







上回说到,如何确定最大匹配数。接下来,本次将简述如何确定最优匹配路径。仿照确定最大匹配数的算法,这个问题也非常容易解决,不知道这周当中,有没有哪位 XDJM 已经有了自己的解决方案呢?
有问题可以发邮件给我: Calriones@hotmail.com
文本比较算法剖析( 2 ) - 如何确定最优匹配路径
确定最优匹配路径的问题,通常在做文件比较时要用到,它的意思是:在所有能够得到最大匹配点数的路径中,找出一条最短的路径。
让我们继续以上次的例子进行研究:
首先,我们仍然是手工标出能够得到最大匹配点数的所有路径。在手工绘制可用路径的时候,需要说明一下:
l 首先,这里我们以计算 left 的最优路径为例。计算 right 的最优路径和 left 是完全对称的;
l 在图中,向右移动一格,表示 left 的当前元素放弃和 right 的当前元素进行匹配,而和 right 的下一个元素进行匹配。如果进行文件比较的话,就是 left 文件的当前行前,插入 right 文件的当前行;
l 在图中,向下移动一格,表示 left 的当前元素放弃和 right 的当前元素进行匹配,而使用 left 的下一个元素和 right 的当前元素进行匹配。如果进行文件比较的话,就是 left 文件的当前行被删除;
l 在途中,向右下方移动一格,表示确定 left 和 right 的当前元素的匹配,使用 left 的下一个元素和 right 的下一个元素进行匹配。如果进行文件比较的话,就是 left 和 right 文件的当前行已经匹配,分别比较下一行。
l 由于 left 和 right 是流式的,所以每个元素只能匹配一次而且不能颠倒顺序,所以,在 x 和 y 方向上,只能保留一个匹配点,而且只能向下,向右,或者向右下方移动。
有了这些规则,我们就可以得到如下图中间红色粗线所示的 4 条可能的路径。
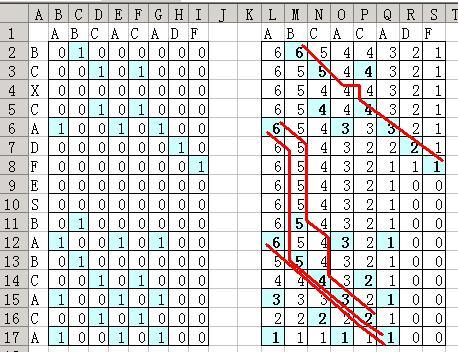
从上向下,依次编号为 1,2,3,4 号路径,分析如下:
1 号路径表示(只说明含义,算法推导在后面):

依次类推,可以得到其他路径的实际含义。需要说明的是, 3 号路径在选择第二个匹配点时,没有采用 left[9]:right[1] 的匹配关系,而是跳过 left[9] ,采用了 left[11]:right[1] 。这样,点 (left[9], right[1]) 在 3 号路径上是“删除 left 第 9 行”的意思。
如果我将整个过程中在 left 上移动的距离纪录下来,就得到:
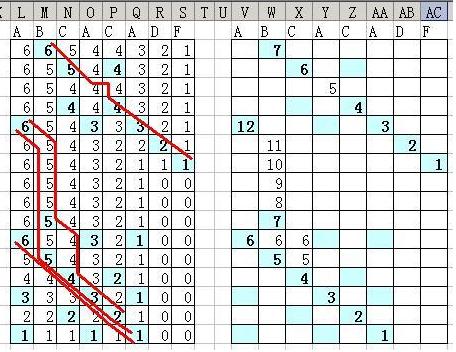
从图上就很容易看出,在 left 上移动最短的,也就是最优的路径,是 4 号路径。
是不是看起来毫无头绪?
