







看腻了就来听听视频演示吧:
SQL拼接获取DDL:https://www.bilibili.com/video/BV1Rw4m1Z7SV/
dump方式获取DDL:https://www.bilibili.com/video/BV1Wt421b75Q/
创建测试数据
-- 创建serial字段类型的表,序列和表有强关联关系
drop table if exists t_serial;
create table t_serial(col1 serial,col2 varchar(60));
insert into t_serial (col2) select md5(random()::text) from generate_series(1,10);
-- 直接创建序列使用,表的default默认值设置为序列值,序列和表并无强关联关系
drop table if exists t_test;
drop SEQUENCE if exists t_test_id_seq;
CREATE SEQUENCE t_test_id_seq START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
create table t_test(id int,name varchar(80));
alter table t_test alter COLUMN id set not null;
alter table t_test alter COLUMN id set default nextval('t_test_id_seq'::regclass);
insert into t_test (name) select md5(random()::text) from generate_series(1,10);
dump导出方式
把库和创建的表导出来看看情况:
-- 单库导出:CREATE TABLE -> CREATE SEQUENCE -> COPY -> setval
pg_dump testdb -f db_testdb_all.sql
-- 单库仅导出DDL:1)serial:CREATE TABLE -> CREATE SEQUENCE 2)手动创建的序列:CREATE SEQUENCE -> CREATE TABLE 【没COPY导数据过程忽略setval步骤】
pg_dump testdb -s -f db_testdb_ddl.sql
-- 导出serial类型的表:CREATE TABLE -> CREATE SEQUENCE -> COPY -> setval
pg_dump testdb -t public.t_serial -f tbl_t_serial.sql
-- 导出手动创建序列使用的表:CREATE TABLE -> COPY 【默认序列已存在,不会导出序列】
pg_dump testdb -t public.t_test -f tbl_t_test.sql
表列与序列强关联
pg_get_serial_sequence 返回与列关联的序列名
-- select pg_get_serial_sequence('表名','列名');
21:00:13 muser@testdb=> \df pg_get_serial_sequence
List of functions
Schema | Name | Result data type | Argument data types | Type
------------+------------------------+------------------+---------------------+------
