






参考文献
Deep Interest Evolution Network for Click-Through Rate Prediction
前情提要
DIN
DIEN,全名Deep Interest Evolution Network,中文名为深度兴趣进化网络,在DIN中加了个E,Evolution,要知道,进化论也就是Evolution啊,把进化论放到名字里的算法,从此可见一斑。虽然人家其实跟进化论没啥关系,具体如何,下面分解。
上回且说到阿里向众人解释完DIN,意犹未尽,继续开始解释起DIEN来,只见他默默地甩出一张大图

见到此图,众人只觉得腰膝酸软,面如土色,只见阿里不紧不慢地开始解释起来。
你看这图,原先在DIN中User Behaviors的部分现在分成了三层,第一层Behavior Layer,第二层Interest Extractor Layer,第三层Interest Evolving Layer。第一层Behaviors Layer没什么好说的,就是用户曾经点击过的item打包全放在这里,但跟DIN不同的是,这里User Behaviors不叫User Behaviors了,叫User Behaviors Sequence,有了序列的概念,就是item间先后顺序变得重要起来,要按时间排列,这是什么讲究?这始于一个洞见,不仅是女人,所有人都是善变的,可能女人更严重些,具体来说就是人的兴趣也是一个演变的过程,你昨天喜欢哈登,没准明天就喜欢蔡徐坤了,不同的兴趣导致了不同的点击行为,User Behaviors Sequence是一个用户点击item的按照时间排列的序列b(1),b(2)…… b(T),这些行为序列本身其实反映了用户兴趣演变的过程,你喜欢哈登的时候会点击哈登同款保温杯,喜欢蔡徐坤的时候会点击蔡徐坤同款保温杯就是这个道理,所以我们希望通过用户行为序列洞悉其背后的用户兴趣演变,这时就是第二层Interest Extractor Layer派上用场的时候了,用户行为序列b(1),b(2)…… b(T)经过一个惯常的embedding得到e(1),e(2)…… e(T)后(embedding可以压缩向量维度,维度减小后续所需的参数就减小),就可以使用GRU提取用户兴趣了。那么GRU是什么,其中文名为门控循环单元,其是RNN(循环神经网络)的一种变体,闲话少说,直接公式说话

我们知道像RNN,GRU这种东西都是专门为了处理序列数据而设计的,而序列数据的特点么,就是一个连着一个,而有时候序列数据会特别长,像RNN这种网络我们都知道要用反向传播计算梯度更新参数,但序列数据一长,反向传播就不大容易,经常碰上梯度消失的情况(就是在传导的过程中传到某个序列中的item时对应的梯度等于0),梯度一消失,就相当于失去了学习能力,那么像RNN就只有短时记忆的能力(在反向传播时只有离其较近的item对应的梯度不为0),为了使网络具有长时记忆能力,在RNN的基础上设计了LSTM,GRU,基本思路都是在网络中加入一些门控单元,控制信息的流入流出,目的是去掉其中的冗余信息,使梯度传导变得容易些,梯度能传导得远,网络就具有了长时记忆能力。GRU的结构比LSTM简单,训练更容易,效果却差不多,所以眼下这个场景就使用GRU。来看上面的公式,u是更新门,r是重置门,i代表输入,这里的输入就是从第一层上来的embedding,h是输出,代表着一个隐藏状态,h中隐含着某时刻以往所有序列的信息,这里就用来表示某用户在当下的兴趣,我们知道一个人的兴趣确实跟以往的经历有关,上面每个符号的右下角都带有一个小t,代表着某个具体的时刻,对应着行为序列中的一项。前两个公式就是更新门u和重置门r的计算,经过sigmoid函数,两个门的值的范围都是0~1,第三个公式是计算头上带着一个波浪号的h,其包含有h t-1与新的输入it的信息, h t-1就表示着前一刻的隐藏状态,表征过去的信息,其会保留多少将由重置门rt决定。最后一个公式ht 就是当下这个时刻的隐藏状态,包含了当下以及过去的信息,但其中有包含多少当下的新信息以及多少过去的信息,就由更新门ut决定。这样,每个时刻(对应行为序列中每个item)都会计算出一个隐藏状态,这样我们就得到了h(1),h(2)…… h(T),可以用来表示每个时刻的兴趣。这就是第二层Interest Extractor Layer。为了更好地计算出每个时刻对应的ht,这里引入auxiliary loss,
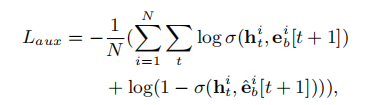
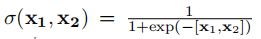
之所以引入auxiliary loss,是因为我们觉得某用户当下的兴趣(ht)与下一刻会采取的行动(eb[t+1])高度相关,其中我们还负采样了一些e^b(并非下一刻真正会采取的行动,随机抽取)帮助训练。auxiliary loss最后会加入总的目标函数一起参加训练。Well,这只是一些细节问题,不必太在意,接下来来说第三层。
第三层是Interest Evolving Layer。话说第二层我们计算出了用户兴趣序列h(1),h(2)…… h(T),表征着用户不同时刻的兴趣,兴趣的转化总有个轨迹,第三层我们就是想要捕捉这个兴趣的转化过程。不过,身为一个奸商,我们并不是对用户所有的兴趣都关心,我们只关心用户兴趣中跟最后我们要推荐给用户的item相关联的部分,针对这一点,我们同时使用GRU和Attention mechanism(DIN中的Activation Unit也是其中的一种)!GRU负责捕捉用户兴趣的转变,Attention mechanism则负责只提取出用户兴趣中与最后我们要推荐的item相关联的部分。最后我们设计出了一个叫AUGRU(GRU with attentional update gate)的东西。
说到提取相关联的部分,自然少不了计算权重。这里我们用兴趣序列中的item去跟Target ad交互出一个权重,
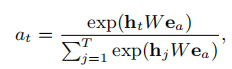
此即为计算权重的公式,ht即是对应兴趣序列中的item,ea是Target ad对应的embedding,W是待学习的参数。有了权重后,该怎么结合到GRU中以实现只捕捉与最后推荐的item相关联的兴趣的演变呢?
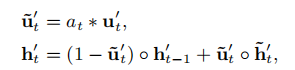
对照我们之前介绍GRU时所列出的那4个公式,会发现,计算出的权重通过校正更新门u’t从而影响最后计算的h’t,这里的公式符号右上角都带了一撇是因为第三层Interest Evolving Layer用的GRU需要与第二层Interest Extractor Layer用的GRU作出区分。权重越小,说明那个时刻的兴趣与最后我想要推荐给你的广告间关联性不大,就调低更新门u’t,那那个时刻的兴趣所对应的头上带波浪号的h’t就会更少被计算入最后的h’t中。
这样,经过第三层Interest Evolving Layer,我们最终计算出一个最后的h’T,其是考虑了用户所有以前的行为序列,考虑了与Target ad的相关性,如此得到的一个用户最终的一个状态,最后与其它平平无奇的特征拼接送入全连接网络就完事了!
至此,DIEN网络介绍完毕!训练就用万能的SGD就可以了。
众人听得阿里讲罢,只觉得嘴唇发白,头脑恍惚,人生如梦幻泡影,如露亦如电,想要蹒跚而去。
“站住,我,还有,更好的!”众人只见阿里的嘴角泛起一丝明媚的微笑,不禁让人想起那些年夕阳下的奔跑。
敬请期待DSIN!
DSIN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









