






1. Colab安装旧版pytorch+numpy:(记得要restart)
![]()

2. Colab连接google账号:
Google colab使用教学 - xiaowei的文章 - 知乎 https://zhuanlan.zhihu.com/p/367893594
3. numpy&pytorch 1D外积计算:
torch没有outer函数,且torch.dot只能对1D进行点乘,1D以上只能使用torch.mm矩阵乘法;该函数一般只用来计算两个二维矩阵的矩阵乘法,而且不支持broadcast操作。

4. numpy&torch实现激活函数:
1)Relu
np.maximum(X, Y):是将X 与 Y 逐位比较取其大者;
def relu(inX):
return np.maximum(0,inX)Note:和np.max区分--np.max(a, axis=None, keepdims=False):求序列的最值,axis:默认为列向(也即 axis=0),axis = 1 时为行方向的最值 。

inplace=False,不改变输入的数据;
2) Prime ReLU

relu_x = np.maximum(0,x)
return (relu_x>0).astype(relu_x.dtype)torch.where(con, arg1, arg2) arg必须是tensor;
func = torch.nn.ReLU(inplace=False)
relu_x = func(x)
y = torch.ones(size=relu_x.shape, dtype=int)
return torch.where((relu_x>0), y, relu_x)5. numpy.object_报错
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, int64, int32, int16, int8, uint8, and bool.array([array([[3, 1, 4, 1],
[5, 9, 2, 6],
[5, 3, 5, 8]]),
array([[9, 7, 9, 3],
[2, 3, 8, 4]]),
array([[6, 2, 6, 4],
[3, 3, 8, 3],
[2, 7, 9, 5],
[0, 2, 8, 8]])], dtype=object)这个array是先append 到 list 里面,然后再转化为 np.ndarray 来存储。存储没问题。不会报错,但是如果其中有一个 np.ndarray 与其他的 np.array 在除第一维【0】之外的维度上不同的话【此array.shape=(3, )】,那么最后由list 转化成的np.ndarray 的dtype 就是numpy.object_ 。在后面加载数据想要用正常的 np.ndarray 或torch.from_numpy这种对numpy正常的操作,就会出现这个错误。
6. 对n维张量的指定维度进行反转(倒序)
>>> x
tensor([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
>>> torch.flip(x, dims=[0]) # 对第0维进行反转
tensor([[5, 6, 7, 8, 9],
[0, 1, 2, 3, 4]])
>>> torch.flip(x, dims=[1]) # 对第1维进行反转
tensor([[4, 3, 2, 1, 0],
[9, 8, 7, 6, 5]])
>>> torch.flip(x, dims=[0, 1]) # 对第0、1维进行反转
tensor([[9, 8, 7, 6, 5],
[4, 3, 2, 1, 0]])
————————————————
原文链接:https://blog.csdn.net/Ocean_waver/article/details/1138146717. torch.nn.functional.pad函数
torch.nn.functional.pad(input, pad, mode,value )
Args:
"""
input:四维或者五维的tensor Variabe
pad:不同Tensor的填充方式
1.四维Tensor:传入四元素tuple(pad_l, pad_r, pad_t, pad_b),
指的是(左填充,右填充,上填充,下填充),其数值代表填充次数
2.六维Tensor:传入六元素tuple(pleft, pright, ptop, pbottom, pfront, pback),
指的是(左填充,右填充,上填充,下填充,前填充,后填充),其数值代表填充次数
mode: ’constant‘, ‘reflect’ or ‘replicate’三种模式,指的是常量,反射,复制三种模式
value:填充的数值,在"contant"模式下默认填充0,mode="reflect" or "replicate"时没有
value参数
8. DFS遍历
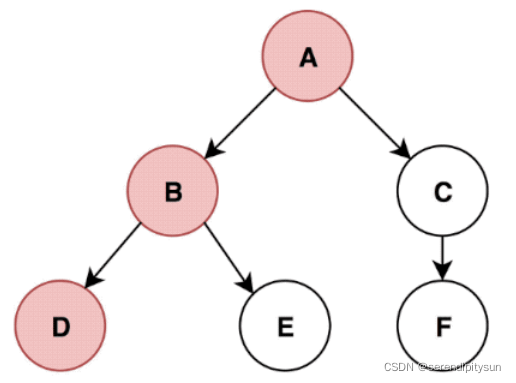
# Using a Python dictionary to act as an adjacency list
graph = {
'A' : ['B','C'],
'B' : ['D', 'E'],
'C' : ['F'],
'D' : [],
'E' : [],
'F' : []
}
visited = set() # Set to keep track of visited nodes.
def dfs(visited, graph, node):
print(node)
visited.add(node)
if set(graph[node])-visited:
for next in graph[node]:
dfs(visited, graph, next)
else:
return
pass
dfs(visited, graph, 'A')
















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









