






1.urllib.request模块
1.1版本
- Python2:urllib2 、 urllib
- Python3:将urllib2 和urllib合并成 urllib.request
1.2常用方法
- urllib.request.urlopen(“网址”) 作用:向网站发送一个请求并获取响应
- 读取相应对象的内容
- 字节流:response.read() —> 容易产生乱码
- 字符串:response.read().decode(‘utf-8’)
- urllib.request.Request(“网址”,headers = “字典”) urlopen()不支持User-Agent
import urllib.request
import urllib.parse
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'}
# 1.创建请求对象
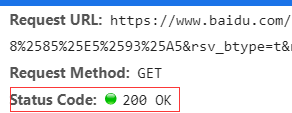
url = 'https://www.baidu.com'
req = urllib.request.Request(url, headers=headers)
# 2.获取相应对象
reponse = urllib.request.urlopen(req)
# 3.读取相应对象的内容
html = reponse.read().decode('utf-8')
print(html)
1.3响应对象
- read()读取服务器相应的内容
- getcode()返回HTTP的响应码
import urllib.request
import urllib.parse
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'}
# 1.创建请求对象
url = 'https://www.baidu.com'
req = urllib.request.Request(url, headers=headers)
# 2.获取相应对象
reponse = urllib.request.urlopen(req)
# 3.读取相应对象的内容
html = reponse.read().decode('utf-8')
# print(html)
print(reponse.getcode())
print(reponse.geturl())
- geturl()返回实际数据的 URL (防止重定向问题)

