







01、关键字与保留字
1、关键字(keyword)的定义和特点
- 定义:被 Java 语言赋予了特殊含义,用做专门用途的字符串(单词)
- 特点:关键字中所有字母都为小写
- 官方地址: https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html 可以参考
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9fg5z5nT-1654818555378)(./upload/BlogPicBed-1-master/img/2021/01/27/20210127183915)]](https://img-blog.csdnimg.cn/b676ccd4e9354683b8535fe58118ba8a.png)
2、保留字(reserved word)
Java 保留字:现有 Java 版本尚未使用,但以后版本可能会作为关键字使用。自己命名标识符时要避免使用这些保留字 goto、const。
02、标识符
2.1、什么是标识符(Identifier)
- Java 对各种变量、方法和类等要素命名时使用的字符序列称为标识符
- 技巧:凡是自己可以起名字的地方都叫标识符。
2.2、定义合法标识符规则【重要】
- 由 26 个英文字母大小写,0-9,_或$ 组成
- 数字不可以开头。
- 标识符不能包含空格。
- 不可以使用关键字和保留字,但能包含关键字和保留字。
- Java 中严格区分大小写,长度无限制。
2.3、Java 中的名称命名规范
1、Java 中的名称命名规范:
- 包名:多单词组成时所有字母都小写:xxxyyyzzz
- 类名、接口名:多单词组成时,**所有单词的首字母大写:**XxxYyyZzz
- 变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写:xxxYyyZzz
- 常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
2、注意点
- 注意 1:在起名字时,为了提高阅读性,要尽量有意义,“见名知意”。
- 注意 2:java 采用 unicode 字符集,因此标识符也可以使用汉字声明,但是不建议使用。
- 更多细节详见《代码整洁之道》
03、变量
3.1、变量的声明与使用
1、变量的概念:
- 内存中的一个存储区域;
- 该区域的数据可以在同一类型范围内不断变化;
- 变量是程序中最基本的存储单元。包含变量类型、变量名和存储的值。
2、变量的作用:
- 用于在内存中保存数据。
3、使用变量注意:
- Java 中每个变量必须先声明,后使用;
- 使用变量名来访问这块区域的数据;
- 变量的作用域:其定义所在的一对{ }内;
- 变量只有在其作用域内才有效;
- 同一个作用域内,不能定义重名的变量;
4、声明变量
- 语法:<数据类型> <变量名称>
- 例如:int var;
5、变量的赋值
- 语法:<变量名称> = <值>
- 例如:var = 10;
6、声明和赋值变量
- 语法:<数据类型><变量名>= <初始化值>
- 例如:int var = 10
7、补充:变量的分类-按声明的位置的不同
- 在方法体外,类体内声明的变量称为成员变量。
- 在方法体内部声明的变量称为局部变量。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IIUBgIaN-1654818555379)(./upload/BlogPicBed-1-master/img/2021/01/27/20210127183901)]](https://img-blog.csdnimg.cn/81bd019d42944a8eb47cea09714ddf94.png)
8、注意:二者在初始化值方面的异同:
- 同:都有生命周期
- 异:局部变量除形参外,需显式初始化。
3.2、基本数据类型
2、变量的分类-按数据类型
对于每一种数据都定义了明确的具体数据类型(强类型语言),在内存中分配了不同大小的内存空间。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ayPxfma9-1654818555379)(./upload/BlogPicBed-1-master/img/2021/01/27/20210127183856)]](https://img-blog.csdnimg.cn/500390fbd164427d9761e557cbe38b68.png)
3.2.1、整数类型:byte、short、int、long
- Java 各整数类型有固定的表数范围和字段长度,不受具体 OS 的影响,以保证 java 程序的可移植性。
- java 的整型常量默认为 int 型,声明 long 型常量须后加‘l’或‘L’
- java 程序中变量通常声明为 int 型,除非不足以表示较大的数,才使用 long
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| byte | 1字节=8bit位 | -128 ~ 127 |
| short | 2字节 | -2^15~ 2^15-1 |
| int | 4字节 | -2^31~ 2^31-1 (约21亿) |
| long | 8字节 | -2^63~ 2^63-1 |
- 1MB = 1024KB 1KB= 1024B B= byte ? bit?
