






串
定义(逻辑结构)
串,即字符串(string)是由零个或多个字符组成的有限序列。一般记为:
S=‘a1a2a3…an’(其中数字是下标)(n>=0)
其中,S是串名,单引号括起来的字符序列是串的值;ai(i时下标)可以是字母,数字或者其它字符;串中字符的个数n称为串的长度。n=0时的串称为空串(用Φ表示)。
例:
S=“HelloWorld!”
T=‘iPhone 11 Pro Max?’
注意:有的地方用双引号(比如Java,C),有的地方用单引号(比如Python)(Python也有使用双引号的时候,这个时候就是要把单引号也给加入到字符串里面去)。
子串:串中任意个(也可以是0个)连续的字符组成的子序列。 Eg:‘iPhone’,'Pro M’是串T的子串
主串:包含子串的串。 Eg:T是子串’iPhone’的主串
字符在主串中的位置:字符在串中的序号。 Eg:'1’在T中的位置是8(第一次出现)
注意:字符编号是从1开始的,而不是从0开始的,这和我们线性表里面的位序是一样的。(空格也是字符)
子串在字符中的位置:子串的第一个字符在主串中的位置。 Eg:'11 Pro’在T中的位置为8
空串V.S空格串:
M=‘’(这时候的M是空串,里面什么都没有) N=’ '(N是由三个空格字符组成的字符串,每个空格字符占1B)
-
串是一种特殊的线性表,数据元素之间呈线性关系。
串的数据对象限定为字符集(如中文字符,英文字符,数字字符,标点字符等)
串的基本操作,如增删改查等通常以子串为操作对象。
基本操作(运算)
假设有串T=“”,S=“iPhone 11 Pro Max?”,W=“Pro”
StrAssign(&T,chars):赋值操作。把串T赋值为chars。
StrCopy(&T,S):复制操作。把串S复制得到串T。
StrEmpty(S):判空操作。若S为空串,则返回True,否则返回False。
StrLength(S):求串长。返回串S的元素个数。
ClearString(&S):清空操作。将S清为空串。
DestoryString(&S):销毁串。将串S销毁(回收存储空间)。
Concat(&T,S1,S2):串联接。用T返回由S1和S2联接而成的新串。(可能会导致存储空间扩展,可能在设计串的时候,要设计一种容易拓展的存储结构)
Eg:执行基本操作Concat(&T,S,W)后,T=“iPhone 11 Pro Max?Pro”
SubString(&Sub,S,pos,len):求子串。用Sub返回串S的第pos个字符起长度为len的子串。
Eg:执行基本操作SubString(&T,S,4,6)后,T=“one 11”
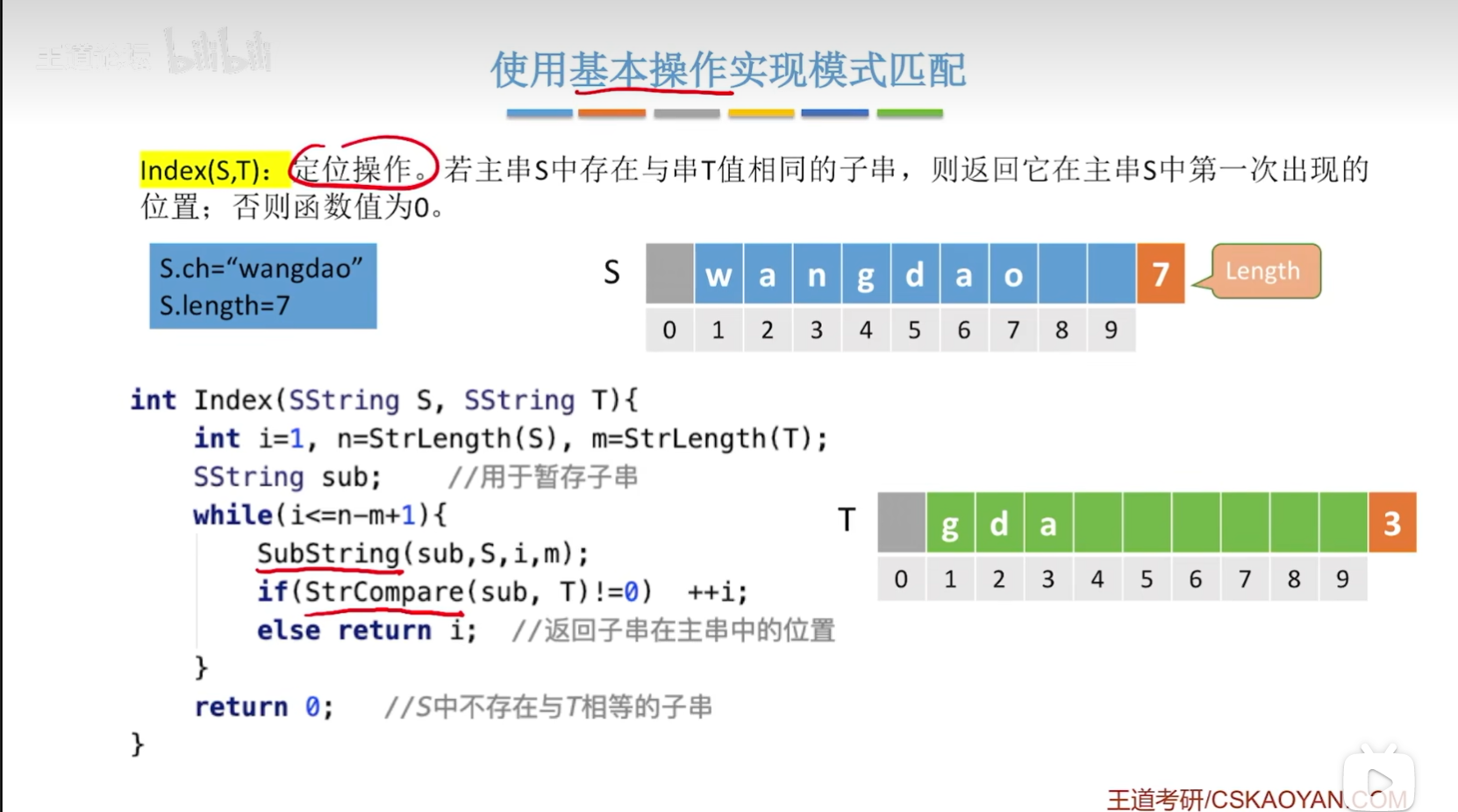
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。
Eg:执行基本操作Index(S,W)后,返回值为11。