别急,象上次一样,我们进行一个分析。
依然是归纳法,依然是找出元素 D(l,r) 的 3 个相邻区域 A,B,C:
分析:
1. 如果点 D(l,r) 表示从 left 的第 L 个元素, right 的第 R 个元素出发,匹配到矩阵边界后,在 left 方向上的最短路径长度 (我更喜欢称之为 depth ) ,那么:
2. 如果点 (l,r) 是一个被确定的匹配点,那么下一步,只能选择进入 A 区域,到点 (l+1,r+1) ,所以得到:
D1 If (V(l,r)>0) then D(l,r) = 1 + D(l+1,r+1)
还记得 V(l,r) 和 N(l,r) 的定义么?可以看看文档《文本比较算法剖析( 1 ) - 如何确定最大匹配率 》
3. 如果点 (l,r) 不是一个被确定的匹配点,那么下一步可以进入 B 或者 C.
D2 如果进入 B 区域,那么意味着 ” 插入 right 的第 r 行 ” ,但是在 left 的位置保持不变,所以得到:
If (V(l,r) == 0) then D(l,r) = D(l,r+1)
D3 如果进入 C 区域,那么意味着 ” 删除 left 的第 l 行 ” ,在 right 的位置保持不变,但是在 left 的位置要加 1 。所以得到 :
If (V(l,r) == 0) then D(l,r) = 1 + D(l+1,r)
那么现在有 3 个值 D1 , D2 , D3 ,该如何取舍呢?直接取 Min(D1,D2,D3) 可以么?
呵呵,其实,我也是尝试了很多次以后才搞清楚的。大家可以用 excel 验证一下自己的想法。很简单的,大概验证整个算法,用 10 行左右的代码再加上 excel 本身提供的公式就足够了。
4. 不要忘记了前面说过的, ” 在所有能够得到最大匹配点数的路径中,找出一条最短的路径 ”, 首先我们要保证得到最大匹配匹配点数,所以我们又有:
If (N(l,r+1) >= N (l+1,r) then
D(l,r) = D(l,r+1);
Else
D(l+r) = 1 + D(l+1,r)
综合上面所有的分析,路径长度 D(l,r) 的计算公式就是:
If (V(l,r) = 1) Then
D(l,r) = D(l+1,r+1) + 1
Else
If (N(l,r+1) >= N(l+1,r)) Then
D(l,r) = D(l,r+1)
Else
D(l,r) = D(l+1,r) + 1
End If
将公式写入 excel 自动计算,得到结果如图:
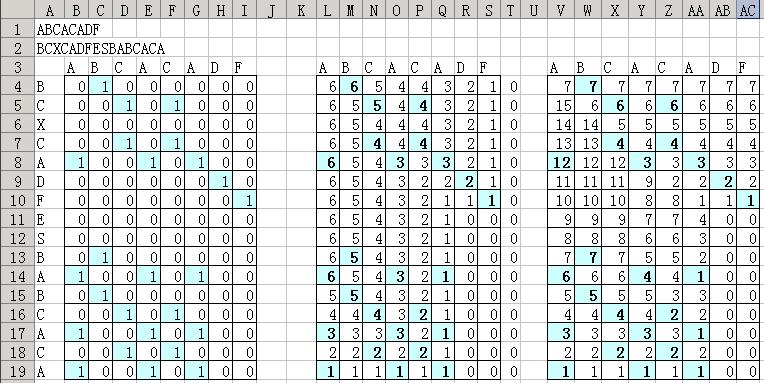
可以看到,结果正确。
OK 。 结束了,文本比较的算法核心就介绍完了。
事实上,上面第四步给出的是优化后的结果,有兴趣的可以自己试着分析一下第 4 步是否应该这样计算,有什么情况我没有在这里讲的,但是结果为什么又是正确的。
有了这个算法,大家可以很快的编写自己的文本比较功能了。
计算最优路径的附加时间复杂度为 0 ,因为它完全可以和计算最大匹配点数一起进行;附加的空间复杂度为 Max(m,n), 因为它需要一个额外的数组纪录 N(l+1) 。
如果不计算最优路径的话,计算最大匹配点数的算法还可以再优化。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