2.urllib.Parse 模块
2.1 常用方法
- urlencode (字典)
- quote (字符串)
import urllib.parse
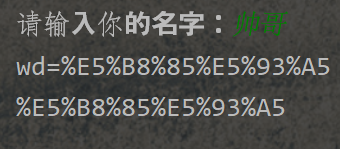
# https://www.baidu.com/s?wd=%E5%B8%85%E5%93%A5
name = {'wd': '帅哥'}
str_name = input('请输入你的名字:')
name = urllib.parse.urlencode(name)
name1 = urllib.parse.quote(str_name)
print(name)
print(name1)
3.请求方式
- GET 特点 :查询参数在URL地址中显示
- POST
- 在 Request 方法中添加data参数
urllib.request.Request(url,data=data,headers=headers)
-data :表单数据以bytes类型提交,不能是str
- 获取的最终结果是json类型的字符串List item
import json
import urllib.request
import urllib.parse
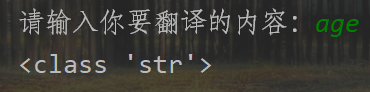
key = input('请输入你要翻译的内容:')
data = {
'i': key,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15884212635606',
'sign': 'eeb02de2fa6597eee3feee887c5bdd71',
'ts': '1588421263560',
'bv': 'f52186f8c76a0fbf1baf7e6da04928ea',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'
}
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = urllib.parse.urlencode(data)
# data 必须以字节类型提交 不能是str
# 将data 转化成字节
data = bytes(data, 'utf-8')
req = urllib.request.Request(url, data=data, headers=headers)
reponse = urllib.request.urlopen(req)
html = reponse.read().decode('utf-8')
# 使用json模块的json.loads()将json字符串转化成字典
# html = json.loads(html)
# html = html['translateResult'][0][0]['tgt']
print(type(html))
4.request 模块
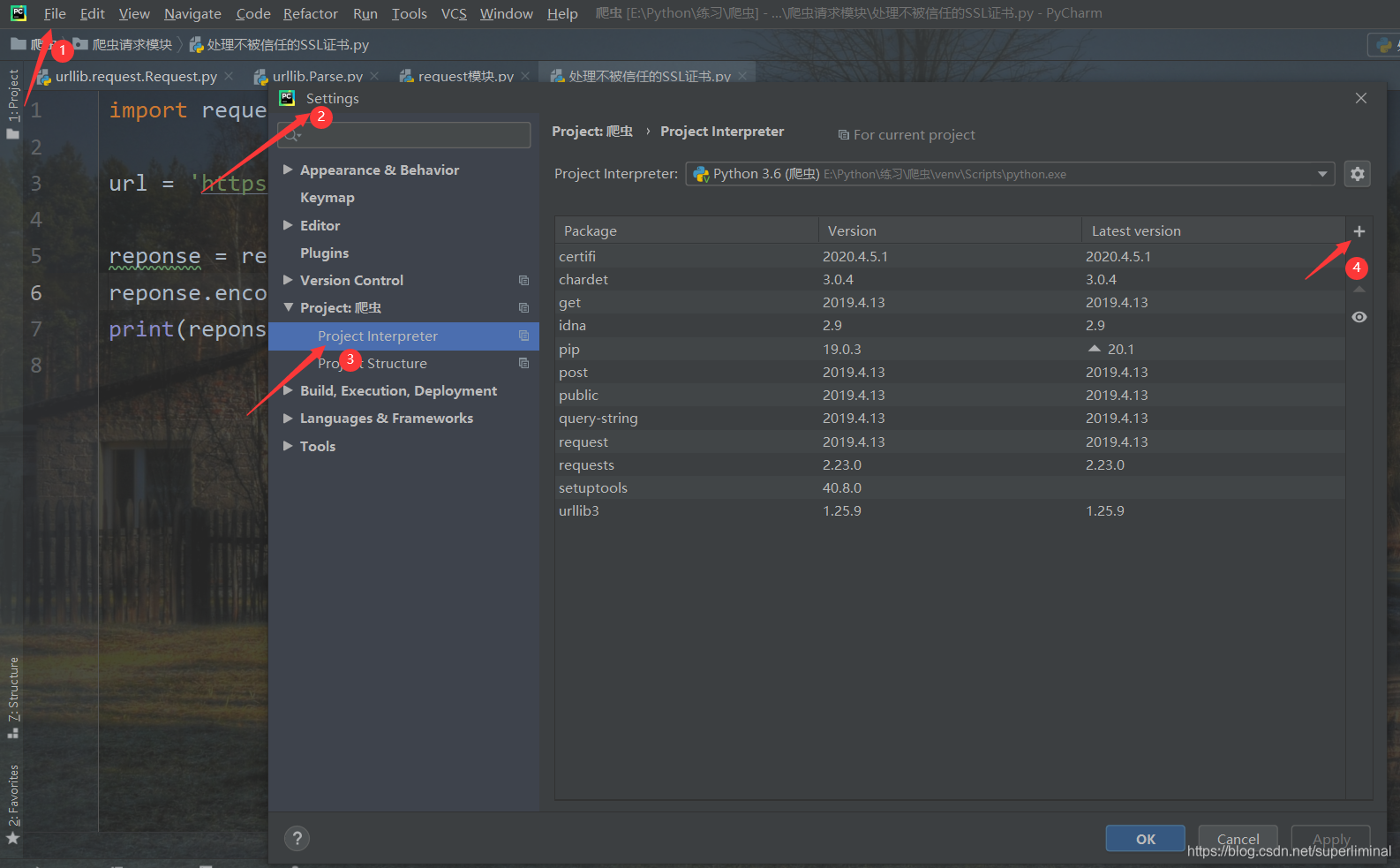
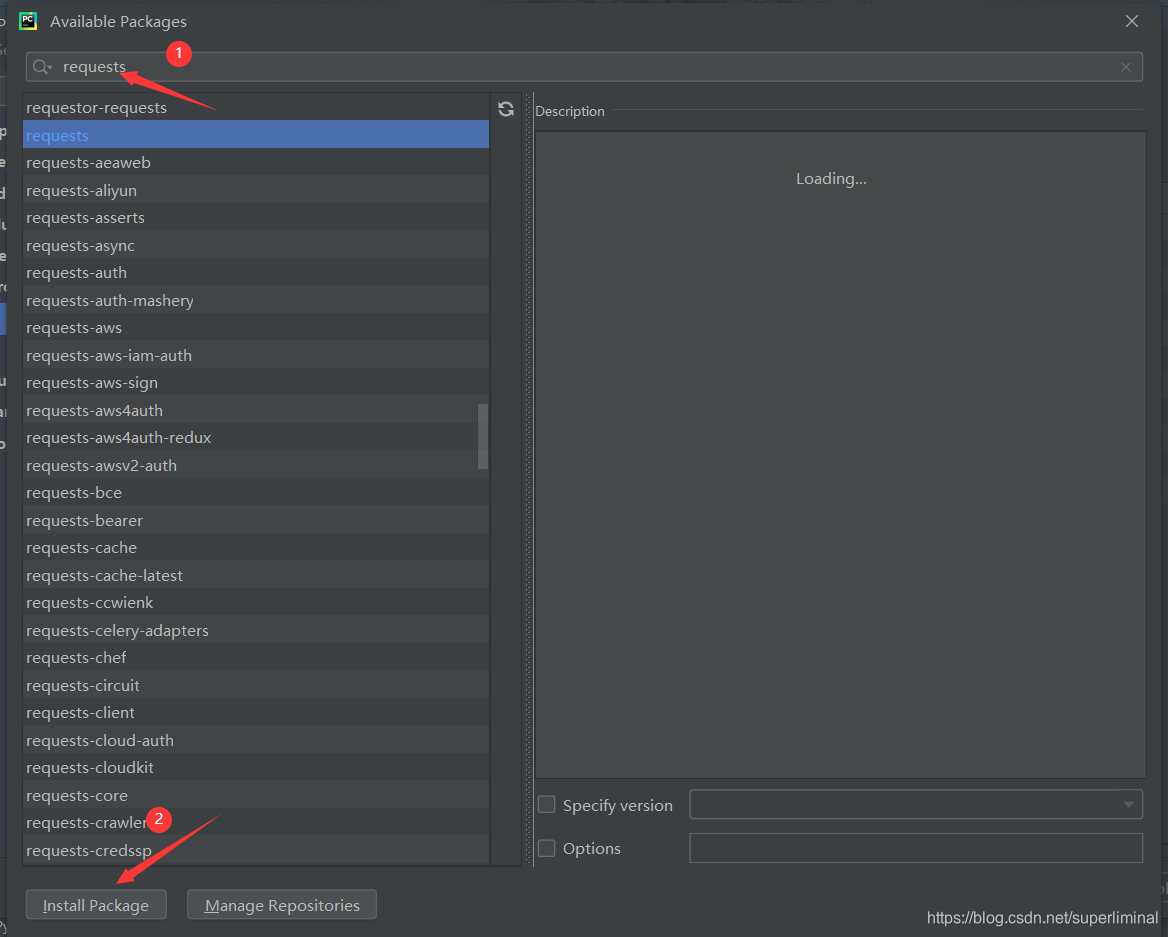
4.1 安装
- pip install request
- 在pycharm中安装
4.2 request 常用方法
- request.get(网址)
import requests
r = requests.get('https://www.baidu.com')
print(r)