StrCompare(S,T):比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。(比较原理:1.从第一个字符开始往后依次对比(使用ASCII表),先出现更大字符的串就更大;2.长串的前缀与短串相同时,长串更大;3.只有两个串完全相同时,才相等。
-
任何数据存到计算机中一定是二进制数。需要确定一个字符和二进制数的对应规则,这就是“编码”。
-
下图是ASCII表
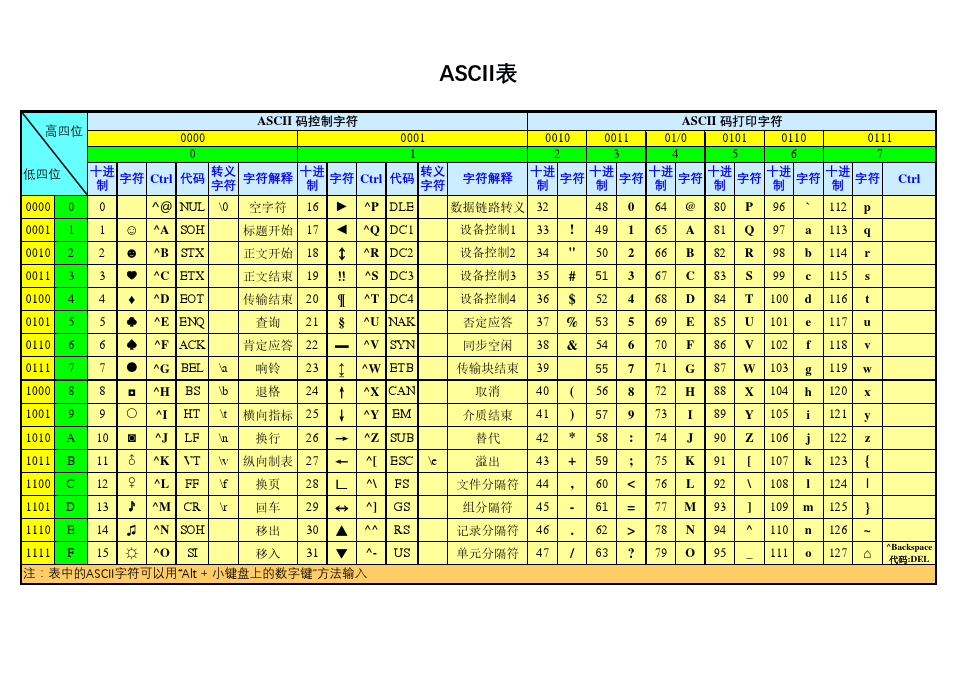
- 例如在计算机中,字符a所存储的二进制数是高四位+低四位来算的,由表可知,字符a的二进制数是01100001,字符c的二进制数就是01100011。
-
“字符集”:
英文字符— —ASCII字符集
中英文— —Unicode字符集
注意:要把字符集里面的字符表示为计算机里面的二进制数,那么我们需要确定某一种编码规则,但是基于同一个字符集,可以有多种编码方案,如:UTF-8,UTF-16,另外采用不同的编码方式,每个字符所占空间不同,考研中只需默认每个字符占1B(8bit)即可。
思维导图

存储结构
知识总览
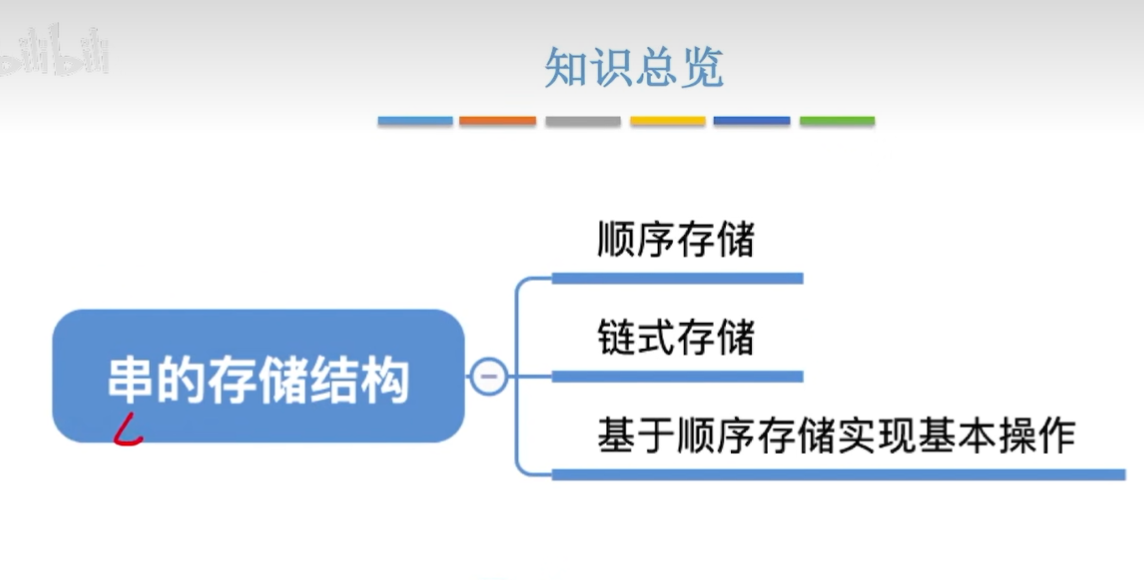
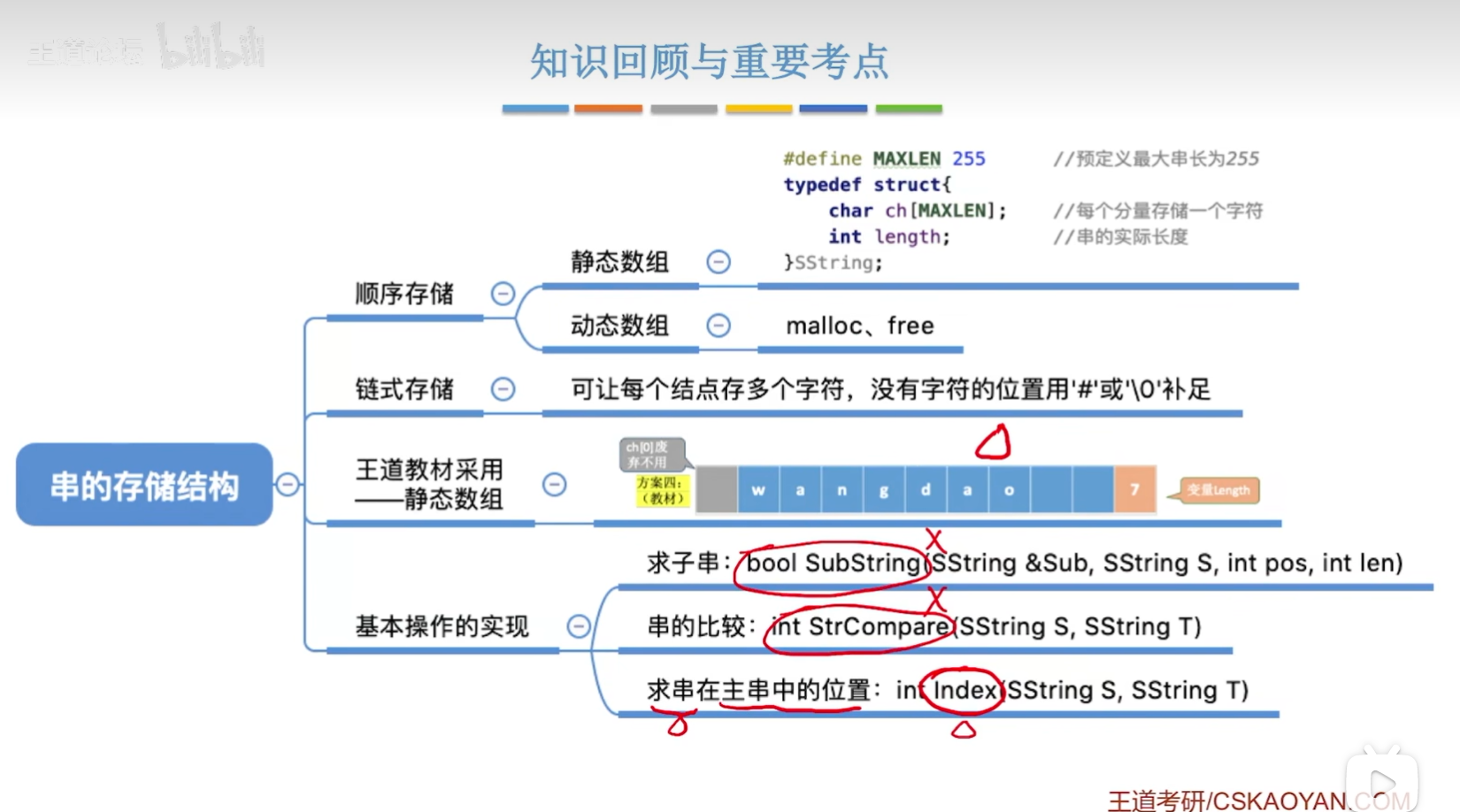
顺序存储
使用静态数组实现(定长顺序存储)串的顺序存储。
示意图如下:
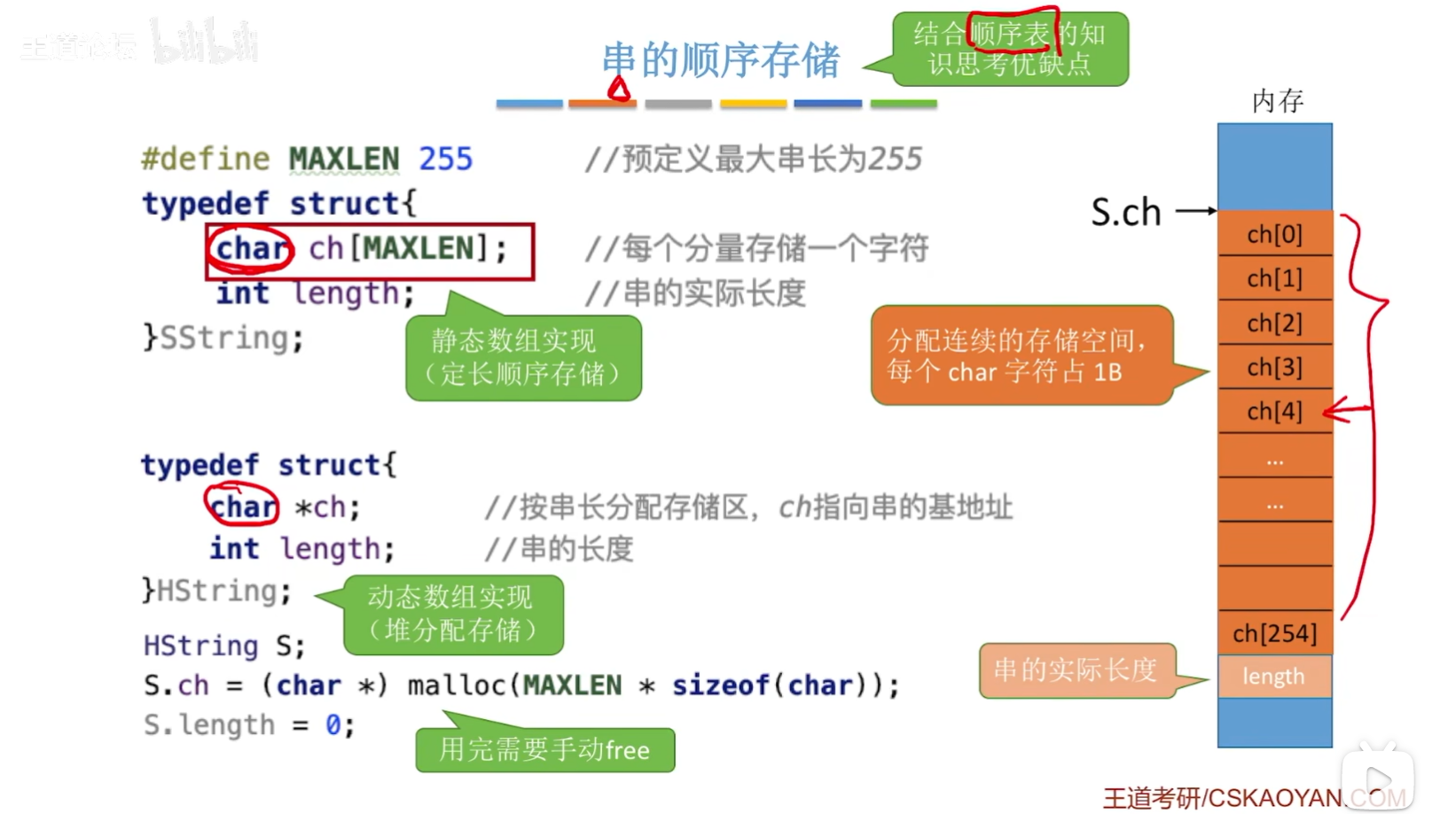
//串的顺序存储
#define MAXLEN 255//预定义最大串长为255
typedef struct
{
char ch[MAXLEN];//每个分量存储一个字符
int length;//串的实际长度
}SString;//静态数组实现(定长顺序存储)
typedef struct
{
cahr* ch;//按串长分配存储区,ch指向串的基地址
int length;//串的长度
}HString;//动态数组实现(堆分配存储)
HString S;
S.ch=(cahr*)malloc(MAXLEN*sizeof(char));
S.length=0;//用完需手动free
-
串的优缺点和顺序表的优缺点是基本上一样的,还有就是使用了malloc函数之后要手动进行free操作!
-
串的顺序存储的四种方案
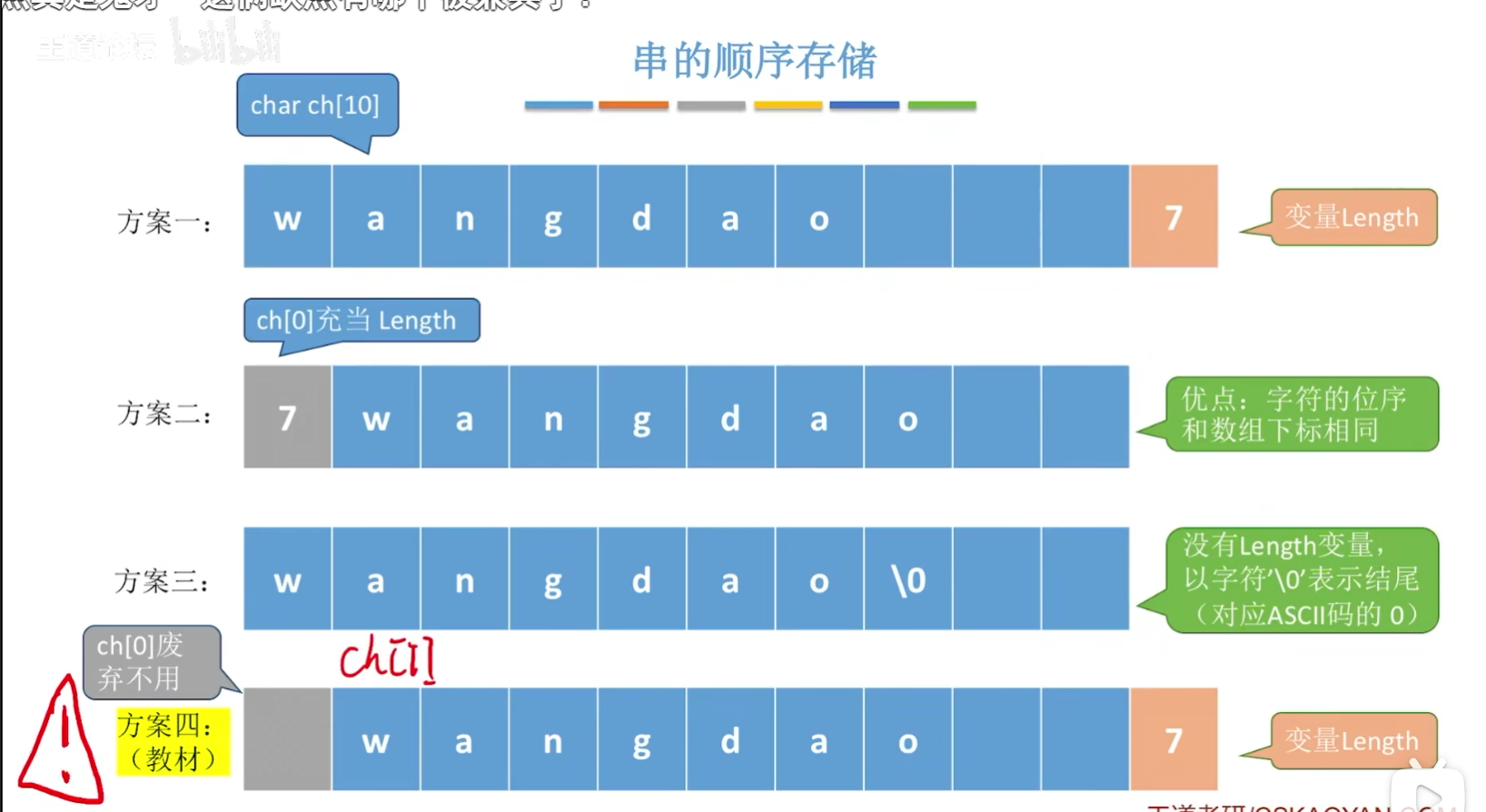
- 注意:方案一的优点就是充分的使用了数组空间,但是字符的位序和数组下标相差1;方案二的优点就是字符的位序和数组下标相同,但是缺点也很明显就是它的length(就是串的长度)是char的数据类型的,所以最大的数字就是255,也就是说最多只能表示一个串长度为255的字符串;方案三的优点就是没有设置一个length变量,以字符0结尾,这是很方便得,但是要想知道这个串得长度的话,那么就得从前往后进行遍历,这个代价是很大的;至于方案四,是目前最好得方案了,它兼具了方案一和方案二的优点,变量length是int的数据类型的,所以能够表示的长度很长,另外再把第一个数组下标为0的数据元素闲置不用,这样可以保证字符的位序和数组下标相同,这是很方便的!
