







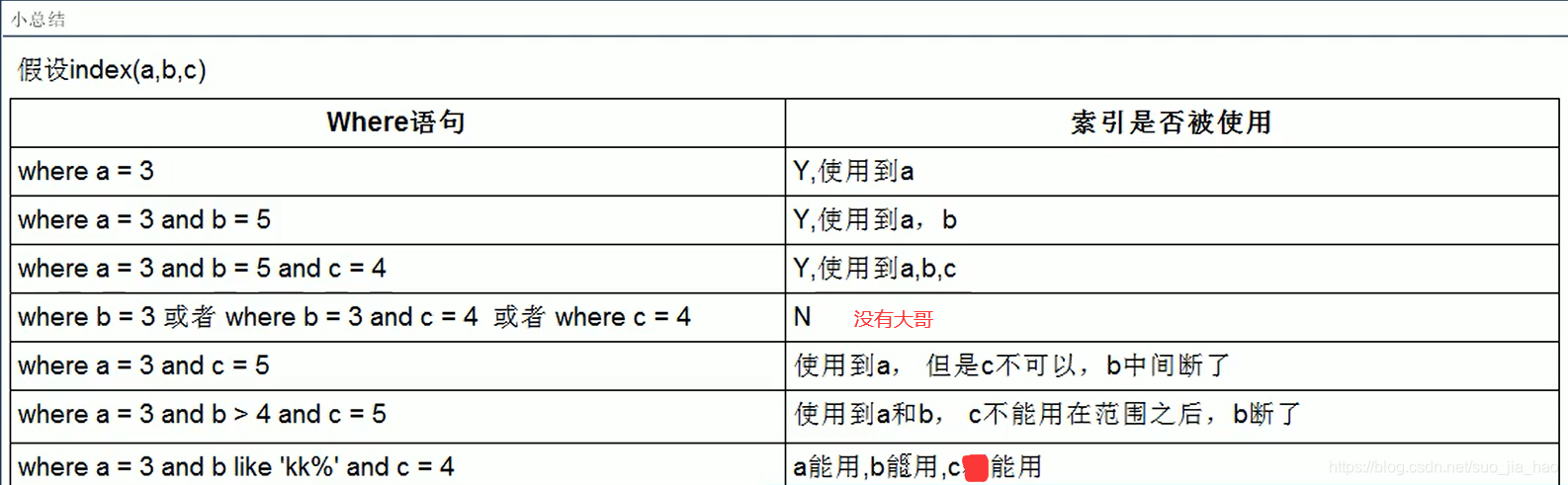
索引失效
本文参考尚硅谷视频
口诀:带头大哥不能死,中间兄都不能断,索引列上无操作,范围右边全失效,like百分加右边,字符串中有引号
准备:
建立员工记录表staffs(id,name,age,pos,add_time)
给表中name,age,pos字段添加索引(注意三个字段的顺序)
alter table staff
add index idx_staffs_nameAgePos(name,age,pos)
①最佳左前缀法则
指的是查询从索引的最左前列开始并且不跳过索引中的列
(带头大哥不能死,中间兄弟不能断)
(火车头带着车身跑,不能没有火车头,中间也不能缺少一段火车身)
例:
第一种情况,name字段索引一直被使用
mysql>EXPLAIN SELECT * FROM staffs WHERE NAME = ‘July’

上图可知,idx_staffs_nameAgePos索引有三个字段,name,age,pos
其中,只查找name可以使用索引
只查找name和age也可以使用索引
查找name,age,pos三个字段也可以使用索引
第二种情况,当不查找name而去查找后面age和pos字段时

