







结合网络爬虫的技术,把数据获取到写入到CSV的文件中,其实利用爬虫的技术可以获取到很多的数据,某些时候仅仅是好玩,真正进行数据分析并且让数据可以商业化产生价值体系,是一个很高的境界。
这里以豆瓣电影为案例,获取豆瓣电影中正在上映的电影,并且把这些数据写入到CSV的文件中,主要是电影名称, 电影海报的链接地址和电影评分。这里使用到的库是lxml,lxml是一款高性能的Python HTML/XML解析器,安装命令为:
pip3 install lxml
使用它的时候主要会使用到xpath的语法(当然这里不会详细的介绍xpath)。首先见要获取的数据,如下图所示:
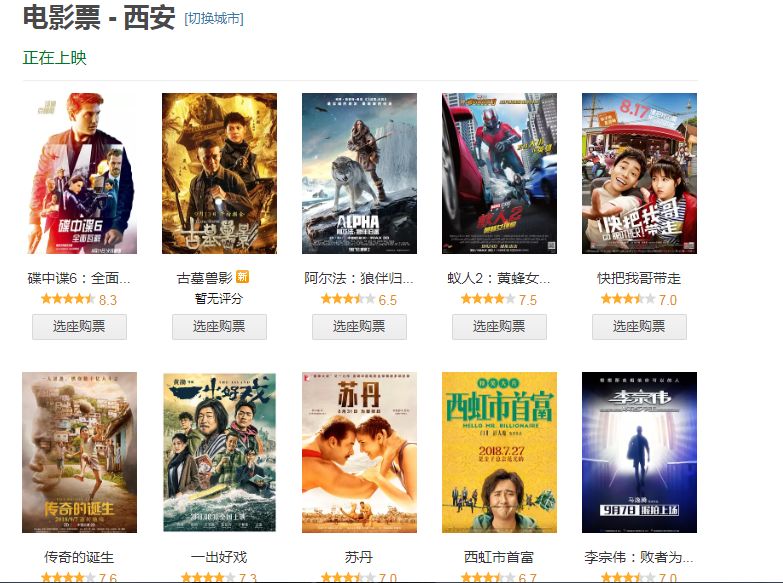
链接地址是:https://movie.douban.com/cinema/nowplaying/xian/,那么首先我们利用requests的库来对它获取请求,然后获取到文件的内容,实现的代码为:
下来我们使用lxml对text进行解析,解析如果对lxml熟悉相对来说是比较简单的,实现的代码是:

打开浏览器的调试模式,鼠标具体定位要获取的数据,这里是获取所有的数据,依据源码可以看到它是在div下面,同时这个div的class是lists,见下图所示:
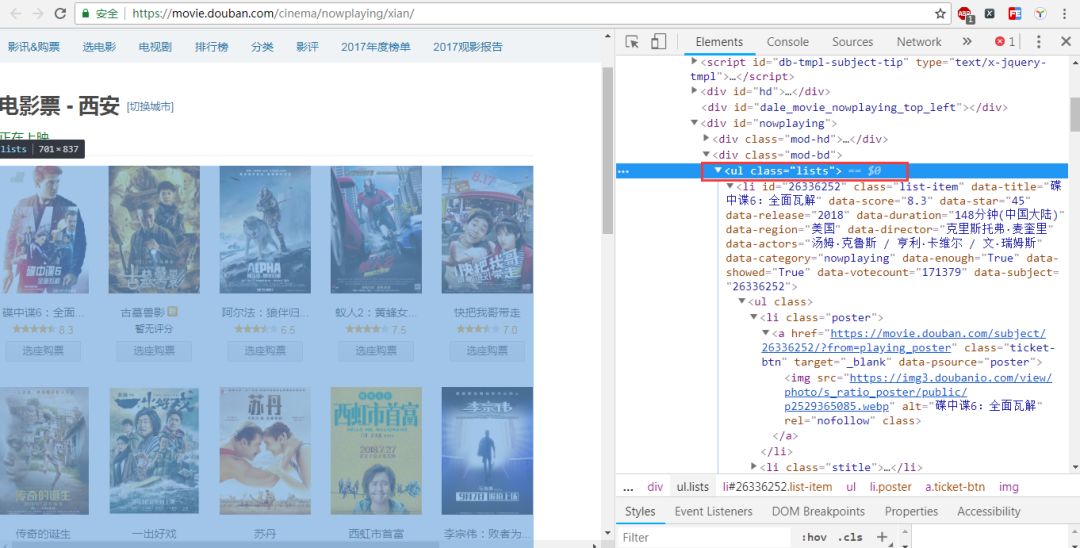
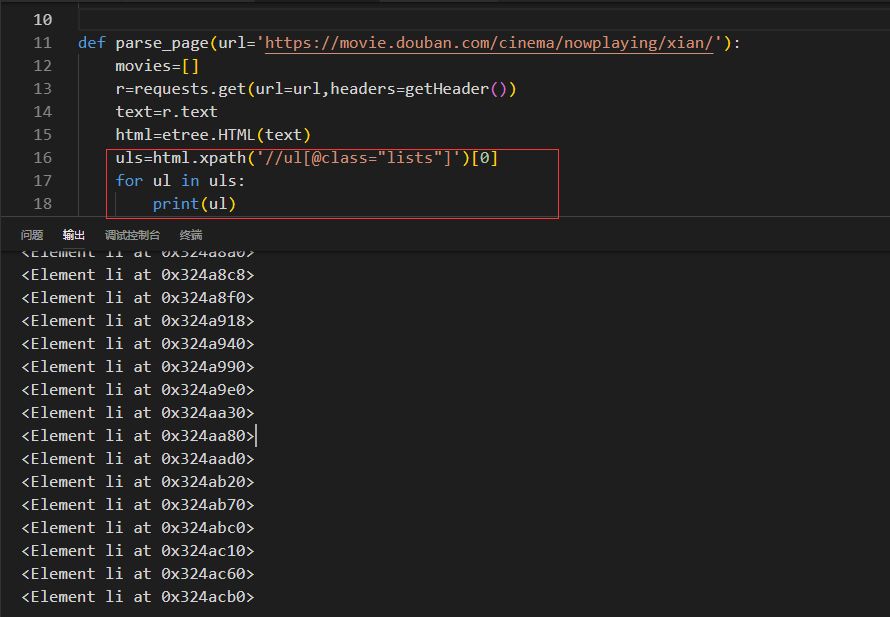
那么就先获取到所有的uls,实现的代码为:

然后我们对uls进行循环,输出的对象都是Element,那么我们就需要在这些Element对象中获取电影名称,海报链接地址,和评分,见循环输出的内容:
首先来获取电影海报的链接地址,见海报链接地址在源码中的位置截图:
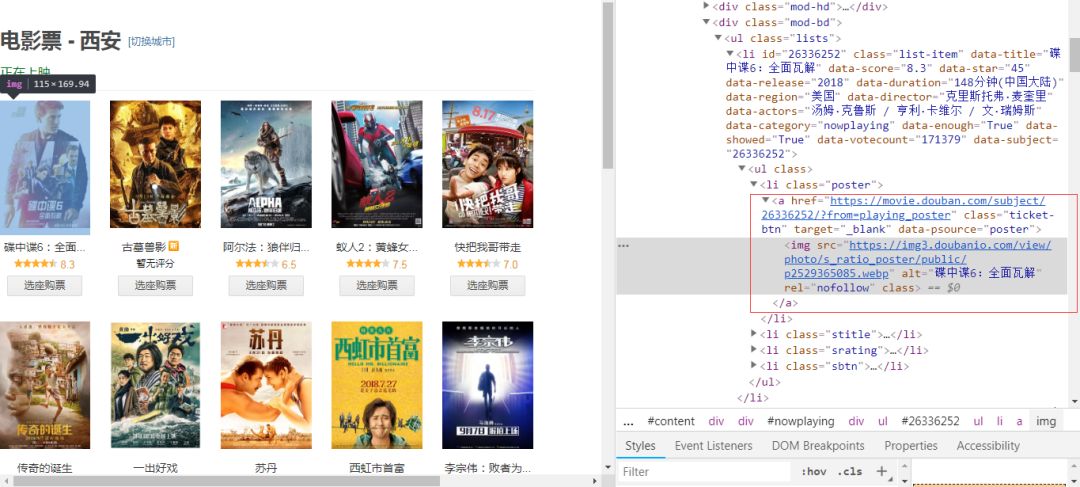
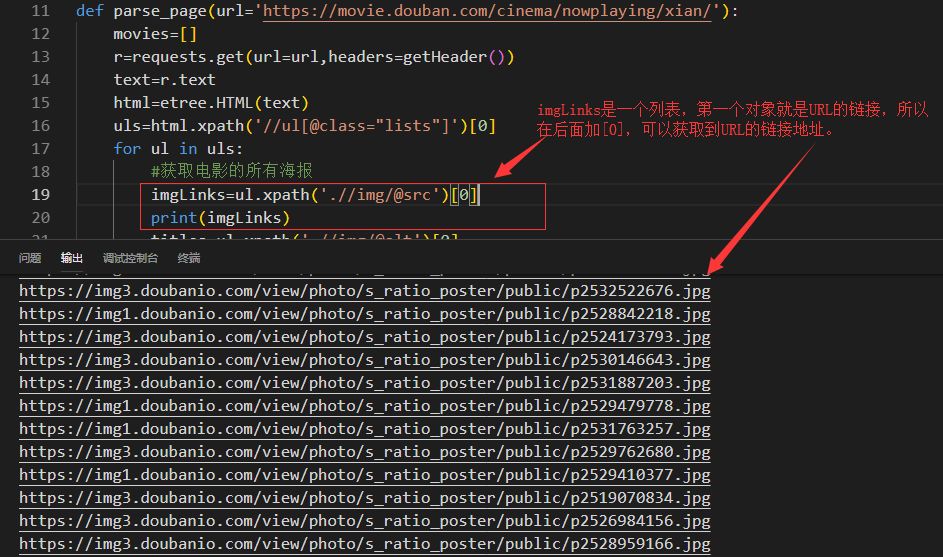
依据上图中可以看到,海报的链接地址和电影名称实在a标签下的img标签中,先来获取海报链接地址,它的xpath是.//a/@href,具体见实现的代码和输出:
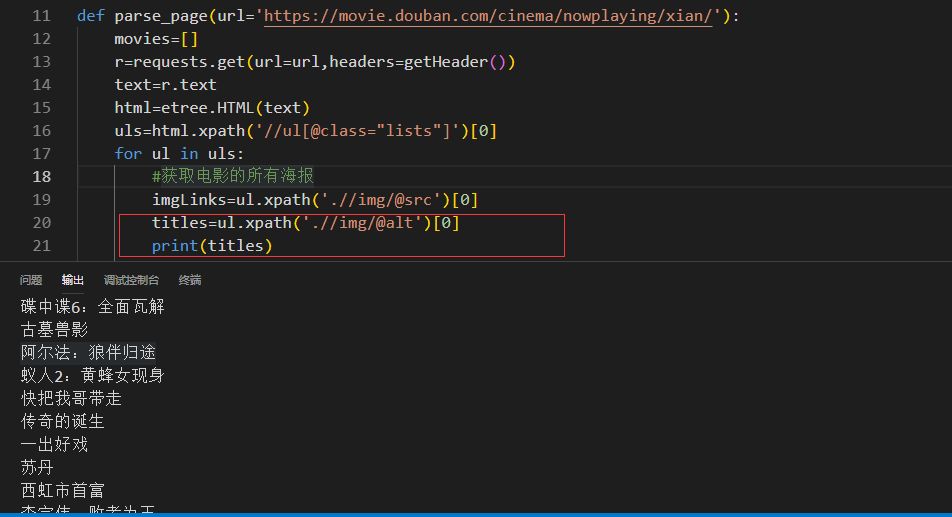