链式存储
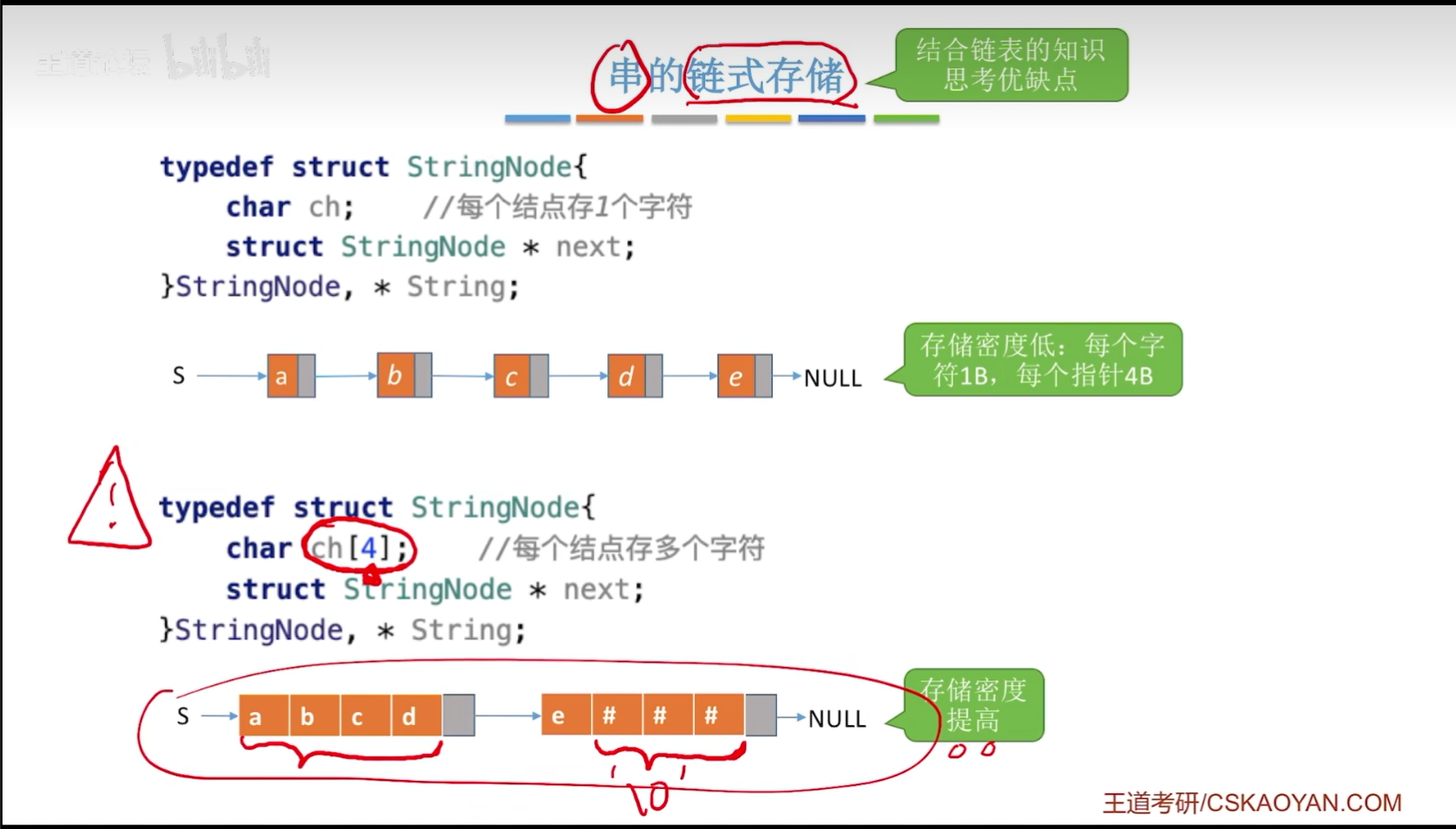
//串的链式存储
typedef struct StringNode
{
char ch;//每个节点存一个字符
struct StringNode *next;
}StringNode,*string;//存储密度低:每个字符1B,每个指针4B
typedef struct StringNode
{
char ch[4];//每个节点存多个字符
struct StringNode *next;//存储密度提高
}StringNode,*String;
- 串的链式存储的优缺点可以通过链表的知识来进行分析,如果是每一个节点只存储一个字符的话,那么就会导致存储密度低,每个字符1B,每个指针4B,所以我们可以改变节点所能存储的字符个数,如果在存储最后几个字符时,有节点没有完全存储满,那么我们就可以使用别的字符进行填充!(可以使用字符0进行填充,当然还可以有别的字符!)
基本操作的实现
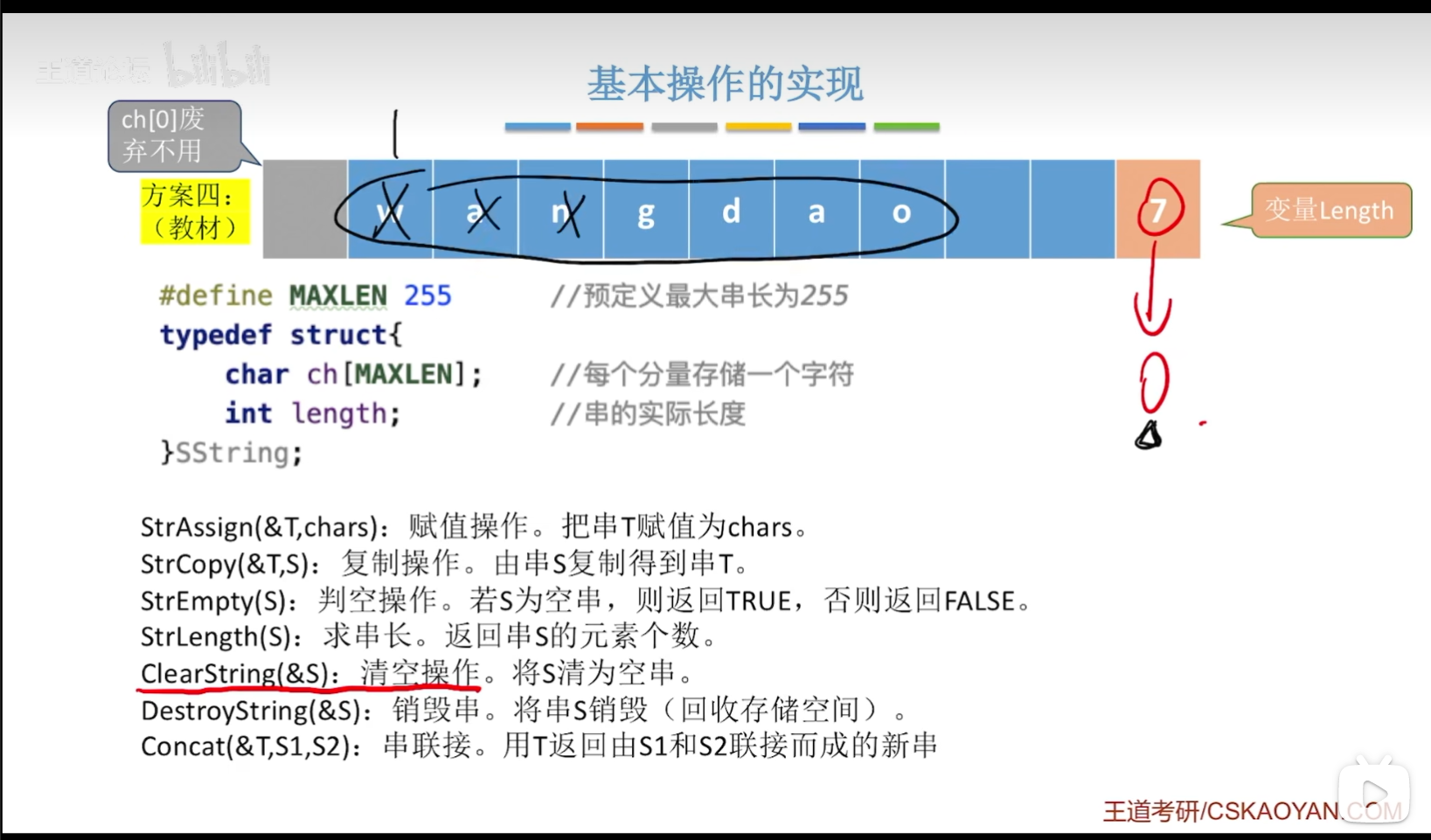
串的清空操作,只需要把串的length设为0就可以了!