索引失效了
第三种情况,查找了name字段和pos字段,而缺少了中间的age字段
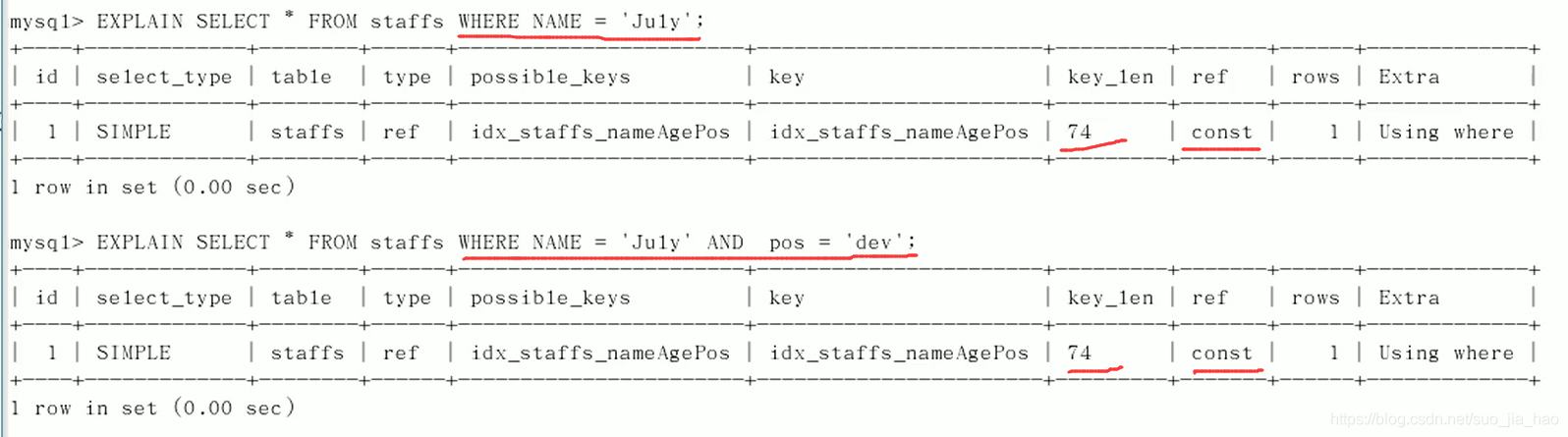
上图对比了分别查找name字段和name,pos字段的两种情况,发现虽然都用到了idx_staffs_nameAgePos索引,但是key_len长度没变,ref索引用到的字段也没变,说明针对字段pos的索引失效了,原因是缺少了中间的age索引字段
②不要再索引列上做任何操作
不要在索引列上左任何操作(计算,函数,自动or手动类型转换),会导致索引失效转换为全表扫描
例:
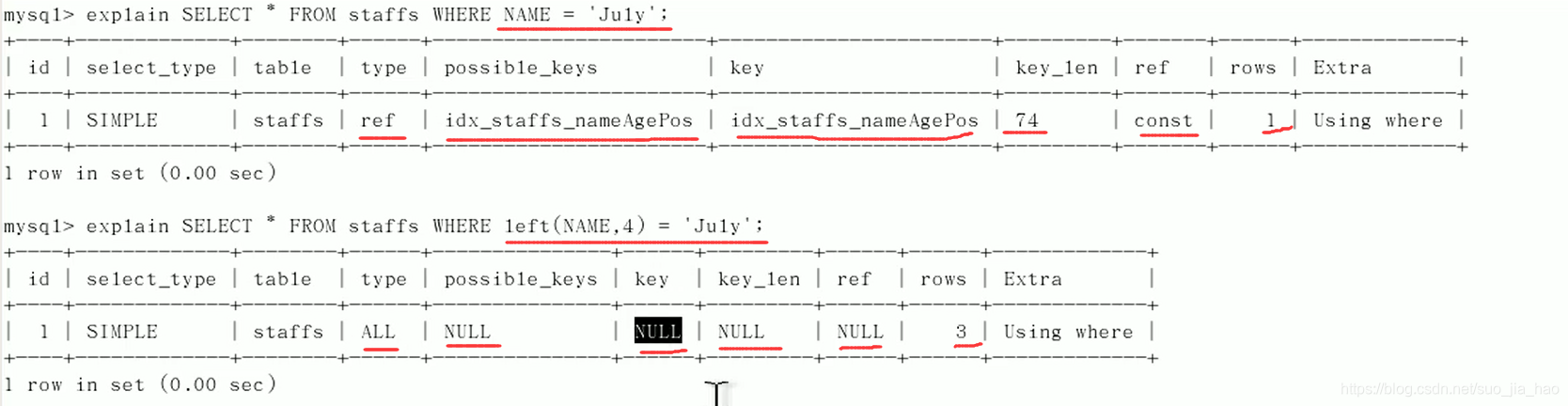
上图可以看到,没用left函数之前,是一个正常的索引引用,使用函数之后,索引失效了
③存储引擎不能使用索引中范围条件右边的列
与上面单表索引优化分析中的例子一样

