







 本文通过一个简单的增强学习例子,介绍了Deep Q Learning算法。主要内容包括replay_buffer的概念,神经网络在估算动作价值中的作用,以及epsilon-greedy策略的解释。文章还提供了关键代码解析,展示如何使用神经网络进行训练和优化,并给出了主程序的执行流程。
本文通过一个简单的增强学习例子,介绍了Deep Q Learning算法。主要内容包括replay_buffer的概念,神经网络在估算动作价值中的作用,以及epsilon-greedy策略的解释。文章还提供了关键代码解析,展示如何使用神经网络进行训练和优化,并给出了主程序的执行流程。
我们现在来用之前提到的Q-Learning算法,实现一个有趣的东西
1. 算法效果
我们想要实现的,就是一个这样的小车。小车有两个动作,在任何一个时刻可以向左运动,也可以向右运动,我们的目标是上小车走上山顶。一开始小车只能随机地左右运动,在训练了一段时间之后就可以很好地完成我们设定的目标了
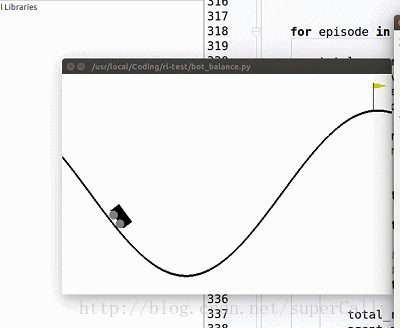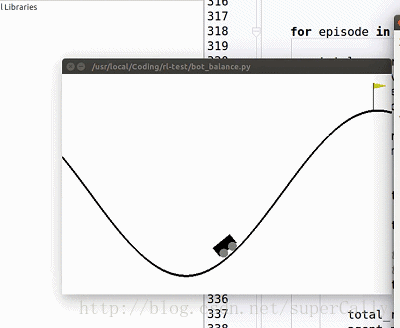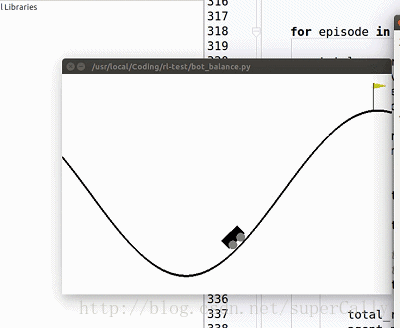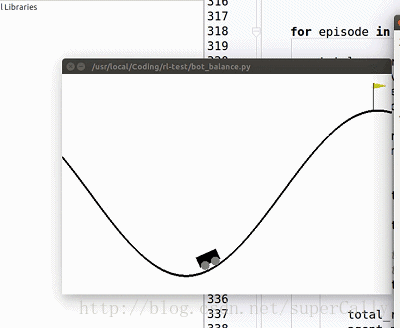
2. Deep Q Learning 算法简单介绍
就像我们在前一章里面简单介绍的,我们使用的算法就是最简单的Deep Q Learning算法,算法的流程如下图所示
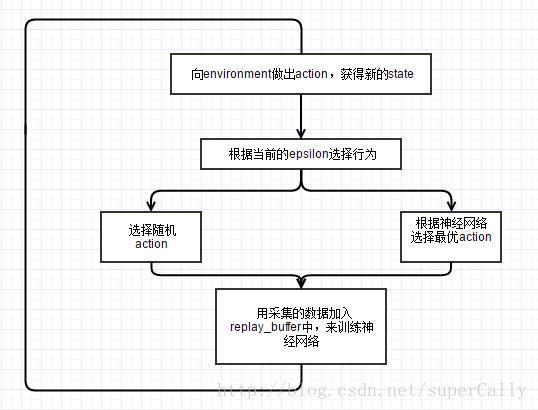
我们可以看到,这个算法里面主要有这样几个要素
1. replay_buffer
我们在不断地在系统中训练的过程中,会产生大量的训练数据。虽然这些数据并不是应对当时环境最优的策略,但是是通过与环境交互得到的经验,这对于我们训练系统是有非常大的帮助的。所以我们设置一个replay_buffer,获得新的交互数据,抛弃旧的数据, 并且每次从这个replay_buffer中随机取一个batch,来训练我们的系统
replay_buffer中的每一条记录包含这几项:
- state,表示当时系统所面临的状态
- action,表示我们的agent面临系统的状态时所做的行为
- reward,表示agent做出了选择的行为之后从环境中获得的收益
- next_state,表示agent做出了选择的行为,系统转移到的另外一个状态
- done,表示这个epsiode有没有结束
我们就用这个状态集来训练我的神经网络
这种平等地对待所有采集数据的策略似乎不是很有效,有的数据明显更有用(比如说那些得分的数据),所以我们可以在这一点上对他进行优化,就是prioritized_replay_buffer,后面我们会专门写文章进行介绍
2. 神经网络
在这里我们为什么会用神经网络呢?
因为对于某一个时刻系统的状态,我们需要估算在这个状态下,我们采取状态集S当中的每一个动作,大概会产生多大的收益
然后我们就可以根据我们既定的策略,在比较了收益之后,选一个动作
神经网络的输入,是系统的一个状态,state
神经网络的输出,是状态集当中的每一个动作,在当前状态下,会产生的价值
输入是系统给定的,输出是我们估算出来的,我们用估算的这个输出,来替代之前的输出,一步步地进行优化
有了这些数据,我们就可以对神经网络来做优化了
但是我们拿到了每个动作的价值之后,该采取怎样的策略呢?在基本的Q-Learning算法中,我们采取最最简单的epsilon-greedy策略
3. epsilon_greedy
这个策略虽然简单,但是十分的有效,甚至比很多复杂的策略效果还要好
具体的介绍可以看这篇文章https://zhuanlan.zhihu.com/p/21388070,我们在这里简单介绍一下
我们设置一个阈值,epsilon-boundary,比如说初始值是0.8,意思就是我们现在选择action的时候,80%的可能性是随机地从动作集中选择一个动作,20%的可能性是通过神经网络计算每个动作的收益,然后选最大的那一个
但是随着学习过程推进,我们的epsilon-boundary要越来越低,随机选择的次数要越来越少,到最后几乎不做随机的选择
3. 重点代码解析
Q_value_batch = self.Q_value.eval( feed_dict = { self.input_layer : next_state_batch } )
for i in xrange( BATCH_SIZE ):
if done_batch[i]:
y_batch.append( reward_batch[ i ] )
else:
y_batch.append( reward_batch[ i ] + GAMMA * np.max(Q_value_batch[ i ]) )
之前我们讲到,神经网络的作用就是,估算当前状态下采取每个action的价值。在这里,神经网络的输入是next_state,输出的是next_state的各个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