下来来获取电影的名称,它也是在img标签中的alt属性中,它的xpath是.//a/img/@alt,见获取的源码:
最后获取平评分,来看评分在源码中的位置,见下图所示:
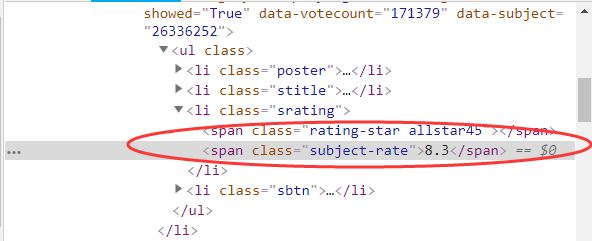
依据上图可以看到评分是在li标签下的span标签中并且span标签的class属性是subject-rate,那么它的xpath是.//span[@class="subject-rate"]/text(),见获取评分的数据代码:
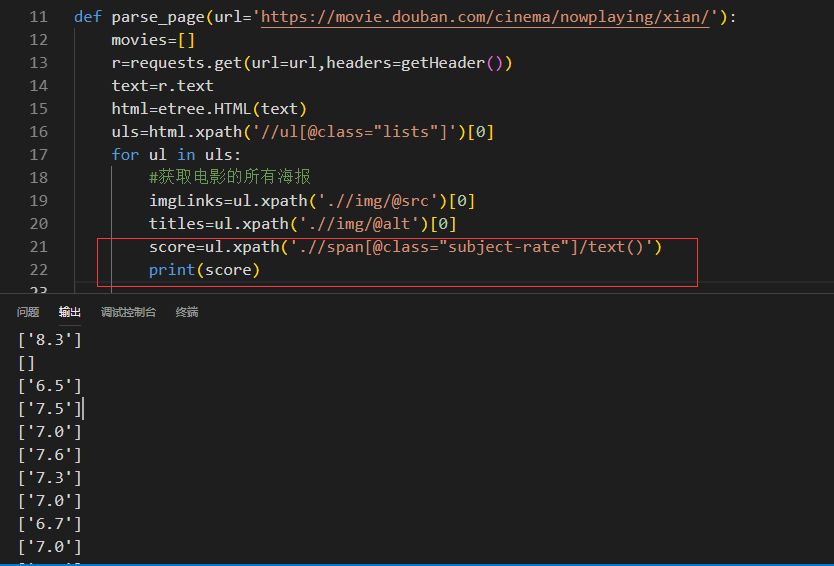
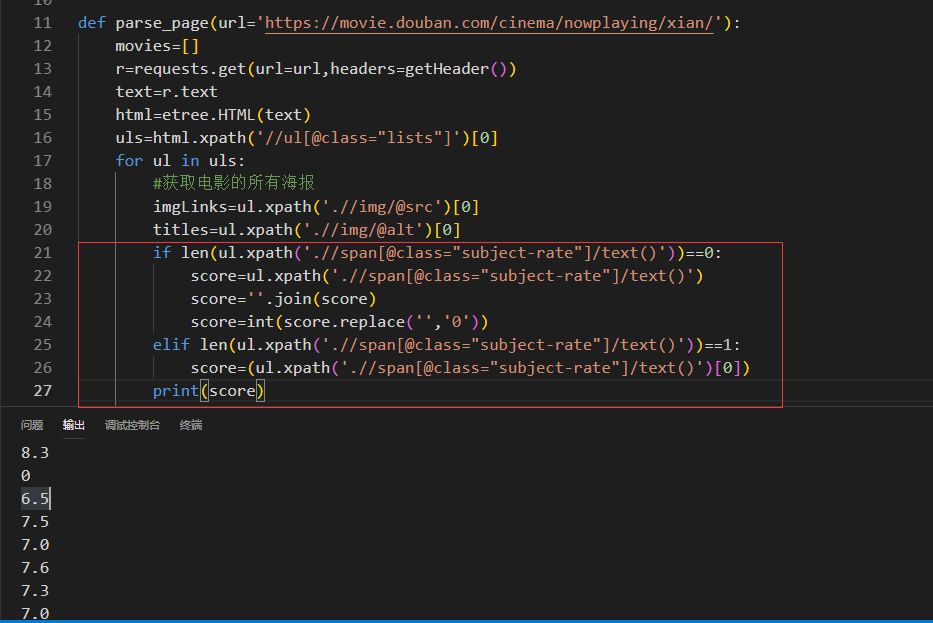
可以看到某些电影的评分是空,同时评分应该是整型,那么就需要做处理和判断,首先判断,如果是[],替换成0,如果是['8.3']这样的,把它转成整型,但是它是列表类型,那么就是列表转为字符串再转为整型,见实现的源码和输出的评分结果:
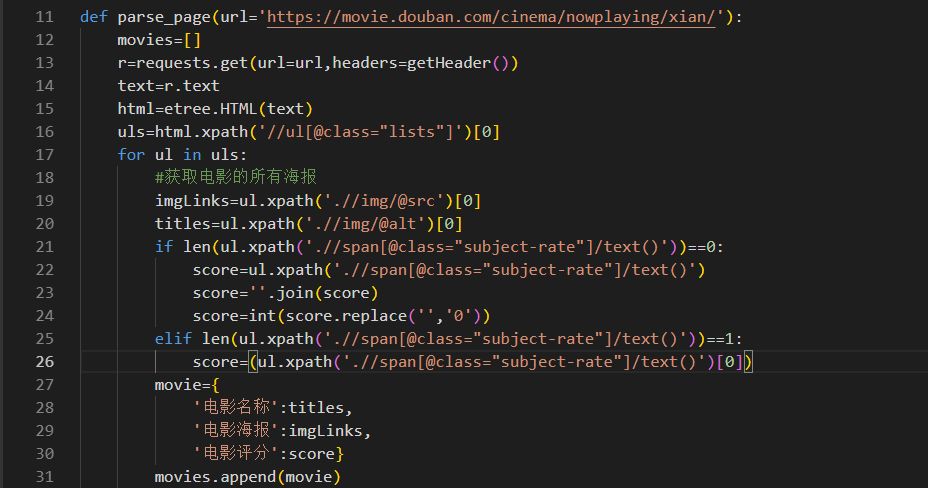
