






What:
Phi-3-Mini被认为是Microsoft计划发布的三款小型机型中的首款。据报道,在语言、推理、编码和数学等领域,它在各种基准测试中的表现优于相同大小和下一个尺寸的模型。
从本质上讲,语言模型是 ChatGPT、Claude、Gemini 等 AI 应用程序的支柱。这些模型在现有数据上进行训练,以解决常见的语言问题,例如文本分类、回答问题、文本生成、文档摘要等。
Why
1、语言生成质量提升: Phi-3-mini 在生成文本时可以提供更加流畅、连贯和自然的输出。这对于需要高质量文本生成的应用非常有用,比如文档生成、创意写作等。
2、更快的响应速度: 尽管 Phi-3-mini 比较 Phi-3.5 更小,但它的推理速度更快,这意味着可以更快地对输入进行响应,减少用户等待时间。
3、适用于资源有限的环境: 由于它的规模较小,Phi-3-mini 在资源有限的环境(如移动设备或嵌入式系统)中运行效率更高,能够提供良好的性能和体验。
4、语言理解能力: Phi-3-mini 在理解输入文本并提供相关信息方面也有所改进,能够更准确地回答问题或提供相关建议。
How
首先介绍一个软件:ollama,
Ollama是一个用于在本地计算机上运行大型语言模型(LLMs)的命令行工具。它允许用户下载并本地运行像Llama 3、Phi3等模型,并支持自定义和创建自己的模型。Ollama是免费开源的项目,支持macOS、Linux和Windows操作系统。它还提供了官方的Docker镜像,使用户可以通过Docker容器部署大型语言模型,确保所有与模型的交互都在本地进行。
此外,Ollama也是一个开源的大型语言模型服务,提供了类似OpenAI的API接口和聊天界面,可以非常方便地部署最新版本的GPT模型并通过接口使用。它支持热加载模型文件,无需重新启动即可切换不同的模型。
优点:
- 本地利用 cpu 运行大模型,本地安全可靠。
- ollama 命令,管理大模型相对方便,也可以多个大模型中切换。
- 终端直接开始聊天。
- 社区提供了支持 web api 方式访问 WebUI
官网:https://ollama.com/
进入 ollama 下载页面,选择自己的系统版本的下载并安装即可。
验证是否已经安装
输入 ollama 命令,正常的得出命令行输出,表示已经安装成功
我这里是Mac,可以在应用中看到图标。显示已经安装成功。

查看下载命令
点击进去。执行命令
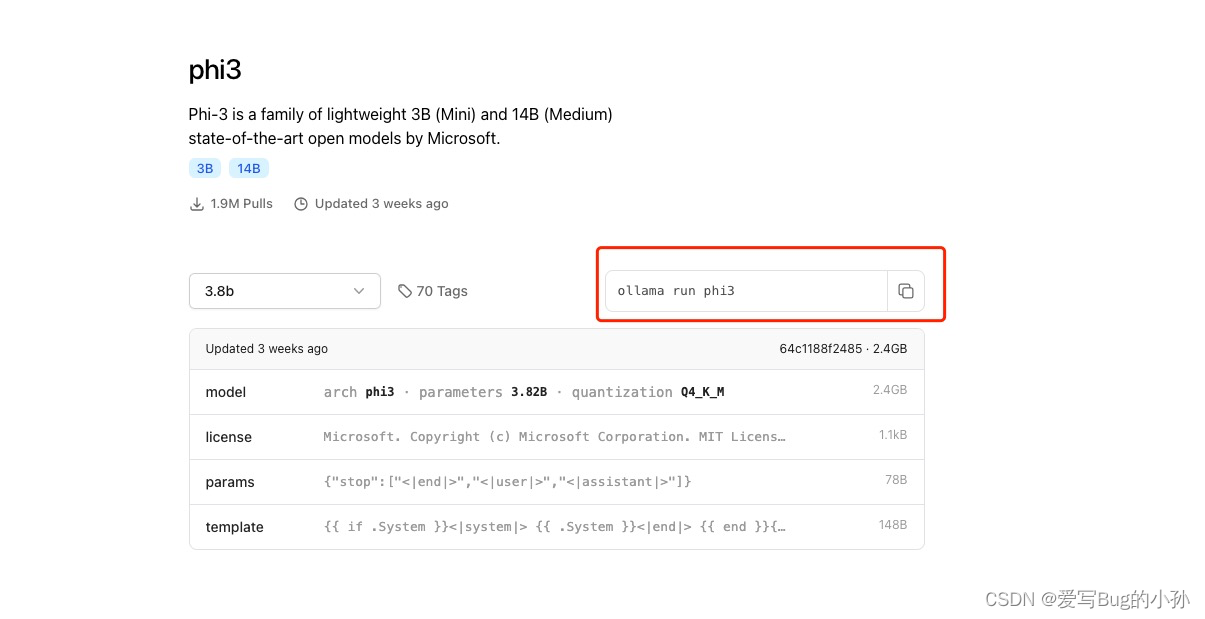
命令:ollama run phi3
安装界面

直接在终端中对话:用 phi3 模型写一个 nextjs组件或者 回答你的一些知识类问题
案例:

可视化UI界面可以试试 Open WebUI
docker 部署
如果您的计算机上有 Ollama,请使用以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
其中:–add-host 选项需要指定一个有效的 IP 地址。在命令中,host.docker.internal:host-gateway需要替换电脑本地的ip
如果你电脑的本地ip为:192.168.1.1,则命令是:
docker run -d -p 3000:8080 --add-host=host.docker.internal:192.168.1.1 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
安装完成后,可以通过访问Open WebUI。😄
http://localhost:3000
注册账号密码。直接就可以使用图形化聊天界面了。
以上,只是一个基本本地部署流程,实际使用还有很多好的功能与用法。查询了一下ollama 大部分代码基于 go 开发,大家可以多多探索。


















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