- get方法可以传入一个关键字params
import requests
#
# r = requests.get('https://www.baidu.com')
#
# print(r)
payload = {'key': 'values', 'keys': 'value'}
r = requests.get('https://www.baidu.com', params=payload)
print(r.url)

4.3 响应对象reponse的方法
-
reponse.text返回 unicode 格式的数据(str) ,一般会有乱码出现
-
reponse.content 返回字节流数据(二进制)
-
request.content.decode(‘utf-8’)手动解码
-
reponse.url 返回 url
import requests
url = 'https://www.baidu.com/'
reponse = requests.get(url)
print(reponse.url)
# https://www.baidu.com/
- reponse.encoding=’‘编码格式’ ,可以解决reponse.text的乱码情况
4.4 request模块发送post请求
4.5 request设置代理
- 使用 requests 模块设置代理只需在 get/post 请求中proxies参数就可以了
- 代理网站:
- 西刺免费代理IP:http://www.xicidaili.com/
- 快代理:http://www.kuaidaili.com/
- 代理云:http://www.dailiyun.com/
import requests
proxy = {
'https': '221.229.252.98:8080'
}
url = 'https://www.httpbin.org/ip'
reponse = requests.get(url, proxies=proxy)
print(reponse.text)
4.6 cookie
cookie 通过用户在客户端记录的信息确定用户身份
HTTP 是一种无连接协议,客户端和服务器交互交互仅仅限于请求/响应过程,结束后断开,下次请求时,服务器会认为是一个新的客户端,为了维护他们之间的连接,让服务器知道这是前一个用户发起的请求,必须在一个地方保存用户的信息
4.7 session
session:通过服务端记录的身份确定用户身份,这里的这个session指的是一个会话
4.8 处理不信任的SSL证书
SSL 证书是一种数字证书,类似于驾驶证、护照和营业执照的电子副本。因为配置在服务器上 ,也叫做SSL服务器证书。SSL 证书是遵守SSL协议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务器身份验证和数据传输加密功能
import requests
url = 'https://inv-veri.chinatax.gov.cn/'
reponse = requests.get(url, verify=False)
reponse.encoding = 'utf-8' # 解决乱码
print(reponse.text)
5.requests 模块源码分析















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









