






在计算机视觉领域,人脸检测是一项关键技术,广泛应用于安防监控、人脸识别、人机交互等多个场景。为了探索不同人脸检测模型的性能和效果,我进行了一次基于 OpenCV 的实践,下面将详细介绍整个过程和成果。
一、项目背景
随着深度学习的发展,人脸检测技术也在不断进步。传统的基于 Haar 特征的级联分类器仍然在某些场景下发挥着作用,而基于深度学习的模型如 Caffe 模型则在精度和速度上有了更大的提升。为了更好地理解这些模型的实际表现,我决定编写一个程序,能够加载不同格式的人脸检测模型,对视频中的人脸进行检测,并实时显示检测结果和相关性能指标。
这个项目是课上的一个小实验,在我敲代码完成的时候就发现其实不同模型对于识别的效果差别真的很大,就想着能不能把很多模型放在一起,设置一个脚本来进行选择运行,然后通过一些实时的指标来比较。其实这个效果很直观,特别是有一些多人头或者侧脸或者光线不同差异很大,后面我会说明。其实这个纯粹就是打代码上瘾了,搞了个出来玩玩而已,欢迎下载自己玩玩。
二、功能描述
该程序的主要功能包括:
-
模型加载 :自动检测当前目录下的模型文件,支持.xml(Haar Cascade)、.onnx 和.caffemodel 格式,将它们加载到内存中供后续使用。
-
模型选择 :用户可以通过输入模型对应的索引,选择想要使用的人脸检测模型。
-
视频检测 :使用选定的模型对指定视频文件进行人脸检测,实时绘制检测框,并在画面中显示关键的性能指标,如帧率(FPS)、推理时间、总检测目标数等。
-
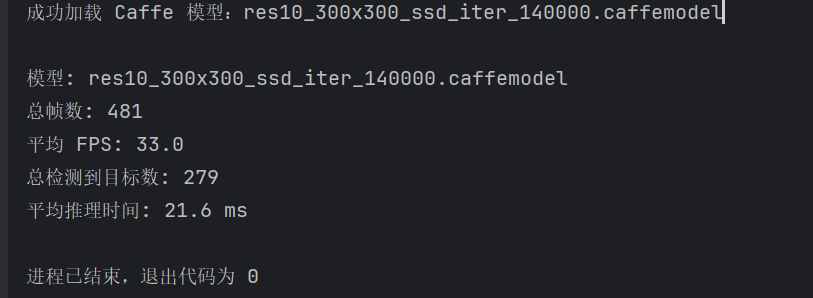