- bit: 计算机中的最小存储单位。byte:计算机中基本存储单元。
/*
Java定义的数据类型
一、变量按照数据类型来分:
基本数据类型:
整型:byte \ short \ int \ long
浮点型:float \ double
字符型:char
布尔型:boolean
引用数据类型:
类:class
接口:interface
数组:array
二、变量在类中声明的位置:
成员变量 vs 局部变量
*/
class VariableTest1{
public static void main(String[] args) {
//1. 整型:byte(1字节=8bit) short(2字节) \ int (4字节)\ long(8字节)
//① byte范围:-128 ~ 127
byte b1 = 12;
byte b2 = -128;
// b2 = 128; //编译不通过
System.out.println(b1);
System.out.println(b2);
// ② 声明long型变量,必须以“1”或“L”结尾
short s1 = 128;
int i1 = 12345;
long l1 = 345678586;
System.out.println(l1);
}
}
3.2.2、浮点类型:float、double
- 与整数类型类似,Java 浮点类型也有固定的表数范围和字段长度,不受具体操作系统的影响。
- 浮点型常量有两种表示形式:
- 十进制数形式:如:5.12 512.0f .512 (必须有小数点)
- 科学计数法形式:如:5.12e2 512E2 100E-2
- float:单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。
- double:双精度,精度是float的两倍。通常采用此类型。
- Java 的浮点型常量默认为double型,声明float型常量,须后加‘f’或‘F’。
| 类型 | 占用存储空间 | 表数范围 |
|---|---|---|
| 单精度float | 4字节 | -3.403E38 ~ 3.403E38 |
| 双精度double | 8字节 | -1.798E308 ~ 1.798E308 |
3.2.3、字符类型:char
- char 型数据用来表示通常意义上“字符”(2字节)
- Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符。
- 字符型变量的三种表现形式:
- 字符常量是用单引号(‘ ’)括起来的单个字符。例如:char c1 = ‘a’; char c2 = ‘中’; char c3 = ‘9’;
- Java中还允许使用转义字符‘\’来将其后的字符转变为特殊字符型常量。例如:char c3 = ‘\n’; //’\n’表示换行符
- 直接使用Unicode值来表示字符型常量:‘\uXXXX’。其中,XXXX代表一个十六进制整数。如:\u000a 表示\n。
- char类型是可以进行运算的。因为它都对应有Unicode码。
/*
Java定义的数据类型
一、变量按照数据类型来分:
基本数据类型:
整型:byte \ short \ int \ long
浮点型:float \ double
字符型:char
布尔型:boolean
引用数据类型:
类:class
接口:interface
数组:array
二、变量在类中声明的位置:
成员变量 vs 局部变量
*/
class VariableTest1{
public static void main(String[] args) {
//2. 浮点型:float(4字节) \ double(8字节)
//① 浮点型,表示带小数点的数值
//② float表示数值的范围比long还大
double d1 = 12.3;
System.out.println(d1 +1);
//定义float类型变量时,变量要以"f" 或"F"结尾
float f1 = 12.3F;
System.out.println(f1);
//② 通常,定义浮点型变量时,使用double变量
//3. 字符型:char(1字符=2字节)
//① 定义char型变量,通常使用一对''
char c1 = 'a';
//编译不通过
//c1 = 'AB';
System.out.println(c1);
char c2 = '1';
char c3 = '中';
char c4 = '&';
System.out.println(c2);
System.out.println(c3);
System.out.println(c4);
//② 表示方式:1.声明一个字符;2.转义字符;3.直接使用Unicode值来表示字符型常量
char c5 = '\n'; //换行符
c5 = '\t'; //制表符
System.out.print("hello" + c5);
System.out.println("world");
char c6 = '\u0123';
System.out.println(c6);
char c7 = '\u0043';
System.out.println(c7);
}
}
了解:ASCII 码
- 在计算机内部,所有数据都使用二进制表示。每一个二进制位(bit)有0 和1 两种状态,因此8个二进制位就可以组合出256 种状态,这被称为一个字节(byte)。一个字节一共可以用来表示256 种不同的状态,每一个状态对应一个符号,就是256 个符号,从0000000 到11111111。
- ASCII码:上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码。ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
- 缺点:
- 不能表示所有字符。
- 相同的编码表示的字符不一样:比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel(ג)。
了解:Unicode 编码
- 乱码:世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
- Unicode:一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,使用Unicode 没有乱码的问题。
- Unicode 的缺点:Unicode 只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储:无法区别Unicode 和ASCII:计算机无法区分三个字节表示一个符号还是分别表示三个符号。另外,我们知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费。
了解:UTF-8
- UTF-8 是在互联网上使用最广的一种Unicode 的实现方式。
- UTF-8 是一种变长的编码方式。它可以使用1-6 个字节表示一个符号,根据不同的符号而变化字节长度。