-
求子串操作的实现
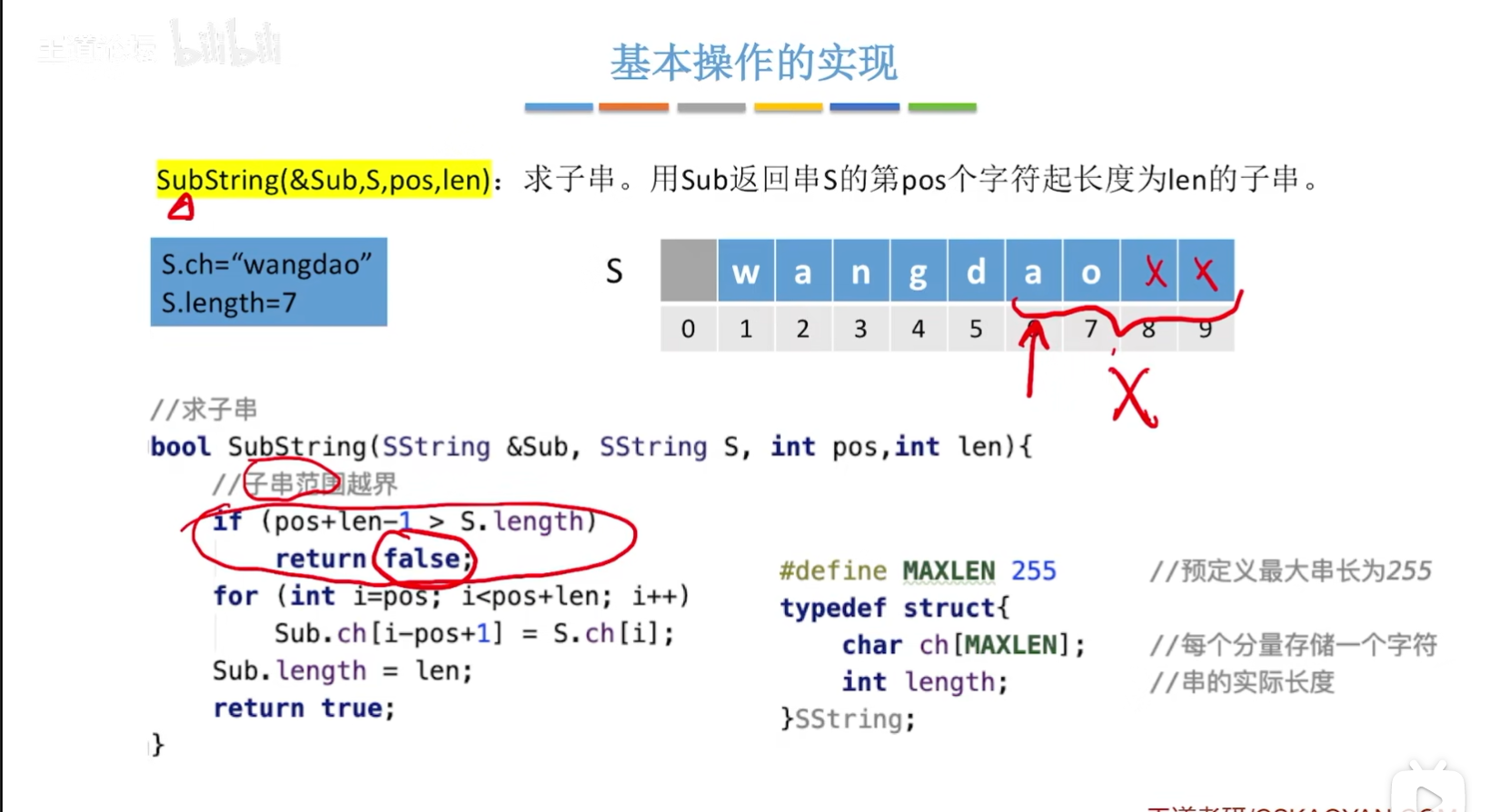
#definr MAXLEN 255//预定义最大串长为255 typedef struct { cahr ch[MAXLEN];//每个分量存储一个字符 int length;//串的实际长度 }SString; //求子串 bool SubString(SString &Sub,SString S,int pos,int len) { //子串范围越界 if(pos+len-1>S.length) return false; for(int i=pos;i<pos+len;i++) Sub.ch[i-pos+1]=S.ch[i]; Sub.length=len; return true; }理解不了,就自己带入一个实际的字符串进去运行就可以知道了!
-
比较操作的实现

//比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。
int StrCompare(SString S,SString T)
{
for(int i=1;i<S.length&&i<T.length;i++)
{
if(S.ch[i]!=T.ch[i])
return S.ch[i]-T.ch[i];
}
//扫描过的所有字符都相同,则长度长的串更大
return S.length-T.length;
}
同样地,不能很清楚地理解的话,那么就可以带入实例运行一下就可以知道了!
-
定位操作的实现

//定位操作,若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。 int Index(SString S,SString T) { int i=1,n=StrLength(S),m=StrLength(T); SString sub; while(i<=n-m+1) { SubString(sub,S,i,m);//用于暂存子串 if(StrCompare(sub,T)!=0) ++i; else return i;//返回子串在主串中的位置 } return 0;//S中不存在与T相等的子串 }注意:上图中的while循环里面为什么是i<=n-m+1呢?——它是一个计算公式,以上图中的例子为例,那么n=7,m=3,那么就是i<=5;使用了SubString函数操作后,你自己可以数一下,当i处于最大值的时候,最后刚好取到dao三个字符,这样避免了串范围越界的问题;然后在进行一个一个地进行比较即可实现定位操作!(但是所消耗的时间复杂度较高!)
思维导图
朴素模式匹配算法
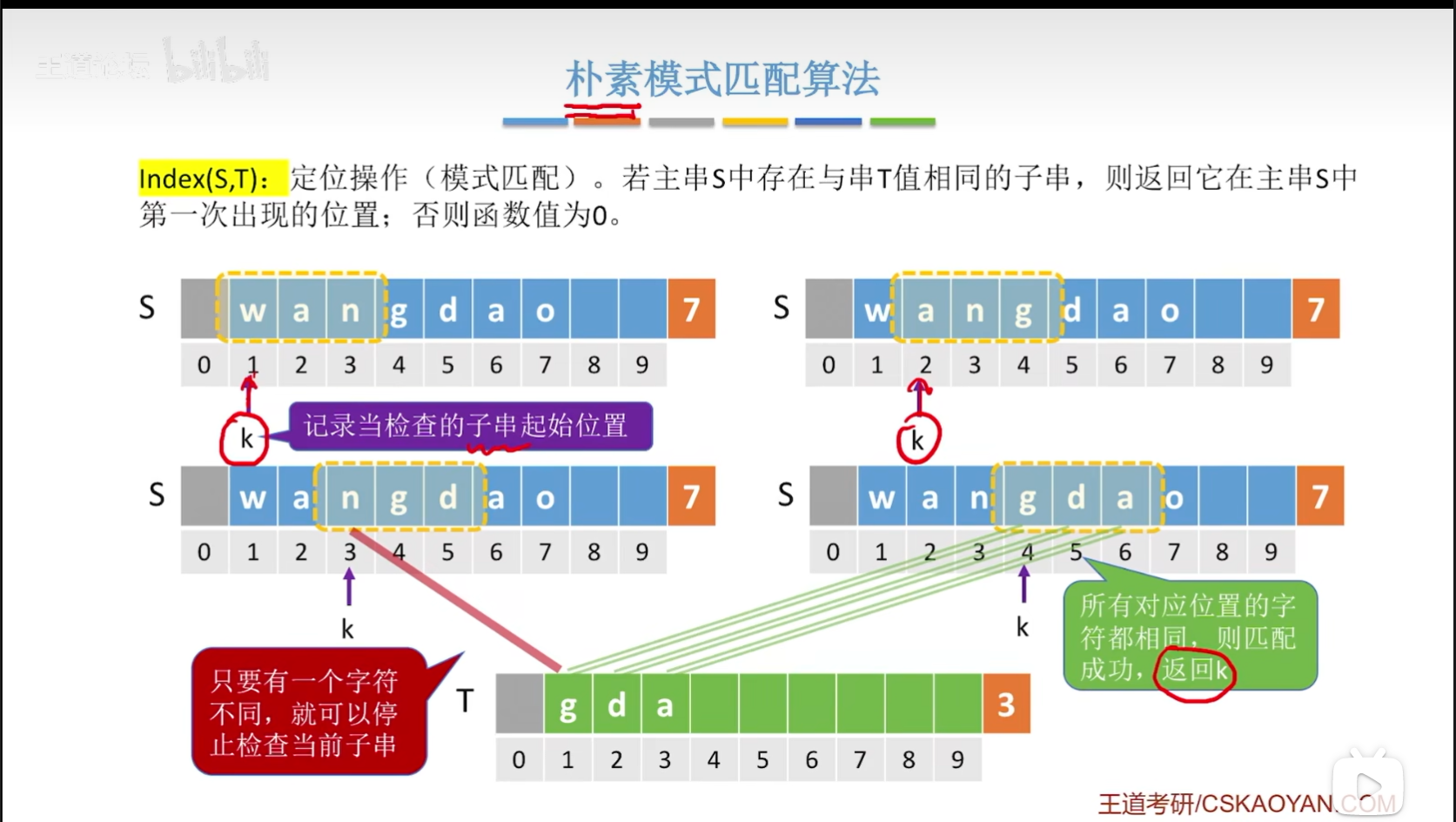
串的模式匹配:在主串中找到与模式串(想尝试在主串中找到的串,未必存在)相同的子串(一定是主串中所存在的才叫“子串”),并返回其所在位置。(与定位操作有一点像)
-
使用基本操作实现模式匹配
-
朴素模式匹配算法

-
这里的逻辑实现很好理解,自己假设一个实际的例子就可以了,但是还是有一种特殊情况就是T是aoo,但是主串里面最后是ao,并没有完整的aoo,这个时候在将其带入代码运行一遍之后,你就会发现while里面的判断条件是多么地神奇!
-
课本代码实现
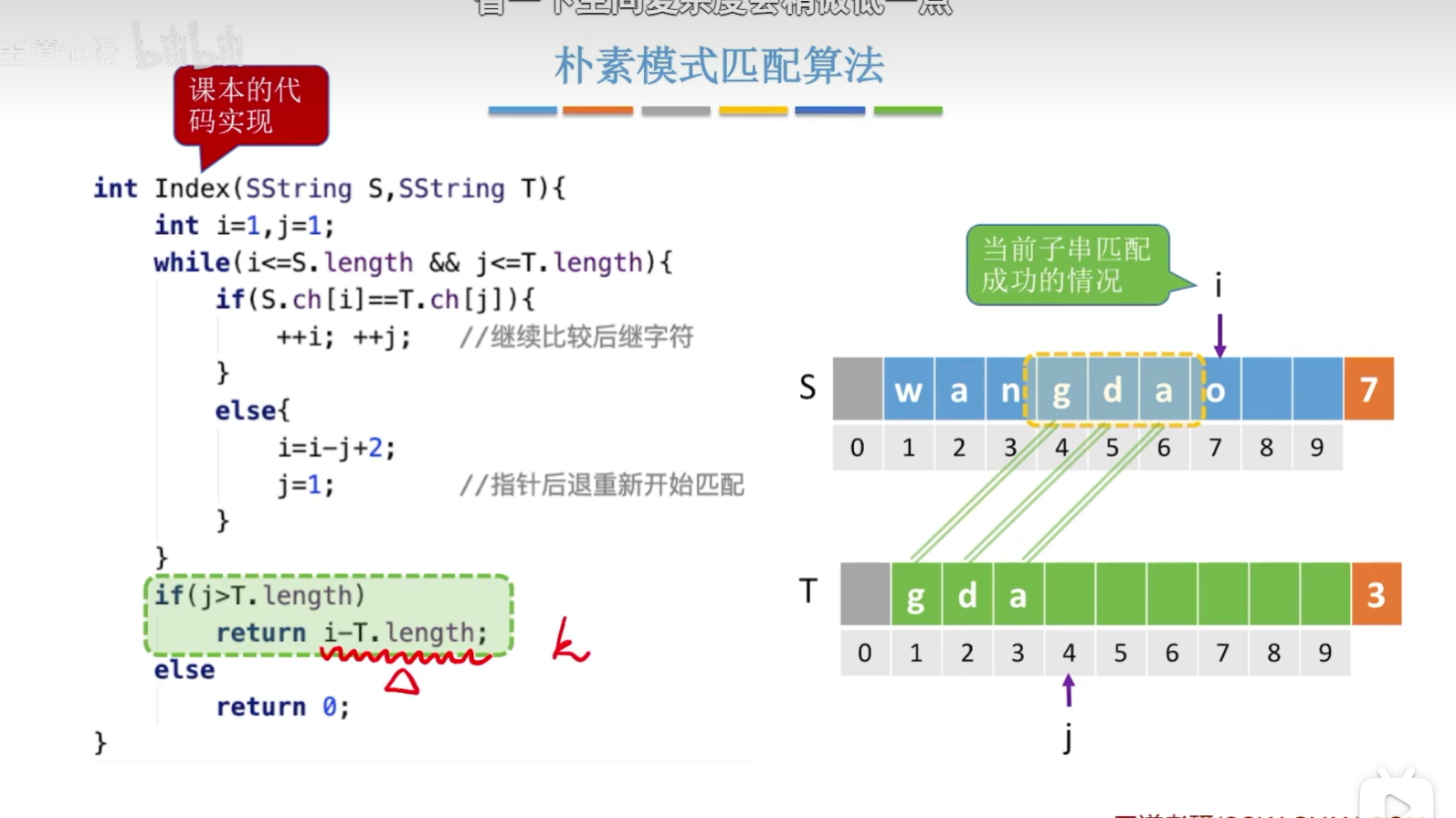
同样地,这里不懂也可以带入具体的实例进行理解!