第一个查询全等值匹配没问题
第二个查询中间使用了范围条件,结果导致manger的索引失效
按照BTree索引的工作原理,先排序name,如果遇到相同的name则再排序age,如果遇到相同的age则再排序pos,当age字段在复合索引中间时,因age>25条件是一个范围值(所谓range),MySQL无法利用索引再对后面的pos部分进行建索,即range类型查询字段后面的索引无效
④尽量使用覆盖索引
只访问索引列的查询,索引列和查询列一致,避免select *

当只访问了索引列后,Extra中出现了Using index,表明是覆盖查询,这是好的
⑤Mysql在使用(<>或!=或is null或is not null)时无法使用索引会导致全表扫描(现在改了)
注:新版本的MySQL中这些已经可以使用索引了

⑥like以通配符(%)开头的索引会失效变成全表扫描
以%开头会失效,变成全表扫描
通配符出现最前面说明所有都适配,所有都要扫描

不以%开头则不失效

如何解决?
可以使用覆盖索引
tb1_user表中有id,name,age,email四个字段,对name,age字段设置索引,id自动为主键索引
那么查询id,name,age字段都是覆盖索引,都可以使索引生效

但是如果使用explain select * from tb1_user where name like '%aa%'就会索引失效,因为此时不是覆盖索引,不是覆盖索引使用%会失效
⑦字符串不加单引号会导致索引失效
name字段为varchar类型
假设有一行name=‘2000’,这时如果用name=2000条件查找也会有结果
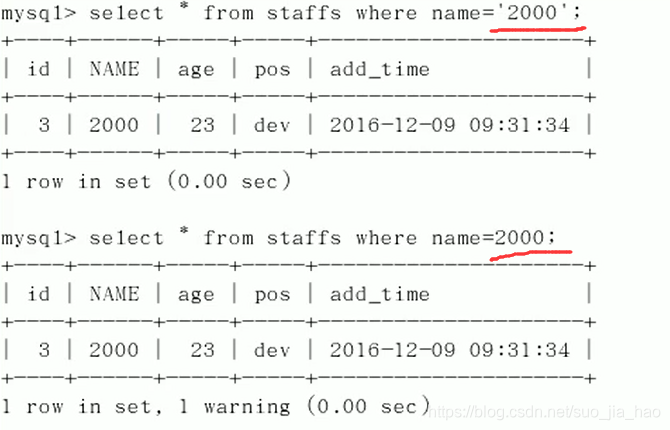
用EXPLAIN分析
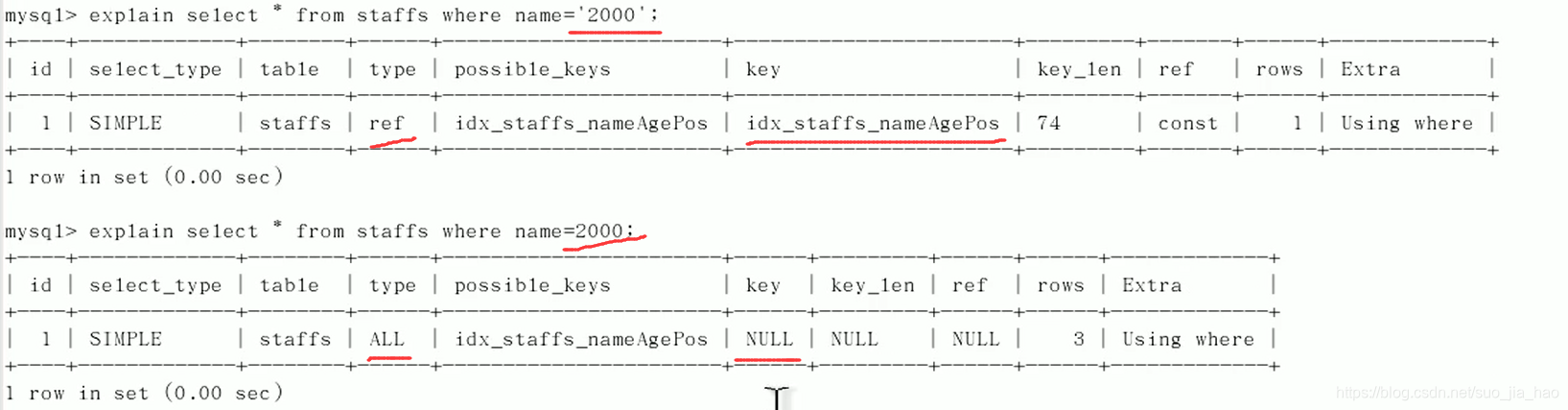
可以看出,用name=2000作为判断条件,不加单引号导致索引失效了,为什么?