- UTF-8的编码规则:
- 对于单字节的UTF-8编码,该字节的最高位为0,其余7位用来对字符进行编码(等同于ASCII码)。
- 对于多字节的UTF-8编码,如果编码包含n 个字节,那么第一个字节的前n位为1,第一个字节的第n+1 位为0,该字节的剩余各位用来对字符进行编码。在第一个字节之后的所有的字节,都是最高两位为"10",其余6位用来对字符进行编码。
3.3.4、布尔类型:boolean
- boolean 类型用来判断逻辑条件,一般用于程序流程控制:
- if条件控制语句;
- while循环控制语句;
- do-while循环控制语句;
- for循环控制语句;
- boolean类型数据只允许取值true和false,无null。
- 不可以使用0或非0 的整数替代false和true,这点和C语言不同。
- Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false用0表示。———《java虚拟机规范8版》
class VariableTest1{
public static void main(String[] args) {
//4. 布尔型:boolean
//① 只能取两个值之一:true 、false
//② 常常在条件判断、循环结构中使用
boolean bb1 = true;
System.out.println(bb1);
boolean isMarried = true;
if(isMarried){
System.out.println("禁止入内!");
}else{
System.out.println("可以参观!");
}
}
}
3.3、基本数据类型转换
-
自动类型转换:容量小的类型自动转换为容量大的数据类型。数据类型按容量大小排序为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VJ30Aqj7-1654818555380)(./upload/BlogPicBed-1-master/img/2021/01/27/20210127183839)]](https://img-blog.csdnimg.cn/3e7407607ef04efe88e080dcb7327a92.png)
-
有多种类型的数据混合运算时,系统首先自动将所有数据转换成容量最大的那种数据类型,然后再进行计算。
-
byte,short,char之间不会相互转换,他们三者在计算时首先转换为int类型。
-
boolean类型不能与其它数据类型运算。
-
当把任何基本数据类型的值和字符串(String)进行连接运算时(+),基本数据类型的值将自动转化为字符串(String)类型。
/*
基本数据类型之间的运算规则:
前提:这里讨论只是7中基本数据类型变量的运算。不包含boolean类型的。
1. 自动类型提升:
当容量小的数据类型的变量和容量大的数据类型的变量做运算时,结果自动提升为容量大的数据类型。
char、byte、short-->int-->long-->float-->double
特别的:当byte、char、short三种类型的变量做运算时,结果为int类型
2. 强制类型转换:
说明:此时容量大小指的是,表示数的范围的大和小。比如:float容量要大于long的容量
*/
class VariableTest2{
public static void main(String[] args) {
byte b1 = 2;
int i1 = 129;
//编译不通过
// byte b2 = b1 + i1;
int i2 = b1 + i1;
long l1 = b1 + i1;
System.out.println(i2);
System.out.println(l1);
float f = b1 + i1;
System.out.println(f);
//***************特别的**************************
char c1 = 'a'; //97
int i3 = 10;
int i4 = c1 + i3;
System.out.println(i4);
short s2 = 10;
//编译错误
// char c3 = c1 + s2;
byte b2 = 10;
// char c3 = c1 + b2; //编译不通过
// short s3 = b2 + s2; //编译不通过
// short s4 = b1 + b2; //编译不通过
}
}
class VariableTest4{
public static void main(String[] args){
//1. 编码情况
long l = 123456;
System.out.println(l);
//编译失败:过大的整数
//long l1 = 452367894586235;
long l1 = 452367894586235L;
//**************************
//编译失败
// float f1 = 12.3;
//2. 编码情况2:
//整型变量,默认类型为int型
//浮点型变量,默认类型为double型
byte b = 12;
// byte b1 = b + 1; //编译失败
// float f1 = b + 12.3; //编译失败
}
}
3.3、字符串类型:String
- String不是基本数据类型,属于引用数据类型
- 使用方式与基本数据类型一致。例如:String str= “abcd”;
- 一个字符串可以串接另一个字符串,也可以直接串接其他类型的数据。例如:
/*
String类型变量的使用
1. String属于引用数据类型
2. 声明String类型变量时,使用一对""
3. String可以和8种基本数据类型变量做运算,且运算只能是连接运算;+
4. 运算的结果任然是String类型
*/
class StringTest{
public static void main(String[] args){
String s1 = "Good Moon!";
System.out.println(s1);
String s2 = "a";
String s3 = "";
// char c = ''; //编译不通过
//*******************************
int number = 1001;
String numberStr = "学号:";
String info = numberStr + number; //连接运算
boolean b1 = true;
String info1 = info + true;
System.out.println(info1);
}
}
练习1
String str1 = 4; //判断对错:no
String str2 = 3.5f + “”; //判断str2对错:yes
System.out.println(str2); //输出:”3.5”
System.out.println(3+4+“Hello!”); //输出:7Hello!