通过如上得到了电影的名称,电影的海报地址,和电影的评分,那么它这些数据放在movie的字典中,同时在函数的循环外面定义一个列表movies[],把movie添加到列表movies中,见实现的源码:
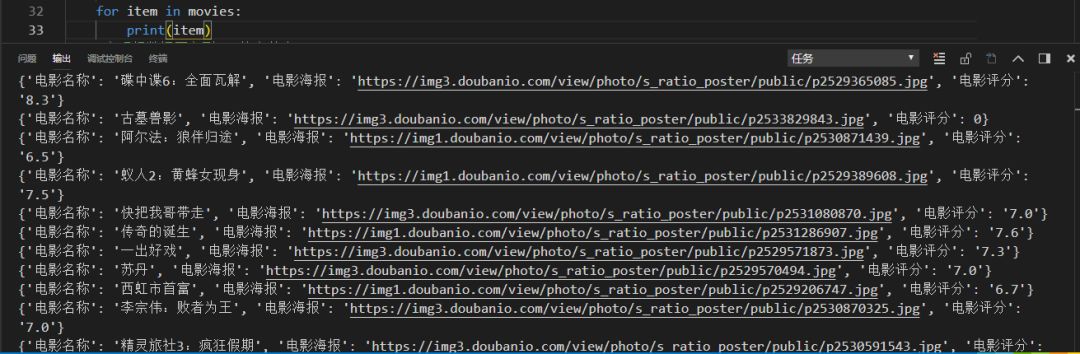
我们循环输出列表movies看内容具体是,见执行输出的结果:
下来就是把电影名称,电影海报链接地址和电影评分写入到CSV的文件中,见完整实现的源码:
from lxml import etree
import requests
import csv
'''获取豆瓣全国正在热映的电影:西安地区'''
def getHeader():
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
return header
def parse_page(url='https://movie.douban.com/cinema/nowplaying/xian/'):
movies=[]