因为name=2000也可以查出来是因为MySQL在底层做了一次类型转换,把整形2000转换成了字符串’2000’
违背了上面第②条的不要在索引列上左任何操作的原则,所以索引失效了
练习
2.条件顺序改变
假设表student中id,name,age三个字段建立了一个复合索引
那么条件列的顺序换换索引是否还能有效?
explain select * from student where id = 1 and name = "张三" and age = 22
与
explain select * from student where name = "张三" and id = 1 and age = 22
答案:yes,M有SQL的优化器会自动给列排序为创建索引时的列,但是还是建议顺序与索引列顺序一致,提高效率
3.order by 只排序,不查询
建表test03(c1,c2,c3,c4)
对c1,c2,c3,c4加复合索引

先是MySQL优化器对where后面的条件进行排序,c1,c2,c3,c4
由于索引功能有两个,分别是排序与查询,对c3进行排序并没有查询,但也是用到了索引,所以实际上c1,c2,c3都用到了索引,而c4由于c3没有等值判断所以用不到索引,索引对c4失效了。
4.order by 中的字段顺序不能调换

由order by 的特性可知,order先对c3排序后再对c2排序,所以优化器不会把c3,c2顺序互换,这就导致了最终的是顺序是c1,c3,c2,c5
只有c1用到了索引,c3与c1中间缺少了c2,所以c3用不到索引,c5本身就没有索引
所以对c3和c2的排序没有用到内部索引,使用了外部索引Using filesort

这里虽然order by 中是先c3再c2,但是前面条件查询时已经用到了c2,所以实际用到索引的顺序是c1,c2,c3
所以c1,c2都使用到了索引,ref为两个const,Extra也没有出现Using filesort
5.group by先排序后分组,用法与order by一样
6.like的%位置关系

