







单向链表的缺点
单向链表相对数组来说已经有很多优点了,但是,它还有一个最大的弊端,那就是我们可以轻松的到达下一个节点, 但是回到前一个节点是很难的. 但是, 在实际开发中, 经常会遇到需要回到上一个节点的情况,这种特性在进行数据操作时,会大大浪费时间,鉴于此,出现了双向链表的概念。
双向链表就是具备两个方向的指向,无非就是每个结点成了两个指针。
每个数据节点有一个数据域两个个指针域 不光从前向后检索 还能从后向前
每次在插入或删除某个节点时, 需要处理四个节点的引用, 而不是两个. 也就是实现起来要困难一些,并且相当于单向链表, 必然占用内存空间更大一些.
1.创建双链表
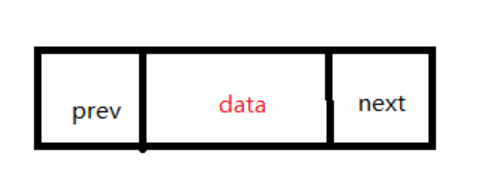
有两个指针域分别指向前一个结点和后一个结点,还有一部分用来保存结点数据,初始化结点时需要将两个指针都指向空
eg:
Node* node = (Node*)malloc(sizeof(Node));
node->prev = NULL;
node->next = NULL;
2.增加结点
增加结点时,需要将最后一个结点的next指针指向新结点,然后将新结点的prev指向最后一个结点

3.删除结点
删除结点时需要将待删除结点的前一个结点的next指向待删除结点的后一个结点,然后,把后者的prev指针指向前者:

4.插入结点
插入结点就是将新结点的前一个结点的next指针指向指向新结点,然后把新结点的next指针指向前一个结点原来后面的那个结点,然后把后面的结点的prev指针指向新结点,把新结点的Prev指针指向前一个结点。

头文件:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int LTDataType;
#define N 10
typedef struct ListNode
{
struct ListNode* _next;
struct ListNode* _prev;
LTDataType _data;
}ListNode;
typedef struct List
{
struct ListNode* _head;
struct ListNode* _tail;
int count;
}List;
void ListInit(List* lt);//初始化
void ListDestory(List* lt);//销毁
void ListPushBack(List* lt, LTDataType x);//在最后插入
void ListPushFront(List* lt, LTDataType x);//在前面插入
void ListPopBack(List* lt);//从最后出一个
void ListPopFront(List* lt);//从最前面出一个
ListNode* ListFind(List* lt, LTDataType x); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9037
9037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