-
-
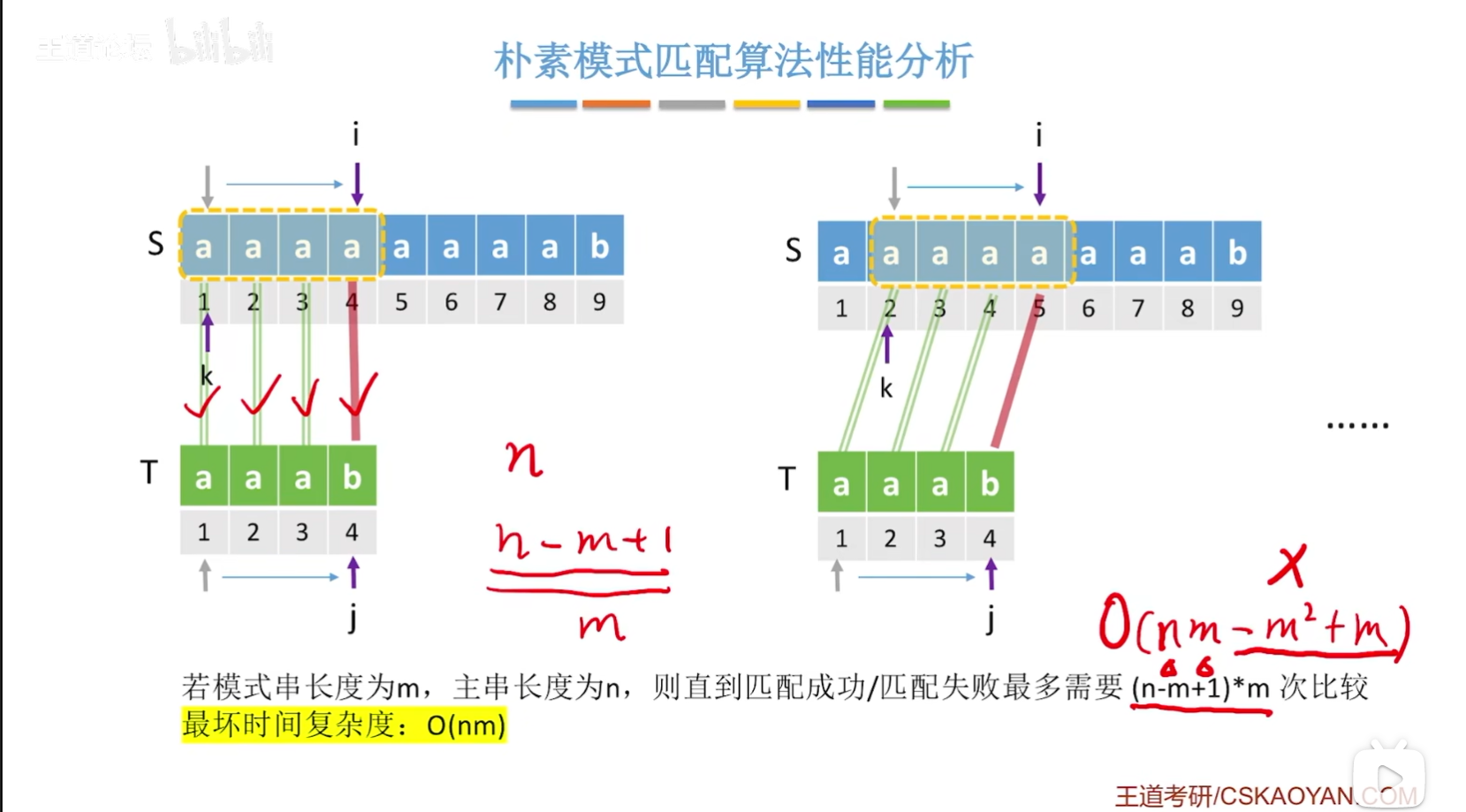
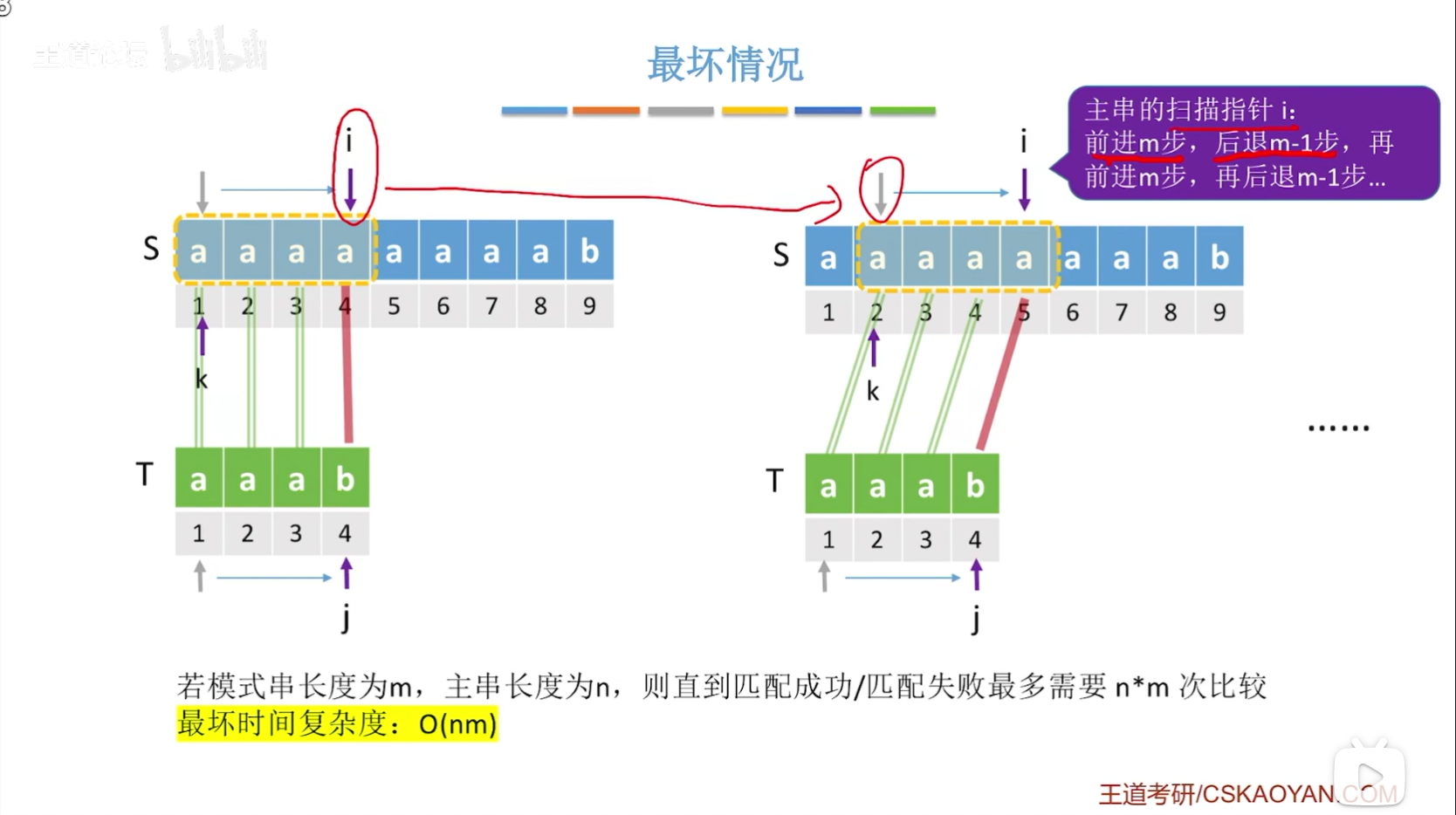
朴素模式算法匹配性能分析
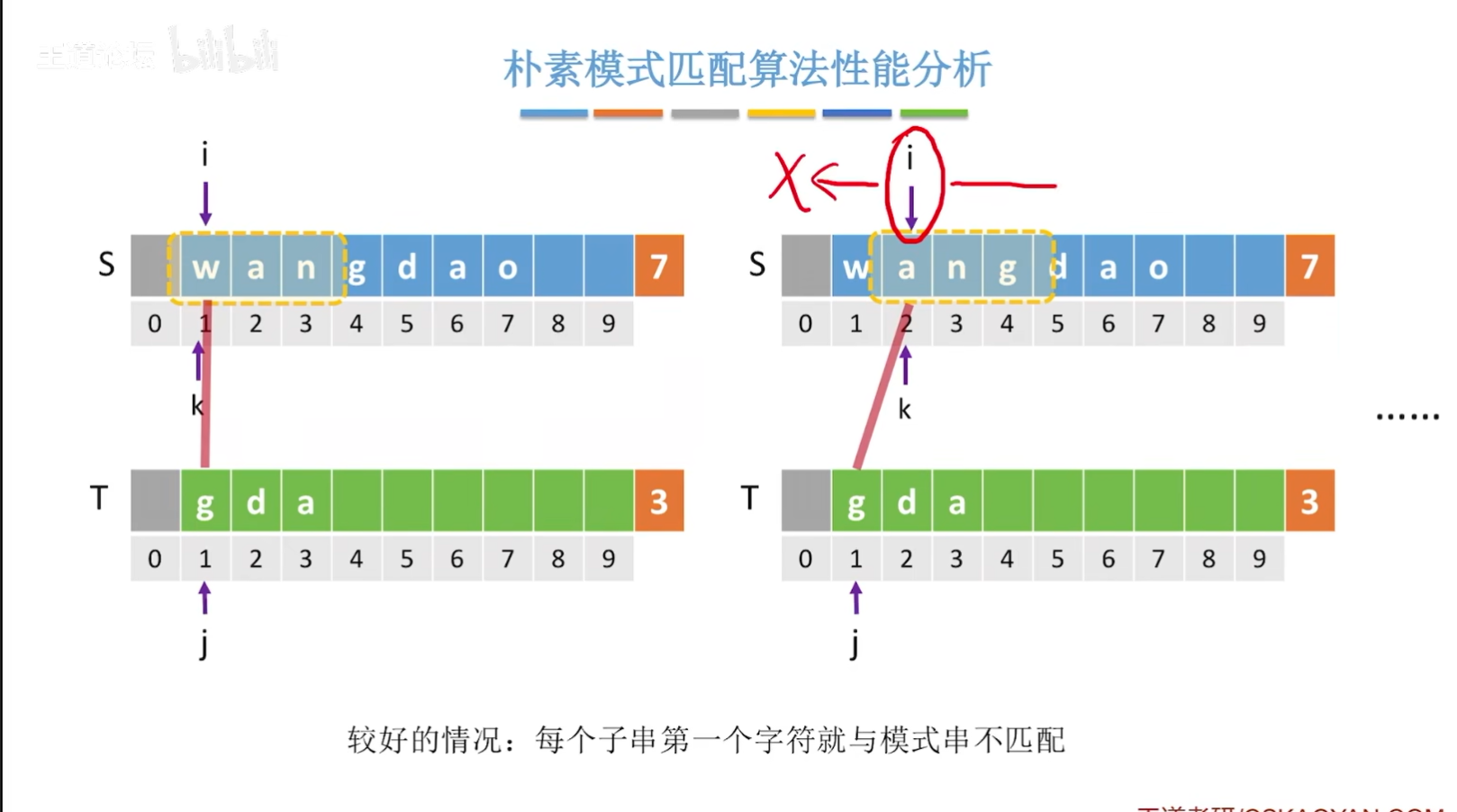
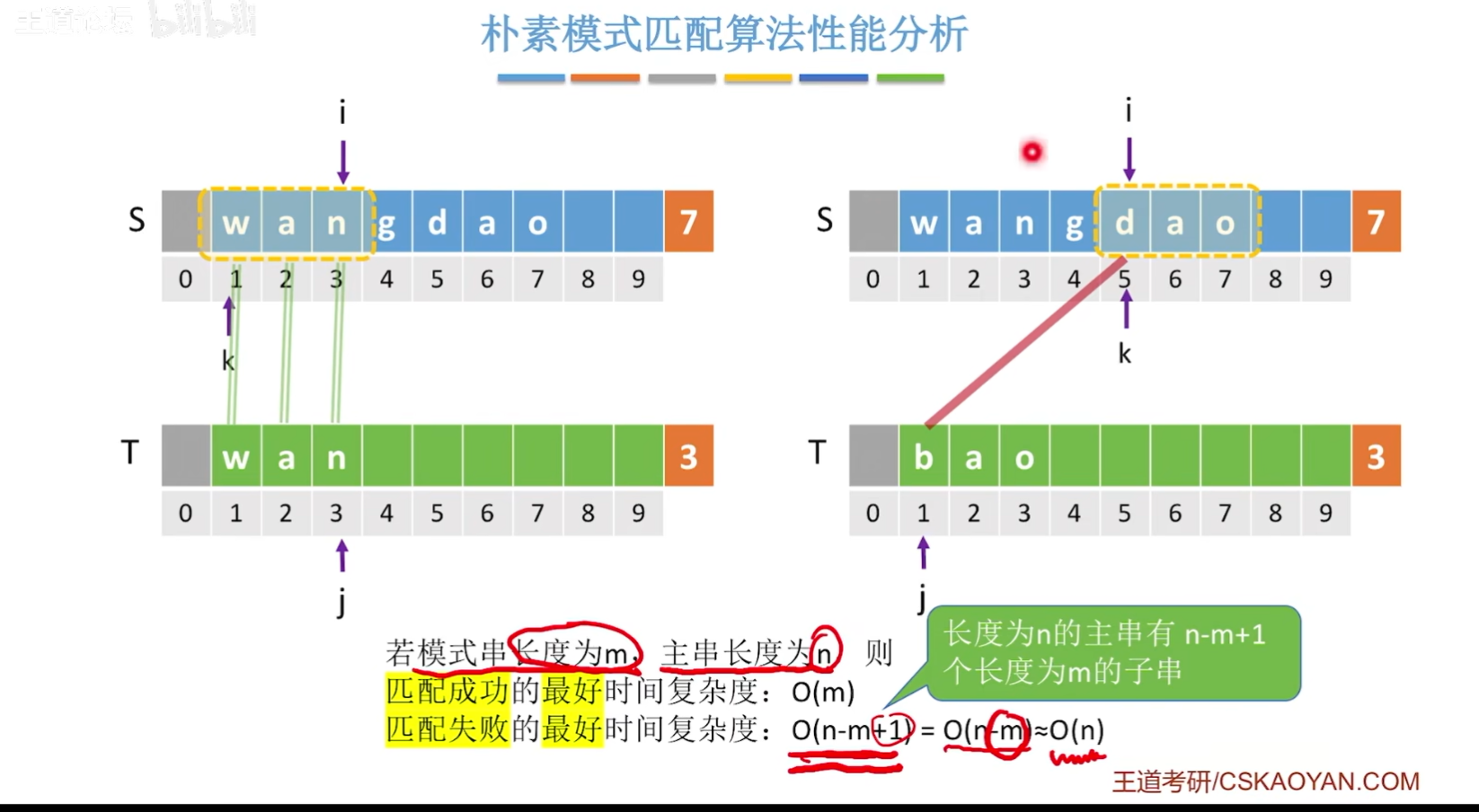
上图中,之所在最后把m省略,是因为在众多的应用场景中,n的值是要远远地大于m的值的!
知识回顾