System.out.println(“Hello!”+3+4); //输出:Hello!34
System.out.println(‘a’+1+“Hello!”); //输出:98Hello!
System.out.println(“Hello”+‘a’+1); //输出:Helloa1
3.4、强制类型转换
- 自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时要加上强制转换符:(),但可能造成精度降低或溢出,格外要注意。
- 通常,字符串不能直接转换为基本类型,但通过基本类型对应的包装类则可以实现把字符串转换成基本类型。
- 如:
String a = “43”; inti= Integer.parseInt(a); boolean类型不可以转换为其它的数据类型。
练习2
判断是否能通过编译
short s = 5;
s = s-2; //判断:no
byte b = 3;
b = b + 4;//判断:no
b = (byte)(b+4);//判断:yes
char c = ‘a’;
int i = 5;
float d = .314F;
double result = c+i+d; //判断:yes
byte b = 5;
short s = 3;
short t = s + b;//判断:no
04、进制
4.1、进制与进制间的转换
关于进制
- 所有数字在计算机底层都以二进制形式存在。
- 对于整数,有四种表示方式:
- 二进制(binary):0,1 ,满2进1.以
0b或0B开头。 - 十进制(decimal):0-9 ,满10进1。
- 八进制(octal):0-7 ,满8进1. 以数字
0开头表示。 - 十六进制(hex):0-9及A-F,满16进1. 以
0x或0X开头表示。此处的A-F不区分大小写。如:0x21AF +1= 0X21B0
- 二进制(binary):0,1 ,满2进1.以
class BinaryTest{
public static void main(String[] args){
int num1 = 0b110;
int num2 = 110;
int num3 = 0127;
int num4 = 0x110A;
System.out.println("num1 = " + num1);
System.out.println("num2 = " + num2);
System.out.println("num3 = " + num3);
System.out.println("num4 = " + num4);
}
}
4.2、二进制
- Java整数常量默认是int类型,当用二进制定义整数时,其第32位是符号位;当是long类型时,二进制默认占64位,第64位是符号位
- 二进制的整数有如下三种形式:
- 原码:直接将一个数值换成二进制数。最高位是符号位
- 负数的反码:是对原码按位取反,只是最高位(符号位)确定为1。
- 负数的补码:其反码加1。计算机以二进制补码的形式保存所有的整数。
- 正数的原码、反码、补码都相同,负数的补码是其反码+1
为什么要使用原码、反码、补码表示形式呢?
计算机辨别“符号位”显然会让计算机的基础电路设计变得十分复杂! 于是人们想出了将符号位也参与运算的方法. 我们知道, 根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有减法, 这样计算机运算的设计就更简单了。

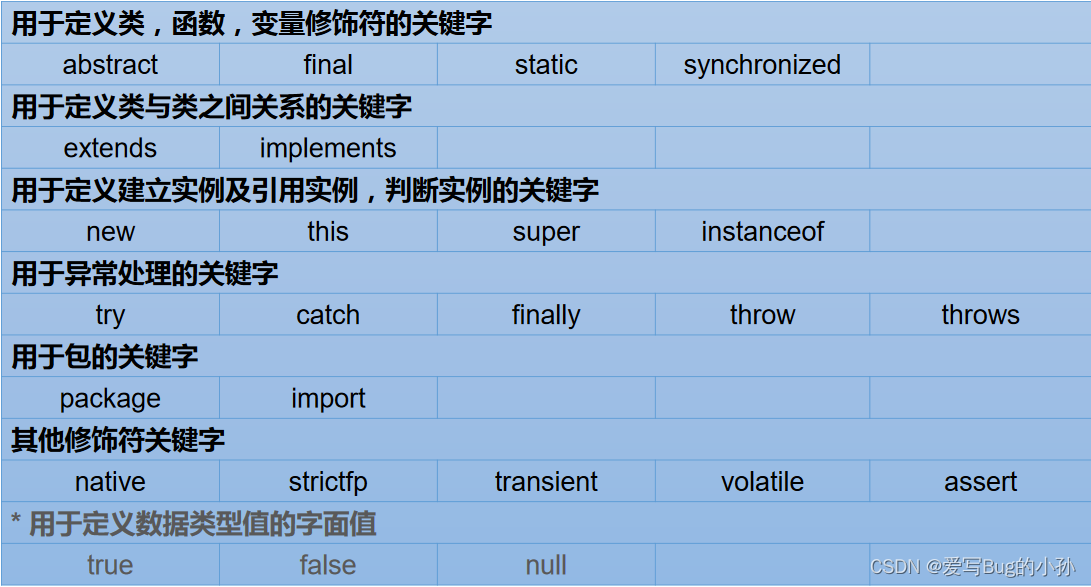
二进制——》十进制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H2V96yvo-1654818555381)(./upload/BlogPicBed-1-master/img/2021/01/27/20210127183824)]](https://img-blog.csdnimg.cn/3ac0c244df9240f18c469e9119bad1d1.png)
原码与反码是帮助推导出补码而存在的!!!