pg_catalog | pg_get_serial_sequence | text | text, text | func
(1 row)
21:00:53 muser@testdb=> select pg_get_serial_sequence('t_serial','col1');
pg_get_serial_sequence
--------------------------
public.t_serial_col1_seq
(1 row)
-- 手动创建的序列不会与表关联
21:01:01 muser@testdb=> select pg_get_serial_sequence('t_test','id');
pg_get_serial_sequence
------------------------
(1 row)
-- 调整序列为表列的所有者即关联序列后即可查询到,等效于serial类型
21:05:53 muser@testdb=> alter sequence t_test_id_seq owned by t_test.id;
ALTER SEQUENCE
21:06:15 muser@testdb=> select pg_get_serial_sequence('t_test','id');
pg_get_serial_sequence
------------------------
public.t_test_id_seq
(1 row)
调整序列为表列的所有者后即等效于serial类型,dump导出效果也是一样的。
case场景
遇到一个需求:业务要当前使用的序列DDL,上面dump出来的数据就存在两个问题:
1). 单库或模式导出DDL的序列创建语句START WITH的值为下面视图的start_value,而非当前currval的值,即last_value。这就会出现序列重复冲突的问题
2). 单库包括数据一起导出,即CREATE TABLE -> CREATE SEQUENCE -> COPY -> setval,然后再过滤CREATE和setval语句。可满足需求但当数据量较大会使过滤文件耗时较长
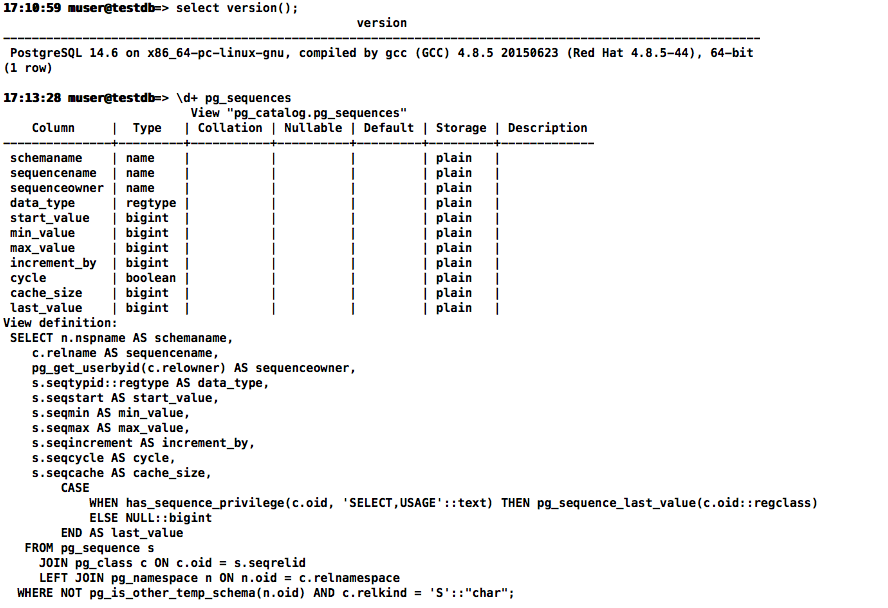
记录序列的视图:
17:10:25 muser@testdb=> \d+ pg_sequences
View "pg_catalog.pg_sequences"
Column | Type | Collation | Nullable | Default | Storage | Description
---------------+---------+-----------+----------+---------+---------+-------------
schemaname | name | | | | plain |
sequencename | name | | | | plain |
sequenceowner | name | | | | plain |
data_type | regtype | | | | plain |
start_value | bigint | | | | plain |
min_value | bigint | | | | plain |
max_value | bigint | | | | plain |
increment_by | bigint | | | | plain |
cycle | boolean | | | | plain |
cache_size | bigint | | | | plain |