性能统计 :在检测结束后,输出整个视频检测过程的统计结果,包括总帧数、平均 FPS、总检测目标数和平均推理时间,方便对比不同模型的性能。
三、实现细节
1、模型加载与选择
程序首先会扫描当前工作目录,查找符合支持格式的模型文件,并将它们的信息存储在一个字典中,方便用户查看和选择。对于 Haar Cascade 模型,使用 OpenCV 的 CascadeClassifier 类进行加载;而对于 Caffe 模型,则需要指定对应的 prototxt 配置文件和模型文件,通过 OpenCV 的 dnn 模块进行加载。
2、视频检测与性能指标计算
在视频检测过程中,根据选择的模型类型,分别采用不同的检测方法。对于 Haar Cascade 模型,将每一帧图像转换为灰度图,然后使用 detectMultiScale 函数进行人脸检测;对于 Caffe 模型,则对图像进行预处理,创建 blob,并通过神经网络进行前向传播,获取检测结果。在每一帧检测完成后,计算该帧的推理时间,并更新总检测目标数、总时间和帧数等统计信息。同时,实时计算当前的帧率和平均推理时间,并将这些指标绘制在检测结果画面上,方便用户直观地了解模型的运行情况。
3、用户交互与结果显示
程序提供了简单的用户交互界面,用户可以通过输入模型索引或 'z' 来选择模型或退出程序。在视频检测过程中,用户也可以随时按下 'z' 键来终止检测并查看最终的统计结果。检测结果以视频画面的形式实时显示,检测框用绿色矩形表示,同时在画面左上角显示模型名称、帧率、推理时间和总检测目标数等信息。
四、运行步骤
-
确保安装了 OpenCV 库,可以通过命令
pip install opencv-python进行安装。 -