十进制——》二进制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VOKX421s-1654818555381)(./upload/BlogPicBed-1-master/img/2021/01/27/20210127183817)]](https://img-blog.csdnimg.cn/c0b82c5497574359b4ffbd758719859e.png)
- 对于正数来讲:原码、反码、补码是相同的:三码合一。
- 计算机底层都是使用二进制表示的数值。
- 计算机底层都是使用的数值的
补码保存数据的。
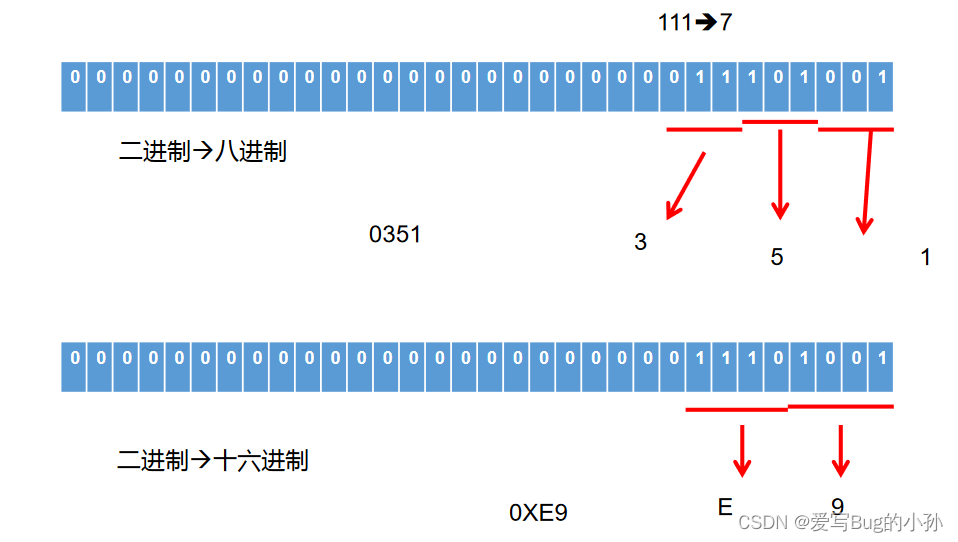
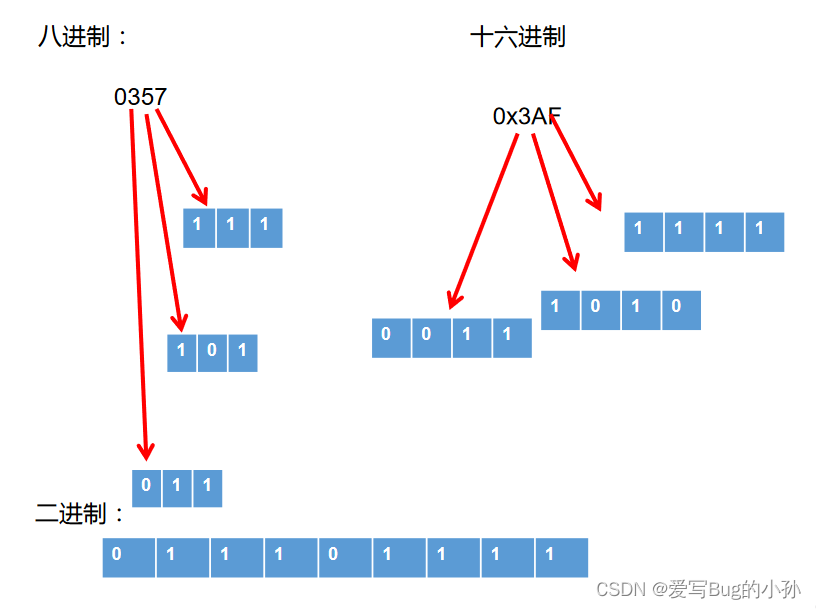
4.3、进制间转化
十进制二进制互转
- 二进制转成十进制乘以2的幂数
- 十进制转成二进制除以2取余数















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









