






在电商平台蓬勃发展的当下,精准预测用户购买行为对于优化营销策略、提升用户体验具有关键意义。本次实验聚焦于利用机器学习分类算法预测用户是否会购买衣服,通过对比不同算法性能,挖掘最适合此类场景的模型。以下将详细阐述实验过程、结果分析及技术要点。
一、实验概述
本次实验旨在使用机器学习分类算法,包括决策树(ID3、CART)、高斯朴素贝叶斯和逻辑回归,对电商平台用户购买衣服行为进行预测。通过对比不同算法的性能,探索在有限特征和小规模数据集情况下,各算法的表现特点,为实际业务场景中的算法选择提供参考依据。
二、实验环境搭建
实验基于 Python 3.x 开发环境展开,主要依赖以下关键库:
-
pandas:负责数据加载与预处理,便捷地完成数据集的读取和特征、标签的分离。
-
scikit-learn:一站式机器学习库,涵盖模型训练、评估等全流程功能,提供多种分类算法实现及性能评估指标计算。
-
matplotlib/seaborn:承担数据可视化任务,通过柱状图、雷达图等直观展示算法性能差异。
数据集为 7_buy.csv,包含 14 条样本数据,涵盖 review(用户评价)、discount(折扣力度)、needed(需求程度)、shipping(运费)4 个特征,以及 buy(0-1 二分类标签)。
三、实验步骤解析
数据加载与预处理
使用 pandas 的 read_csv 函数轻松加载本地 CSV 格式数据集,并清晰地分离出特征矩阵 X 和标签 y,为后续模型训练奠定基础。
# 1. 加载数据集
data = pd.read_csv('7_buy.csv')
X = data[['review', 'discount', 'needed', 'shipping']]
y = data['buy']数据集划分
采用分层随机抽样策略,按 8:2 比例划分训练集和测试集,确保标签在训练集和测试集中分布一致,避免因标签分布不均导致的模型评估偏差。
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)模型初始化
精心初始化 4 种分类算法:
-
ID3 决策树:基于信息增益准则(criterion='entropy'),擅长处理离散特征,通过特征分裂直观拟合数据。
-
CART 决策树:基于基尼不纯度准则(criterion='gini'),与 ID3 决策树在决策树构建逻辑上有所不同,但在小规模数据集上表现相当。
-
高斯朴素贝叶斯:假设特征服从正态分布,尽管对特征独立性假设较为敏感,但在小规模数据集上仍有一定适用性。
-
逻辑回归:作为经典线性分类模型,通过增加迭代次数(max_iter=1000)确保模型在有限数据下能够充分收敛。
# 3. 初始化分类算法
models = {
'ID3决策树 (Entropy)': DecisionTreeClassifier(criterion='entropy', random_state=42),
'CART决策树 (Gini)': DecisionTreeClassifier(criterion='gini', random_state=42),
'高斯朴素贝叶斯': GaussianNB(),
'逻辑回归': LogisticRegression(max_iter=1000, random_state=42) # 增加迭代次数确保收敛
}模型训练与预测
对每个模型依次进行训练,利用训练集数据拟合模型参数,随后在测试集上进行预测,得到预测标签,为后续性能评估提供数据支持。
# 4. 模型训练与预测
results = []
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, output_dict=True)
results.append({