第一条sql语句与第四条效果一样,range范围类型,用到了三个索引列,ref为null
为什么这里ref为null?明明三个索引都被使用了,前文提到过,range范围后的索引都会失效,但是like是特例,由于%不在第一个位置上,第一个位置上的是k,k是一个确定的值,所以可以算作查询被使用索引,所以能连通c3,c3也能使用索引
第二条sql语句与第三条效果一样,ref一对多结果,用到了一个索引列,ref为const
为什么这里ref为const?
因为like后面%在第一个位置上,导致like后面的索引全失效,所以只有c1的索引有效
小表驱动大表
5 X 1000 == 1000 X 5 ,但是在数据库中第一种比第二种好,连接5次数据库,每次查1000条,连接1000次数据库,每次查5条,肯定第一种好
举例:查找华为公司各部门的员工信息(员工表A,部门表B)
第一种:用in函数(A表数量大于B表,用in,先查in括号里面的少的表)
select * from A where A.id in (select B.id from B)
第一步:select B.id from B
第二步:select * from A where A.id = B.id
部门表的数量肯定比员工表少,所以用部门表驱动员工表,小表驱动大表
如果先查员工表,那么需要对员工表进行全表搜索,相比较部门表,肯定效率低
第二种:用exist函数(B表数量小于A表,先查B表,再判断B表中是否有满足条件的数据)
select * from B where exists(select 1 from A where A.id = B.id)
第一步:select * from B
第二步:select * from B where A.id = B.id
exist()子查询只返回true或false,因此select 1也可以是任意select * ,官方说法是忽略select清单
select ... from table where exist(subquery)
该语法可以理解为:将主查询的数据放到子查询中做条件验证,根据验证结果(true或false)来决定主查询的数据结果是否得以保留
排序优化
1.order by后面的顺序必须和索引顺序一致,否则会造成使用order by的内部排序(file sort)
#建表
create table tblA(
#id int primary key not null auto_increment,
age int,
birth TIMESTAMP not null
)
#创建age,birth的索引
create index idx_tblA_age_birth on tblA(age,birth)
#1.只对age排序,没问题,用上索引
explain select * from tblA where age > 20 order by age
#2.先对age排序,再对birth排序,没问题
explain select * from tblA where age > 20 order by age,birth
#3.顺序一变,出现了filesort,危险的文件排序,索引失效
explain select * from tblA where age > 20 order by birth,age
#4.带头大哥age不在了,所以索引失效,用到了索引,是索引失效
explain select * from tblA where birth > '2021-10-10 00:00:00' order by birth
