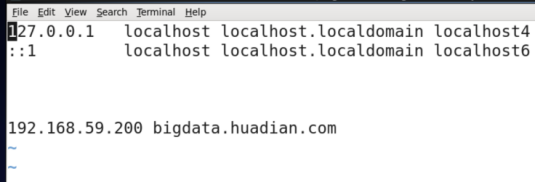
配置完成之后,在Linux中:ping bigdata.huadian.com
window:
C:\Windows\System32\drivers\etc\hosts
成功的标准:
(1)在Linux里面:ping bigdata.huadian.com 可以看到192.168.59.200
(2)在window里面:ping bigdata.huadian.com 可以看到192.168.59.200

使用远程连接
使用root用户
配置普通用户huadian具有sudo权限
visudo

测试:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









