






参考文献
Learning Tree-based Deep Model for Recommender Systems
TDM,全名Tree-based Deep Model,中文名基于树搜索的深度推荐模型。我们知道,在做推荐时,通常有两个阶段,召回和排序,召回是从全部的item库中粗筛出一定量的item,再经过排序做精筛后推荐给用户。
从以上可以看出,召回的任务量其实非常大,需要从全库中搜寻用户可能感兴趣的item。如果每个item都要考虑,即遍历所有item的话,任务量是非常巨大的。所以现在普遍使用的技术是把用户和item都映射成embedding,通过用户和item的embedding之间的相似度匹配作k-最近邻推荐,确实有效率了很多。但这样的技术是有天花板的,用户和item间更多的交互信息,都是无法被表征的。你想,如果要表征用户和item间相互的交互信息,必然要把用户的embedding和item的embedding一起输入一个模型让它们去交叉,但这样一来,你都需要把item的embedding输入模型了,你要在全库中搜索合适的item,岂不是要考虑把全库的item的embedding都要一一输入模型?那不是又成了遍历!针对这些问题,阿里提出了基于树搜索的深度推荐模型。
我们都知道,树的搜索效率一般都比遍历高,通常是logN级,比起遍历的N级(N是要搜索的项的全部数量)时间复杂度就小了很多。阿里就是利用了这一点,使得在全库中搜索合适的推荐item时的时间复杂度大大降低。下面我们来看看阿里具体是怎么做的。先来看模型的概貌。

好的很,果然看着就挺复杂的。先来看上图中右下角树的部分,在图中这棵树就是棵平衡的二叉树(实际模型不需要是二叉的,但这里为了方便讲述),叶子节点对应着一个个item,全库中所有的item都能在叶子节点里找到对应的。而非叶子节点可以看成表征着一个类别,层级越往上的非叶子节点表征的类别的范围越广。比如从上往下,非叶子节点可以分别为无机物,电子产品,手机,智能手机,iPhone,iPhoneX。鉴于每个item,user都可以映射成embedding,相应的树中的每个节点(包括叶子节点和非叶子节点)也可以映射成 embedding。其中叶子节点(表示一个个具体的item那个)的embedding跟其对应的item的embedding是完全一样的,共享。
我们先假设我们已经有了一个已经训练好的模型,看如何利用它来做推荐。比如我们要推荐两个item。从level1出发,将level2中的每个节点对应的embedding分别拼接入左边的深度模型中,可以分别算出一个概率值,概率值越大,说明对应的用户越喜欢对应的节点代表的类别(或item,但这已经到了最下层的叶子节点),选出两个概率值最大的对应的节点,从这两个节点出发,对它们的子节点(在level3中),再次分别拼接入左边的深度模型中算出对应的概率值,再选出两个概率值最大的对应的节点(这些对应的节点都在level3中),如此重复再往下,直到最后一层的叶子节点,依然可以按照相同的方法选出两个对应概率值最大的,这就是我们要推荐给用户的两个item。

在图中,我们还看到了在DIN中我已详细介绍的Activation Unit,其是一样的道理,用户的兴趣多元,我们只关心与推荐标的(对应的树节点,代表类别或item)相关联的部分。(相关链接DIN)
至于图里面的Time window 1,Time window 2…Time window N,其实就是把用户的行为序列按时间拆分了下,算是考虑了不同时期用户的行为演变的轨迹。
左边的深度学习模型,就是拼接了各个时期用户行为对应的特征,推荐标的(对应的树节点)的特征,再加上一些平平无奇的特征(比如用户性别,年龄等,在图中未标注出来),然后就可以计算出用户对推荐标的的感兴趣程度。这里注意了,用户对应的embedding和推荐标的的embedding一起输入了深度学习模型,这里就能学习到更多用户和推荐标的之间更多交互的信息,这就解决了我们在一开始所说的当前的主流技术,即利用用户和item的embedding之间的相似度匹配作k-最近邻推荐,其无法表征更多用户和推荐标的之间更多交互的信息其产生的算法瓶颈的问题,又不需要遍历所有item(利用上面树的结构做搜索),其有望成为下一代的主流技术,可喜可贺。
讲完模型的结构,利用模型作推荐,然后我们再聊聊看TDM模型的训练问题。首先是如何构筑一棵树。如果我们已经有了每个item对应的embedding,就可以用embedding做kmeans聚类,聚成两类(适当调整使两个类别包含的item数差不多),每个类再聚成两类,这样一层一层聚,像极了树结构的一层一层,没错,这样就能搭起一棵树,这样搭起的树,节点间距离越近,对应的embedding间相似度也越高,但这是每个item已经有了embedding之后才能采取的办法。在没有之前,搭树也有办法,就是利用item原先就带有的类别信息,把类别一样的item放在一起,再将所有item排成一排,排定次序后,从中间劈开,把item分成两排,在每排的基础上再从中间劈开分成两排,这样类似二分法的办法,就也能搭起一棵树,这就是树的初始化。有了初始化的树,树中的节点对应的embedding就可以拼接入深度学习模型进行训练,训练收敛后我们的embedding就有了,这时就可以采用之前说的方法重新构筑出一棵树,接着再训练,当然也可以不那么麻烦,直接训练完就完了,但重新构筑树再训练最后的效果通常是更好的。
说完树的构筑我们再说样本的采样,样本有正样本,负样本,正样本就是用户最终确实表示感兴趣并点击的item,在树里面就是从对应这个item的叶子节点开始,从下往上,所有的父节点都算是正样本,负样本就是,在树的每一层,都随机抽一个节点(只要不是正样本节点)作为负样本。从上面的模型大图中我们用不同的颜色标注了正负样本,红色节点为负样本,绿色节点为正样本。
还有一点,之前说用训练好的模型作推荐的时候,说的是从level1出发,将level2中的每个节点对应的embedding分别拼接入左边的深度模型中,可以分别算出一个概率值,选出两个概率值最大的对应的节点,再从这两个节点再往下,这样一层一层下去,很顺畅,但之所以能这样,是因为我们在训练时对树有作了这样的规定
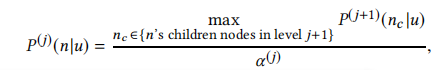
分母的Alpha(j)是个归一项,不用管,p(j)(n|u)是用户对树中某节点感兴趣的概率,是用某节点的embedding和用户相关的特征拼接入深度模型后算出来的,p(j+1)(nc|u)是用户对树中某节点的子节点感兴趣的概率,那就很清楚了,用户对树中某节点感兴趣的概率总是等于对其所有子节点中最感兴趣的那个最大概率除以一个归一项,保证父子节点之间的一致性,让我们可以从父节点开始找到用户最感兴趣的叶子节点。
到这里,关于TDM模型的介绍就结束了。















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