kmp算法
-
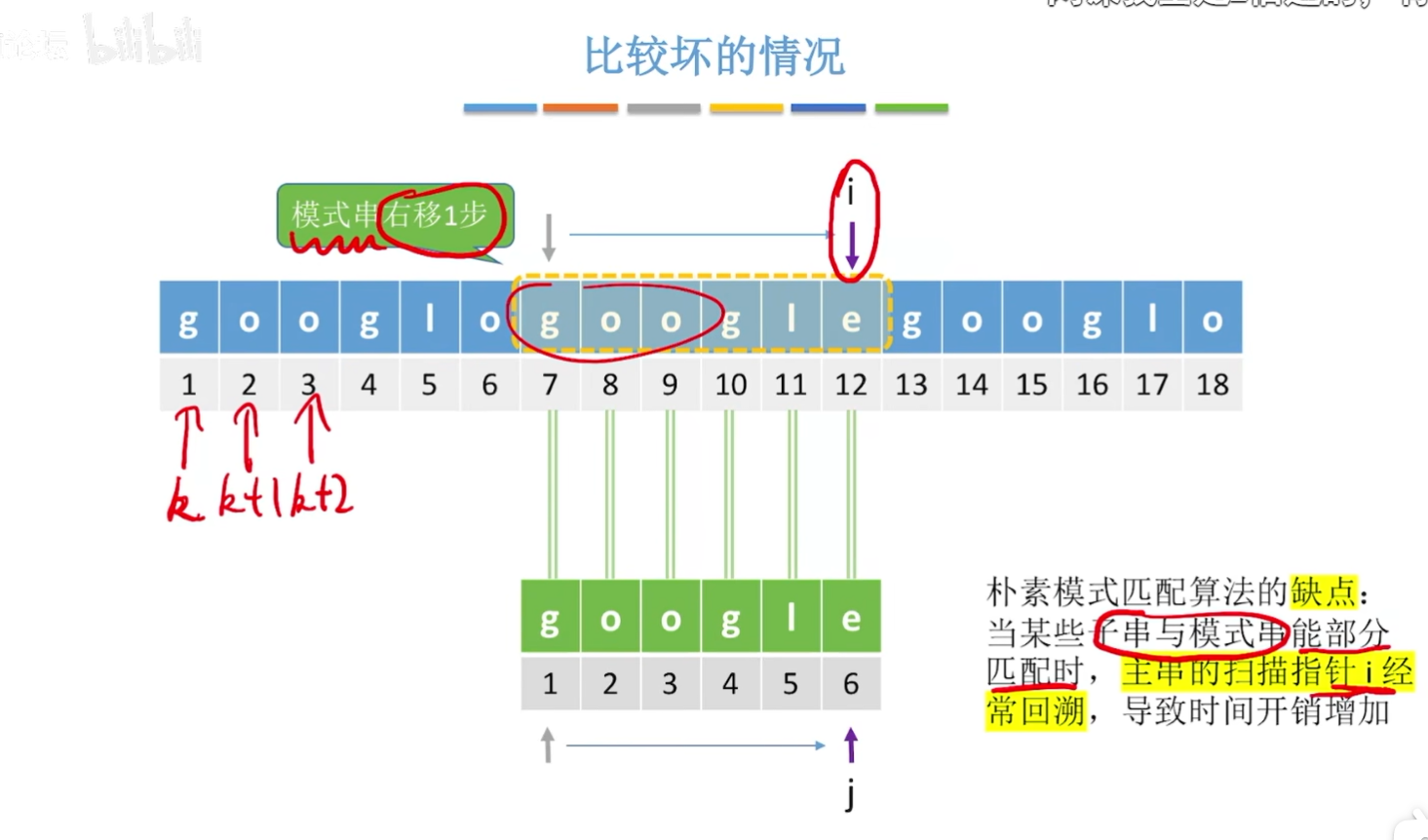
朴素模式匹配算法的缺点:当某些子串与模式串能部分匹配时,主串的扫描指针i经常回溯,导致时间开销增加
-
解决主串回溯问题:
改进思路:主串指针不回溯,只有模式串指针回溯。
kmp算法实现原理即代码实现
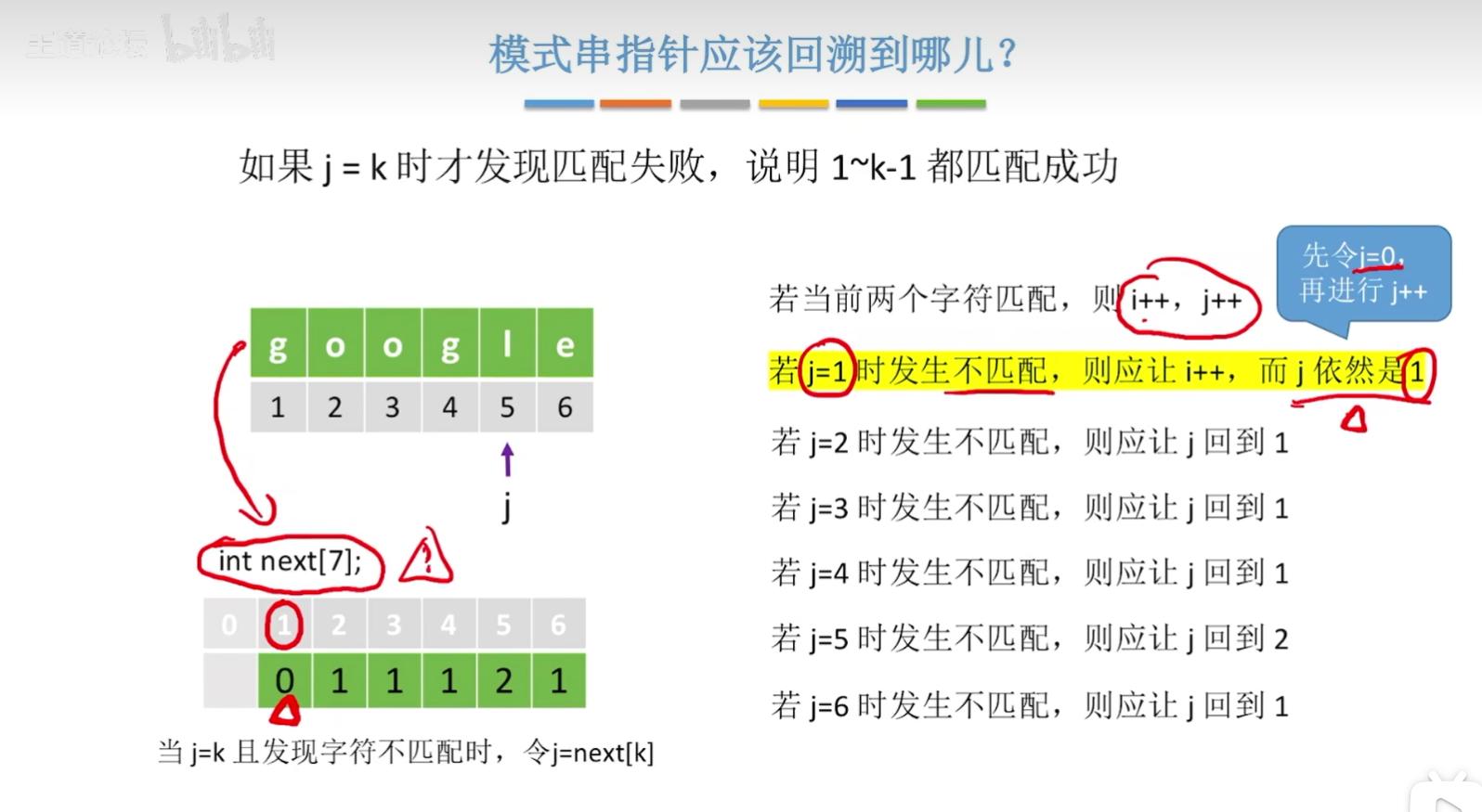
- 以上图片当中右边的匹配分析是基于模式串是google来进行实现的!