准备好不同格式的人脸检测模型文件,如 Haar Cascade 的.xml 文件、Caffe 的.prototxt 和.caffemodel 文件等,并将它们放置在程序的当前工作目录下。
-
准备好要进行人脸检测的视频文件,修改程序中的 video_path 变量,指定视频文件的路径。
-
运行程序,根据提示选择要使用的人脸检测模型,然后观察视频检测结果和性能指标的显示。
-
检测结束后,查看输出的统计结果,对比不同模型在该视频数据上的性能表现。
五、项目说明
1、输入输出
把想要运行的视频名称与格式替换video_path,并把视频放在同目录下(这些视频在文件里面有)。
# 初始化视频捕获
# video_path = "36ba5f88e94802f4018513301362c16b.mp4" # 确保视频文件存在
# video_path = "eb9f10458ed5769c78841e16f299524b.mp4" # 确保视频文件存在
video_path = "20250326_223048.mp4" # 确保视频文件存在运行后自动读取同目录下所有可以用的模型并建立好索引,可自行输入选择,提交选择后会打开视频实时检测并有实时效果指标。
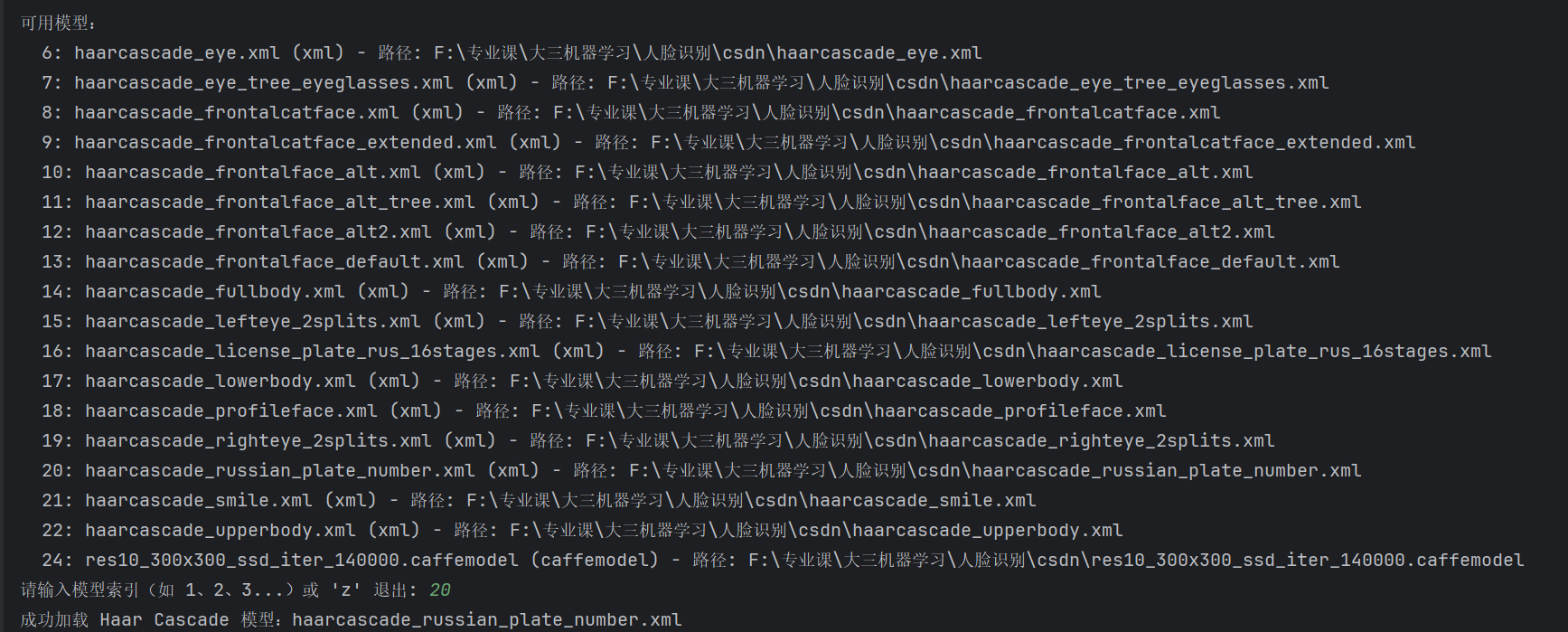
2、模型说明
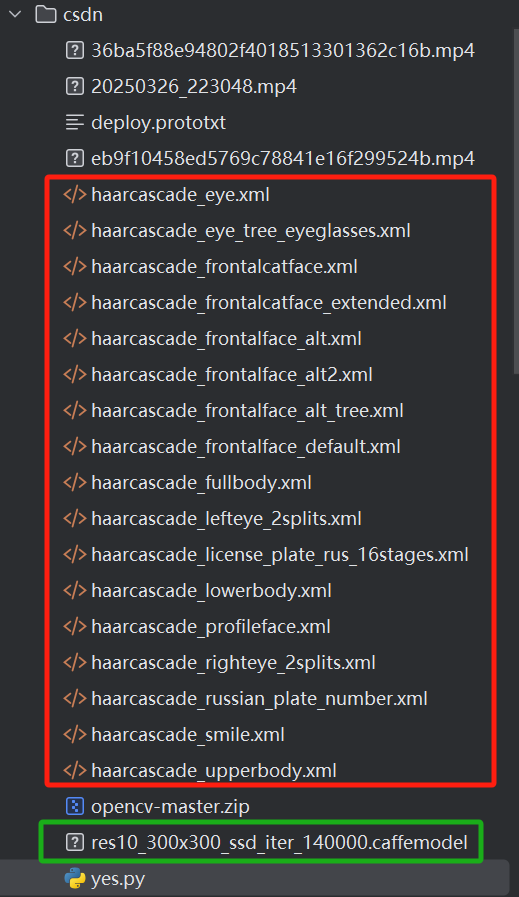
项目文件里面有我找到的一些可以使用的xml模型,这些模型都是在GitHub opencv里面训练好的模型。还有一个dnn模型,是caffemodel格式的,和它的配置文件deploy.prototxt。如果你有别的模型,是xml格式的且不用配置文件的理论上可以直接使用(放到同目录下),如果要配置文件的可以仿照我对dnn模型的调用自己修改代码。