#5.带头大哥存在,索引生效
explain select * from tblA where birth > '2021-10-10 00:00:00' order by age
#6.age升序,birth降序,打乱了索引的结构,索引失效
explain select * from tblA order by age asc , birth desc
order by支持两种方式的文件排序,FileSort和index,index效率高,filesort效率低
能成功使用index的情况:1.满足最左前缀法则2.排序统一
2.filesort有两种排序算法,可能是单路排序的缓存空间太小导致效率降低
双路排序(mysql4.1之前):两次扫描磁盘,读取待排序的那一列,I/O非常耗时,所以效率低
单路排序:从磁盘中读取查询需要的所有列,按照order by在buffer对它们进行排序,然后扫描排序后的列表进行输出。它的效率更快,因为第一次读取数据后放到了缓冲中,把随机I/O变成了顺序I/O,但是会占用更多的内存空间
单路排序可能出现的问题:
单路算法总体好于双路算法,但是如果一次读取不完所有数据,会造成多次读取,反而效率还低于多路算法,如果sort_buffer_size比较小,单路排序每次只能取出sort_buffer_size大小的数据,取不完就要多次取。
多路算法也可能超出缓冲区,但是单路算法的风险更大
3.order by 排序不要用select *
因为select * 查询所有的,占用的排序缓冲区太大,在单路算法下,很可能超出缓冲区大小,就会多次I/O读取,降低效率
show profiles诊断sql
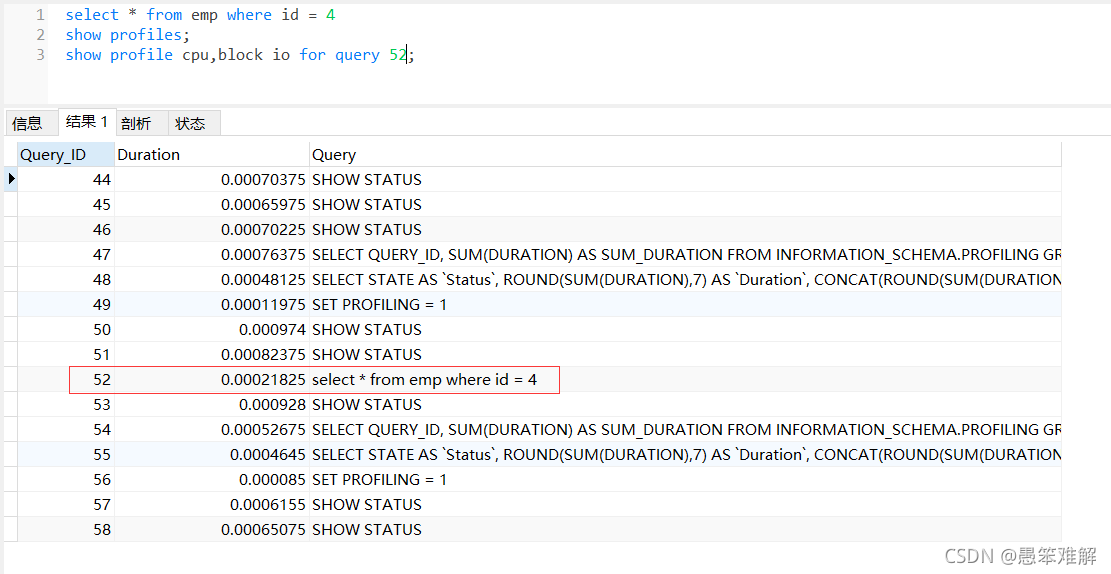
show profiles:查看之前执行的所有sql及运行时间
1.先执行一条sql
select * from emp where id = 4
2.进行show profiles,可以看到刚才执行的那条sql的id为52
show profiles
3.查看刚才那条语句在内存中详细的运行状态
show profile cpu,block io for query 52;
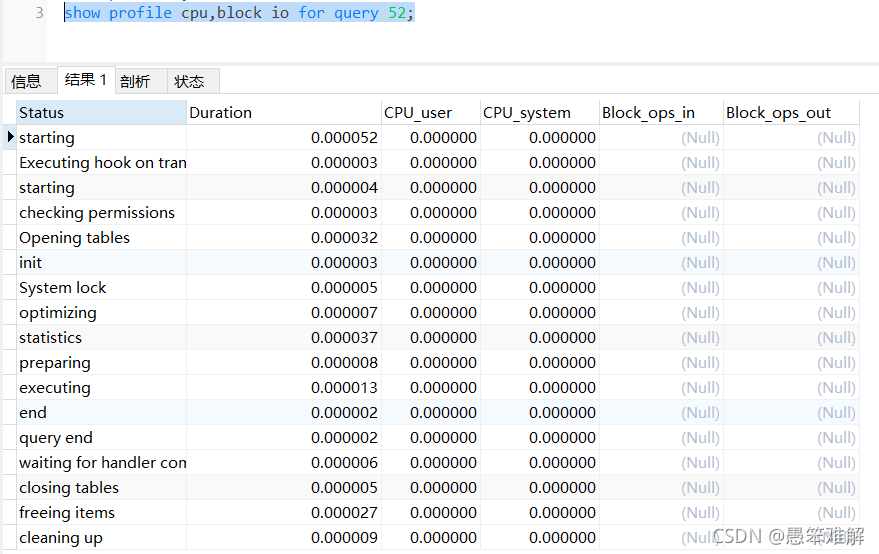
常用type
all: 显示所有的开销信息
block io: 显示块IO相关开销
context switches: 上下文切换相关开销
cpu: cpu相关开销
ipc: 显示发送和接收相关开销
memory: 显示内存相关开销信息
page faults: 显示错误页面相关开销信息
source: 显示和source_function,source_file,source_line相关的开销信息
swaps: 显示交换次数相关开销的信息
如果查询详细的运行状态中有一下四个中的任何一个,必须优化
1.converting HEAP to MyISAM :查询结果太大,内存不够用了,往磁盘上搬
2.Create tmp table :创建临时表。(数据拷贝到临时表,用完再删除)
3.Copying to tmp table on disk:把内存临时表复制到磁盘,危险
4.locked:锁住了















 8893
8893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