- 代码部分
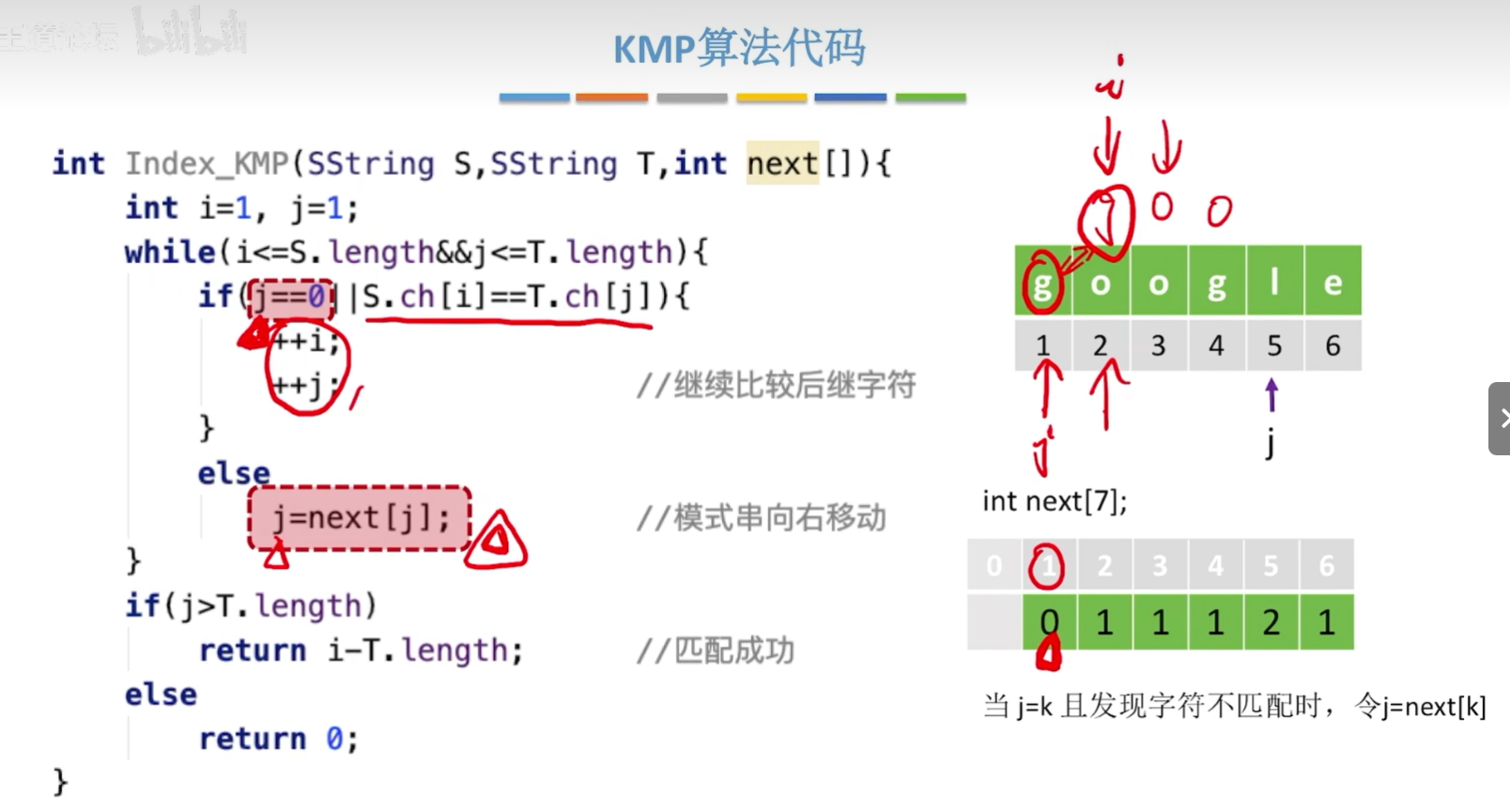
//KMP算法代码
int Index_KMP(SString S,SString T,int next[])
{
int i=1,j=1;
while(i<=S.length&&j<=T.length)
{
if(j==0||S.ch[i]==T.ch[j])
{
++i;
++j;//继续比较后续字符
}
else
j=next[j];//模式串向后移动
}
if(j>T.length)
return i-T.length;//匹配成功
else
return 0;
}
- kmp算法与朴素模式匹配算法最大的区别就是多了一个next数组。还有就是逻辑复杂难以理解,其实就是定义一个next数组,然后在发现字符匹配不一样的时候,使用next数组将j转到指定的位置即可!(其中next数组要由模式串求出!)
- 注意:之所以让j==0,是因为如果第一个字符就匹配失败了,那么j就会就会变成next[1],也就是0,那么如果此时第一个字符匹配成功的话,那么i和j的值就各自加1,所以就又可以进行比较了,这就是为什么把next[1]设为0的原因。
求模式串的next数组(手算)
-
next数组:当模式串的第j个字符匹配失败时,令模式串跳到next[j]再进行匹配。
-
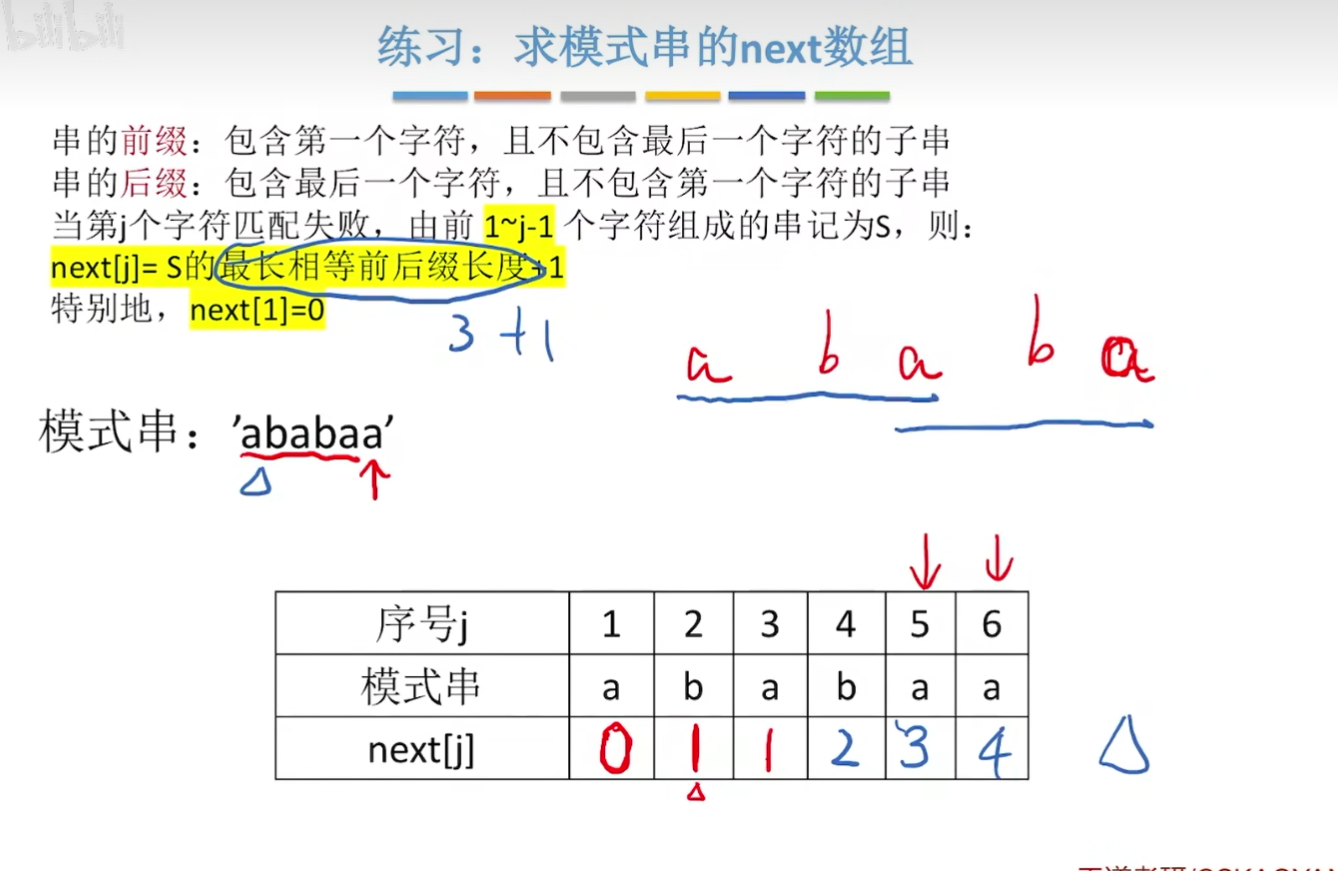
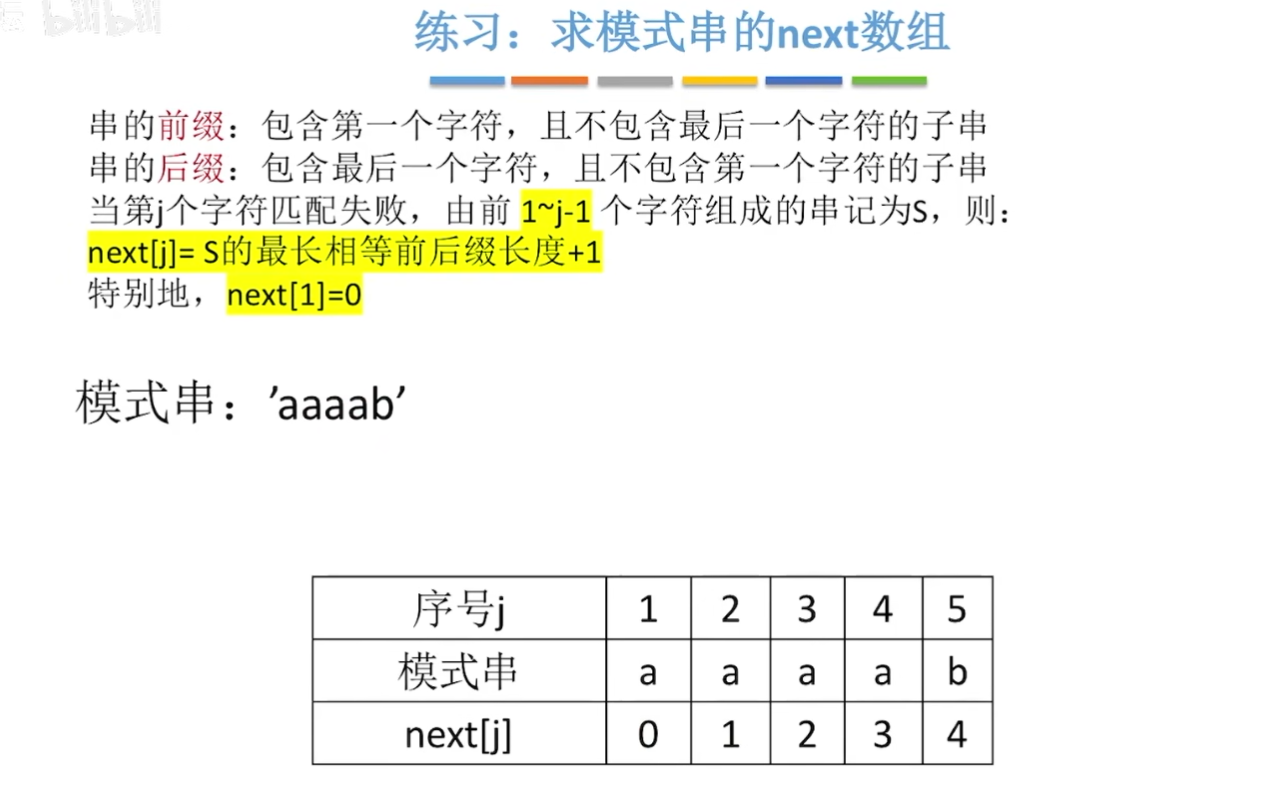
串的前缀:包含第一个字符,且不包含最后一个字符的子串。
-
串的后缀:包含最后一个字符,且不包含第一个字符的子串。
-
当第j个字符匹配失败,由前1~j-1个字符组成的串记为S,则:
next[j]=S的最长相等前后缀长度+1
特别地,next[1]=0
-
注意:以后不管遇到什么样的模式串,它的next[1]和next[2]一定是0和1。
-
练习1:
-
练习2:
-
下图是王道书上的求模式串的next数组的计算公式
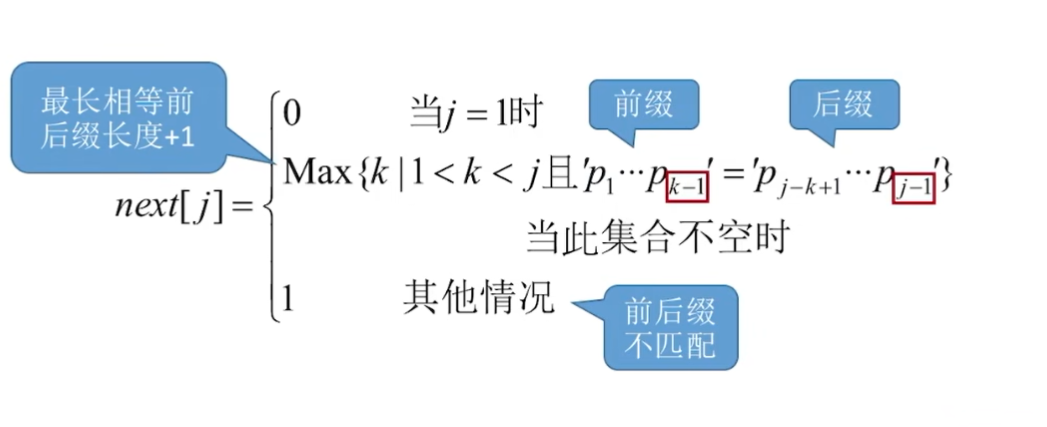
- 注意:其实实现方式和上面的串的前缀和串的后缀方法是一样的,只不过是公式复杂了一点,但是原理还是一样的!