opencv![]() https://github.com/opencv/opencv/tree/master/data/haarcascades
https://github.com/opencv/opencv/tree/master/data/haarcascades
在我项目文件里面也有放GitHub下载好的压缩包。
3、运行结果
我截取了一个我很喜欢的电影片段(《胜券在握》)进行测试,可以看到视频左上角有你使用模型的名字、FPS等指标实时监控。

按z退出后,日志会返回相应指标用来对比。
六、效果对比
这个程序不仅仅是对人脸的识别,可以看看模型名的前缀后缀,比如这个是对笑脸的识别,还有很多比如:对上半身、对眼睛、对左眼、对下半身、全身......的识别,非常好玩。
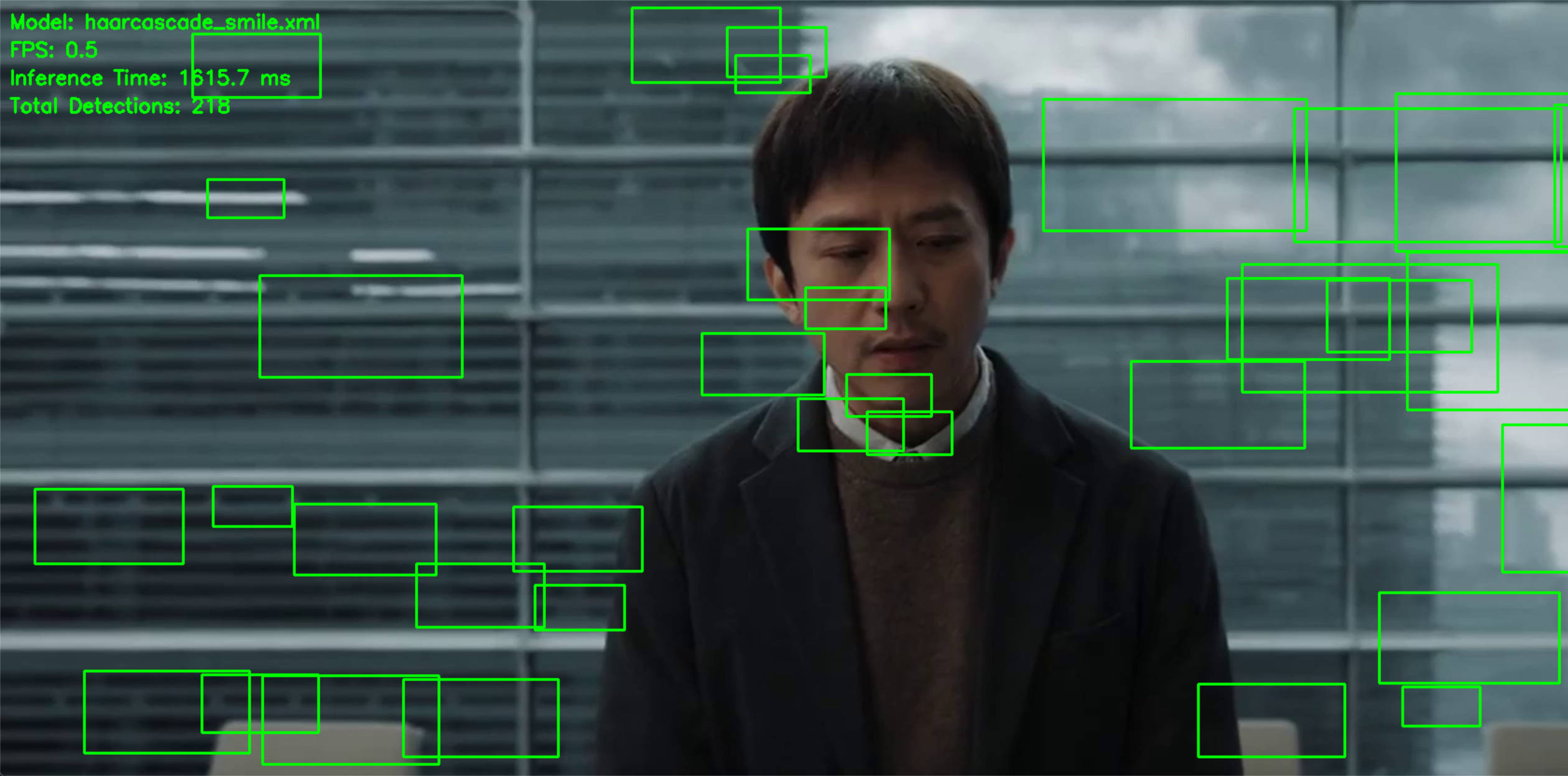
不同模型在同一片段的差别也可以很明显地体现,非常好玩。


在课上老师给的模型在下图可能根本检测不到或者要光线很充足或者要放很大才行。

总而言之,就是很好玩哈哈哈,大家可以自己下载来玩玩。
通过网盘分享的文件:opencv项目
链接: https://pan.baidu.com/s/19hdFZgifzRTLKtdvWqqfFg?pwd=1111 提取码: 1111

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