r=requests.get(url=url,headers=getHeader())
text=r.text
html=etree.HTML(text)
uls=html.xpath('//ul[@class="lists"]')[0]
for ul in uls:
#获取电影的所有海报
imgLinks=ul.xpath('.//img/@src')[0]
titles=ul.xpath('.//img/@alt')[0]
if len(ul.xpath('.//span[@class="subject-rate"]/text()'))==0:
score=ul.xpath('.//span[@class="subject-rate"]/text()')
score=''.join(score)
score=int(score.replace('','0'))
elif len(ul.xpath('.//span[@class="subject-rate"]/text()'))==1:
score=(ul.xpath('.//span[@class="subject-rate"]/text()')[0])
movie={
'电影名称':titles,
'电影海报':imgLinks,
'电影评分':score}
movies.append(movie)
#实现把数据写入到csv的文件中
headers=['电影名称','电影海报','电影评分']
with open('movieCsv.csv','w',encoding='gbk',newline='') as f:
writer=csv.DictWriter(f,headers)
writer.writeheader()
writer.writerows(movies)
if __name__ == '__main__':
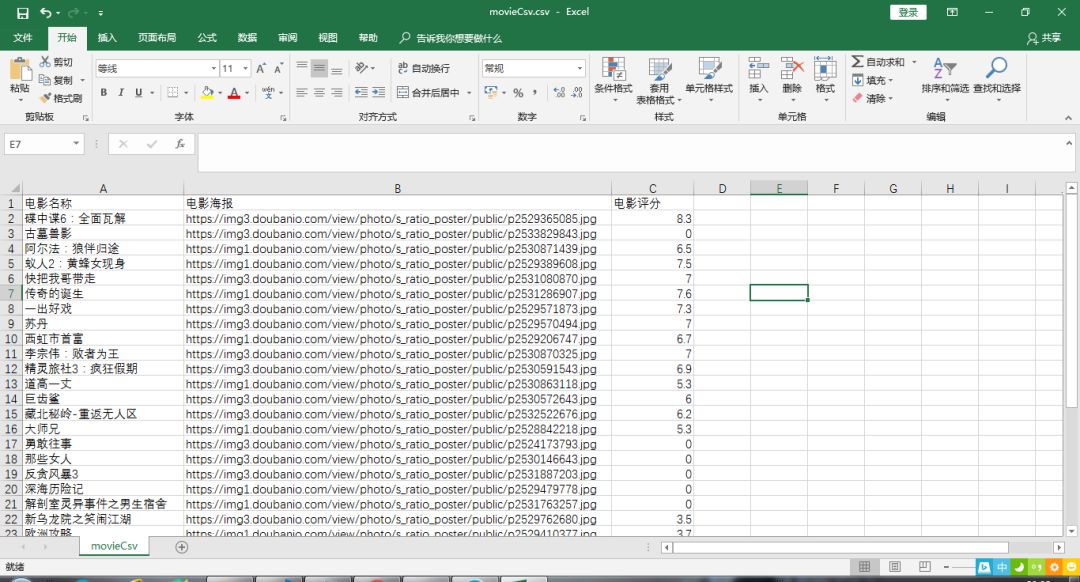
parse_page()打开movieCsv.csv文件,见写进去的数据截图:

















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