-
求模式串T的next数组与kmp算法代码实现

- 至于这里面的代码正确性还不知道,可以自己去试一下就知道了。(求模式串T的next数组的代码可能有点错误,自己去分析应该能够找到正确的解决办法。
知识回顾

- 注意:next数组的手算要记住结论就是:next[1]=0和next[2]=1
kmp算法存在的问题
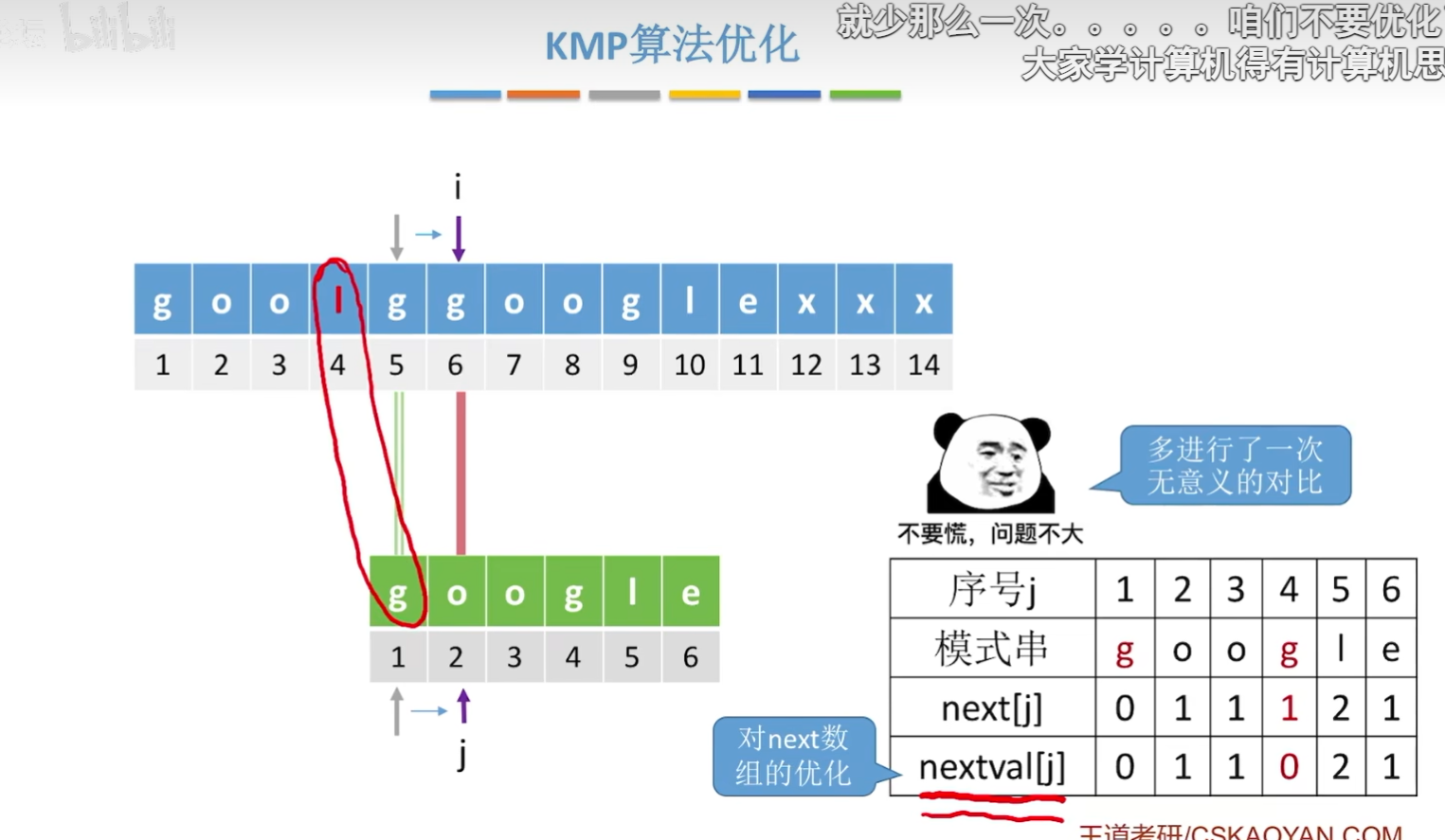
-
如上图中就反映了kmp算法所存在的问题就是无意义地多进行了一次对比,本来明明知道i为4的时候所指向的字符并不是g,但是还是让i为4所指向的字符与模式串里面的第一个g进行了对比,那么这就进行了一次无意义的对比,所以解决办法就是新加上一个nextval[j]数组!
-
next数组转换成nextval数组的方法如下:
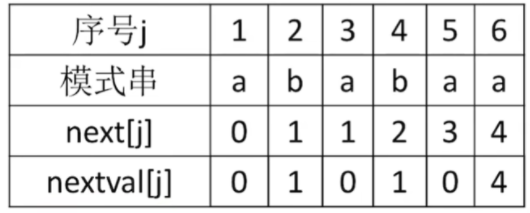
-
注意:首先nextval[1]肯定还是0,从j=2开始,它的next[2]是1,那么就回到序号1所对应的模式串,如果这时候序号2所对应的模式串与序号1所对应的模式串相等的话,那么就把nextval[j]设定为与nextval[1]的值一样,如果所对应的模式串不相等的话,那么nextval[j]的值就和next[j]一样,依次类推,就可以得到所有的nextval值了!
知识回顾
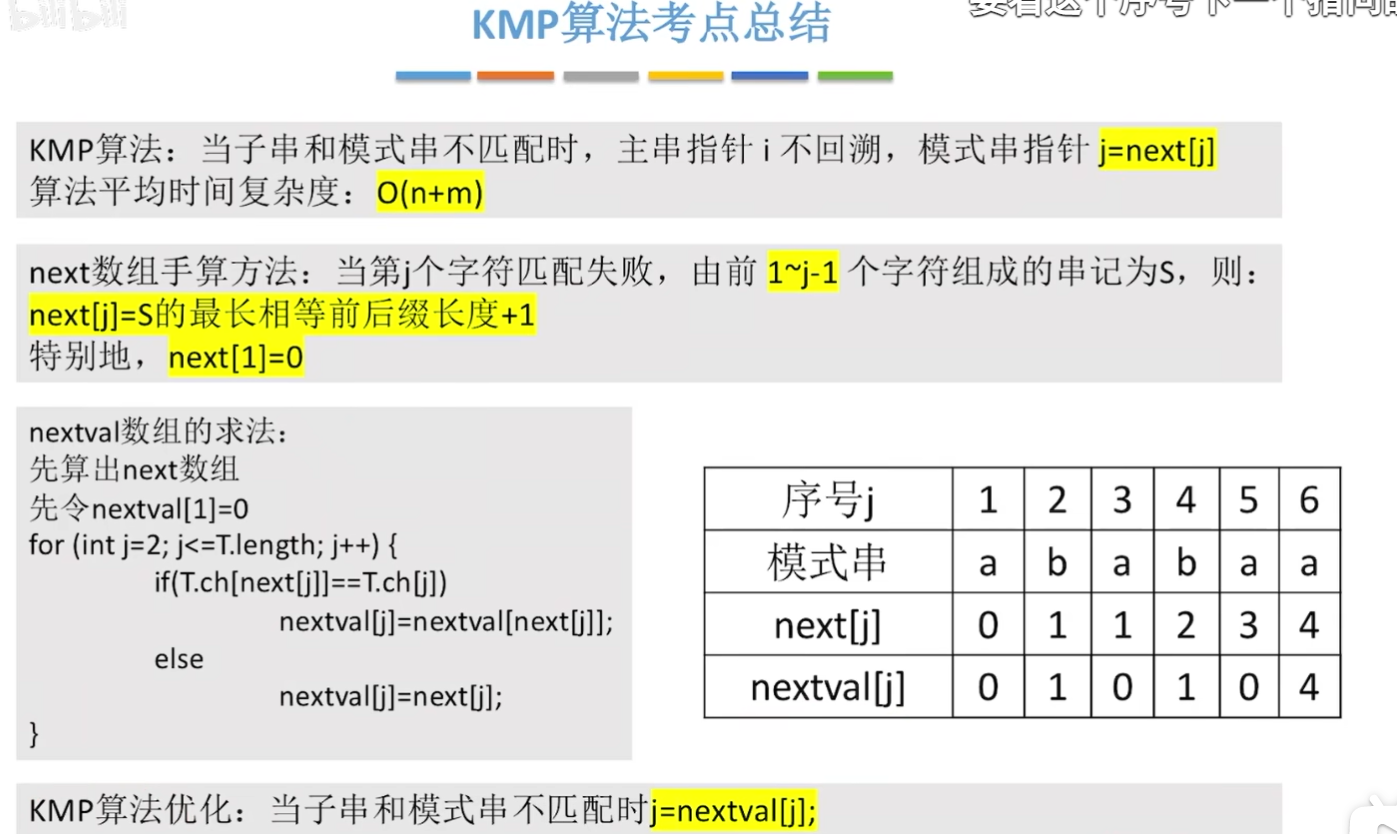















 9307
9307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