last_value | bigint | | | | plain |
View definition:
SELECT n.nspname AS schemaname,
c.relname AS sequencename,
pg_get_userbyid(c.relowner) AS sequenceowner,
s.seqtypid::regtype AS data_type,
s.seqstart AS start_value,
s.seqmin AS min_value,
s.seqmax AS max_value,
s.seqincrement AS increment_by,
s.seqcycle AS cycle,
s.seqcache AS cache_size,
CASE
WHEN has_sequence_privilege(c.oid, 'SELECT,USAGE'::text) THEN pg_sequence_last_value(c.oid::regclass)
ELSE NULL::bigint
END AS last_value
FROM pg_sequence s
JOIN pg_class c ON c.oid = s.seqrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE NOT pg_is_other_temp_schema(n.oid) AND c.relkind = 'S'::"char";
序列DDL拼接SQL语句
这里我们可以根据序列记录的视图来拼接下序列的DDL
-- 拼接public模式下的序列DDL
select 'create sequence ' || a.schemaname || '.' || a.sequencename || ' INCREMENT BY ' || a.increment_by || ' START WITH ' || a.last_value+1 || ' MAXVALUE ' || a.max_value ||
case when a.cycle='t' then ' CYCLE' else ' NOCYCLE' end ||
case when a.cache_size=1 then ' nocache' else ' cache ' || cache_size end || ';'
from pg_sequences a where a.schemaname='public';
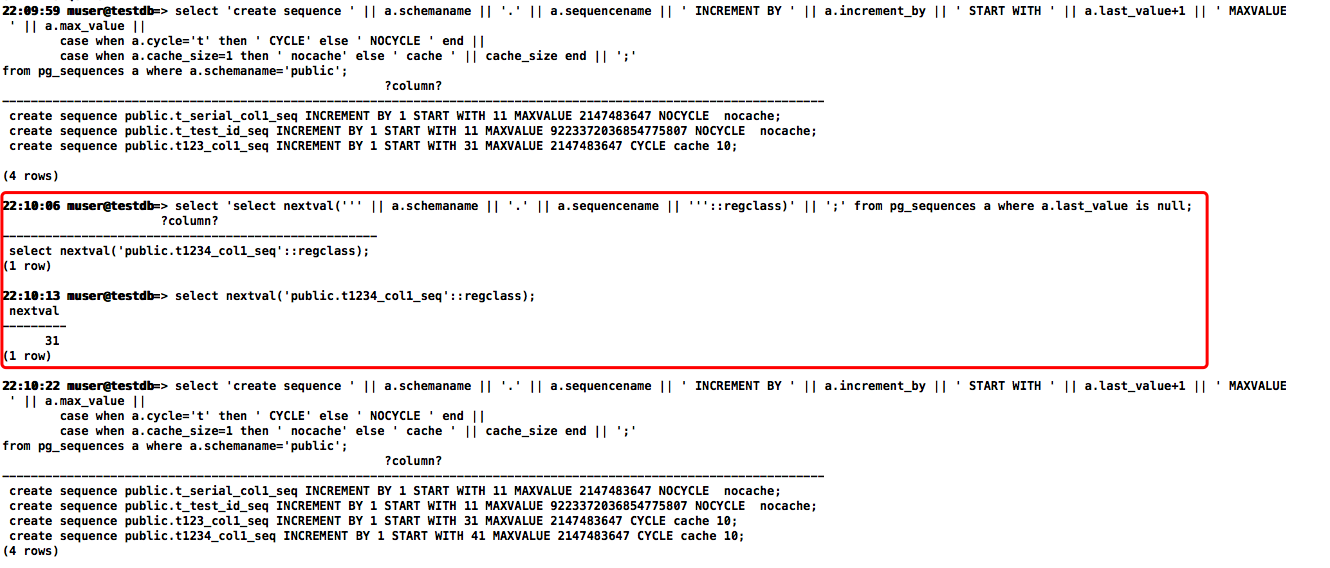
这里拼接的序列DDL还有个小问题:新创建的序列last_value列值为null,需要先手动执行下nextval后才能搜索到
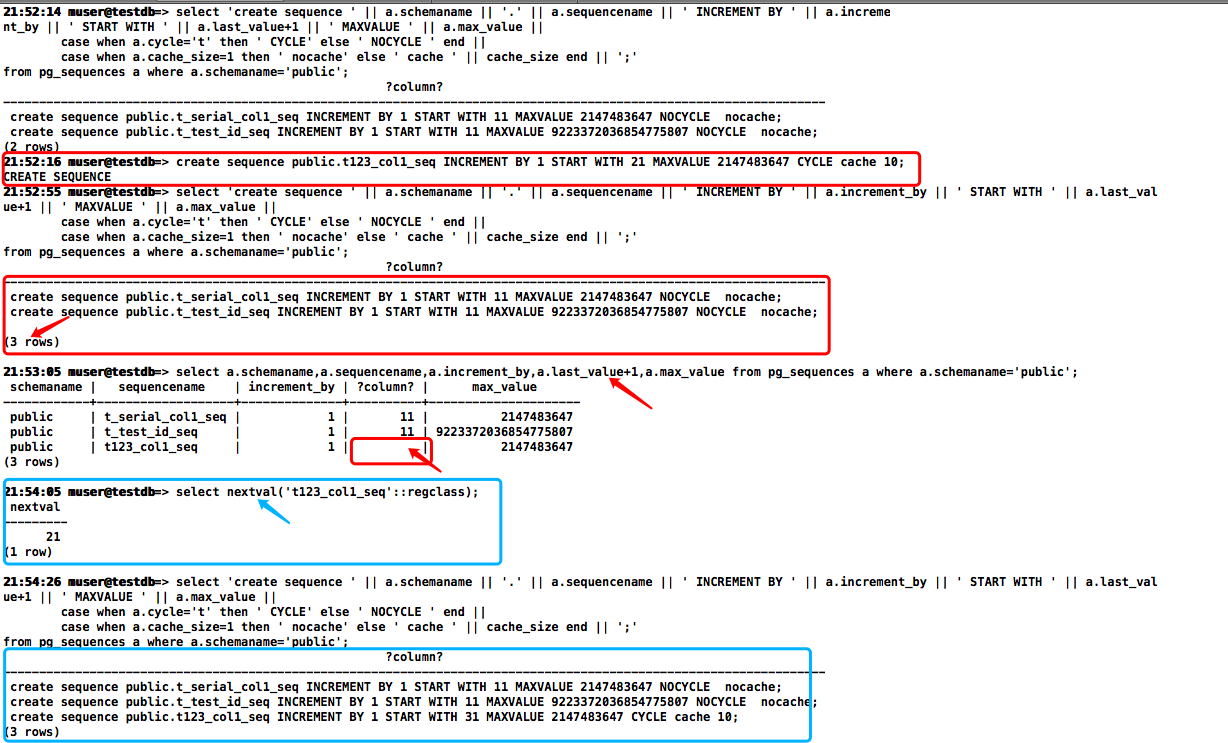
于是先拼接下last_value值为null的序列手动执行下
select 'select nextval(''' || a.schemaname || '.' || a.sequencename || '''::regclass)' || ';' from pg_sequences a where a.last_value is null;
序列删除情况
删除表时序列的情况
- 序列和表有强关联关系:serial类型或调整过序列为表列的所有者即关联序列的情况,删除表对应序列会一起被删除
- 序列和表无强关联关系:删除表对序列不影响
















 2377
2377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