'模型': name,
'准确率': accuracy,
'精确率': report['1']['precision'],
'召回率': report['1']['recall'],
'F1分数': report['1']['f1-score']
})模型评估
借助 accuracy_score 计算准确率,并利用 classification_report 获取精确率、召回率、F1 分数等指标,全面量化模型在测试集上的表现。这些指标从不同维度反映模型性能,准确率体现整体分类正确性,精确率关注预测为正类样本的准确性,召回率衡量实际正类样本被正确召回的比例,F1 分数则综合平衡精确率和召回率。
# 5. 结果汇总
result_df = pd.DataFrame(results)
print("模型评估结果:")
print(result_df)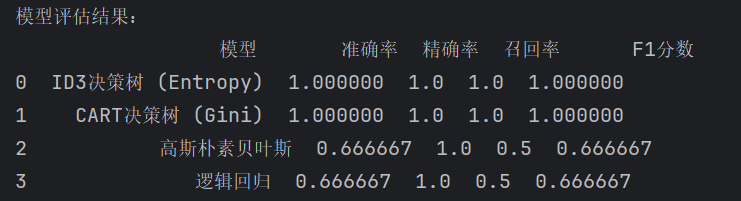
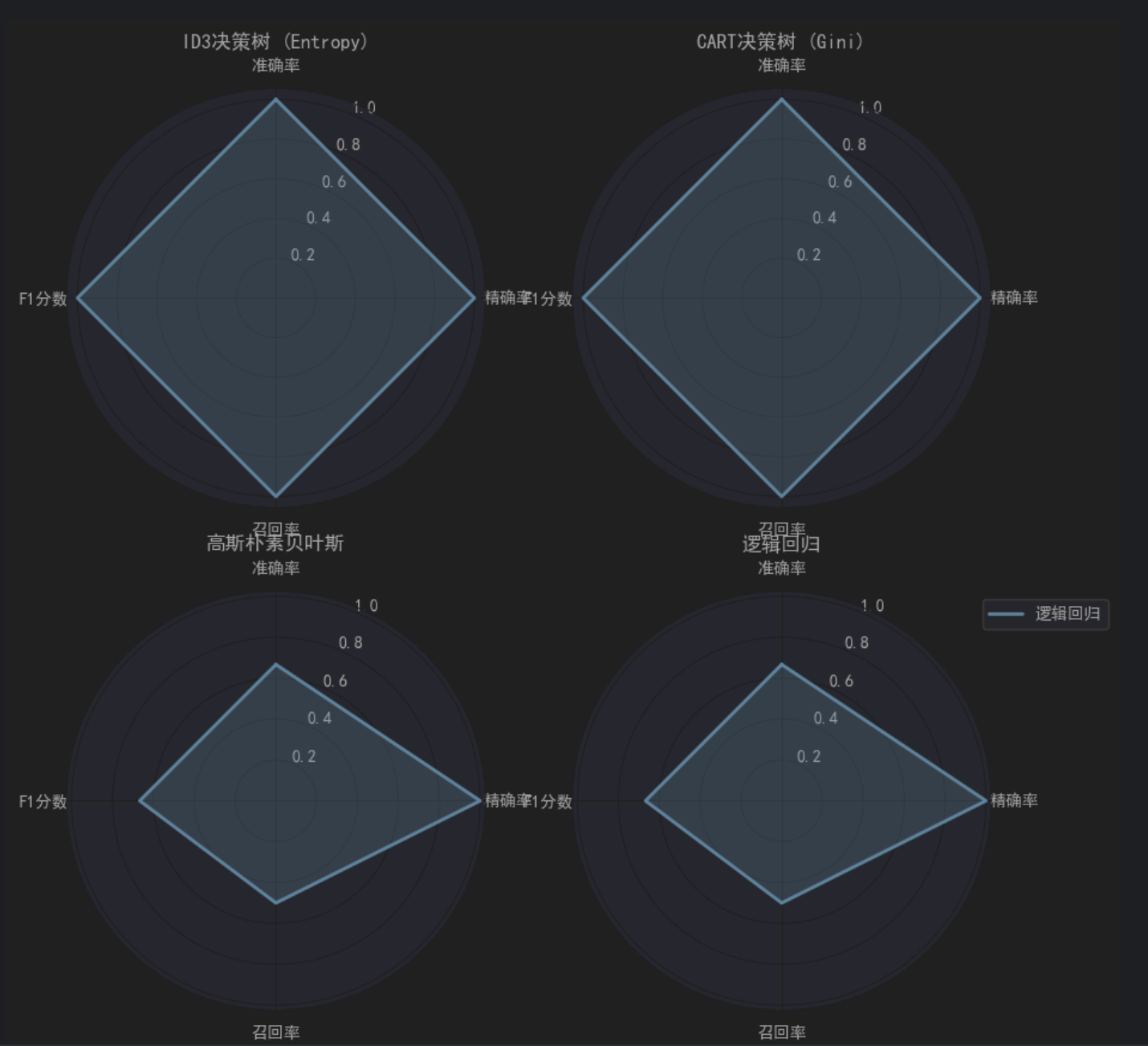
可视化展示
运用 seaborn 绘制柱状图,清晰对比各算法准确率,结合数据标签直观呈现百分比差异。进一步借助雷达图多维度展示精确率、召回率、F1 分数等指标,全方位呈现算法性能差异,使模型对比结果一目了然。
# 6. 可视化比对结果
plt.figure(figsize=(12, 6))
# 绘制准确率柱状图
sns.barplot(x='模型', y='准确率', data=result_df, palette='viridis')
plt.title('不同分类算法准确率对比')
plt.ylabel('准确率')
plt.xticks(rotation=45)
# 添加数据标签
for p in plt.gca().patches:
height = p.get_height()
plt.text(p.get_x() + p.get_width()/2., height,
'{:.2f}%'.format(height*100),
ha='center', va='bottom')
plt.tight_layout()
plt.show()
#(可选)扩展:绘制详细指标雷达图(需安装numpy)
import numpy as np
categories = ['准确率', '精确率', '召回率', 'F1分数']
num_cats = len(categories)
plt.figure(figsize=(10, 10))
angles = np.linspace(0, 2*np.pi, num_cats, endpoint=False).tolist()
angles += angles[:1] # 闭合图形
for i, model in enumerate(results):
values = [model[cat] for cat in categories]
values += values[:1]
ax = plt.subplot(2, 2, i+1, polar=True)
ax.plot(angles, values, linewidth=2, label=model['模型'])
ax.fill(angles, values, alpha=0.25)
ax.set_theta_offset(np.pi/2)
ax.set_theta_direction(-1)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories)
ax.set_title(model['模型'])
ax.grid(True)
plt.legend(loc='upper right', bbox_to_anchor=(1.3, 1.0))
plt.show()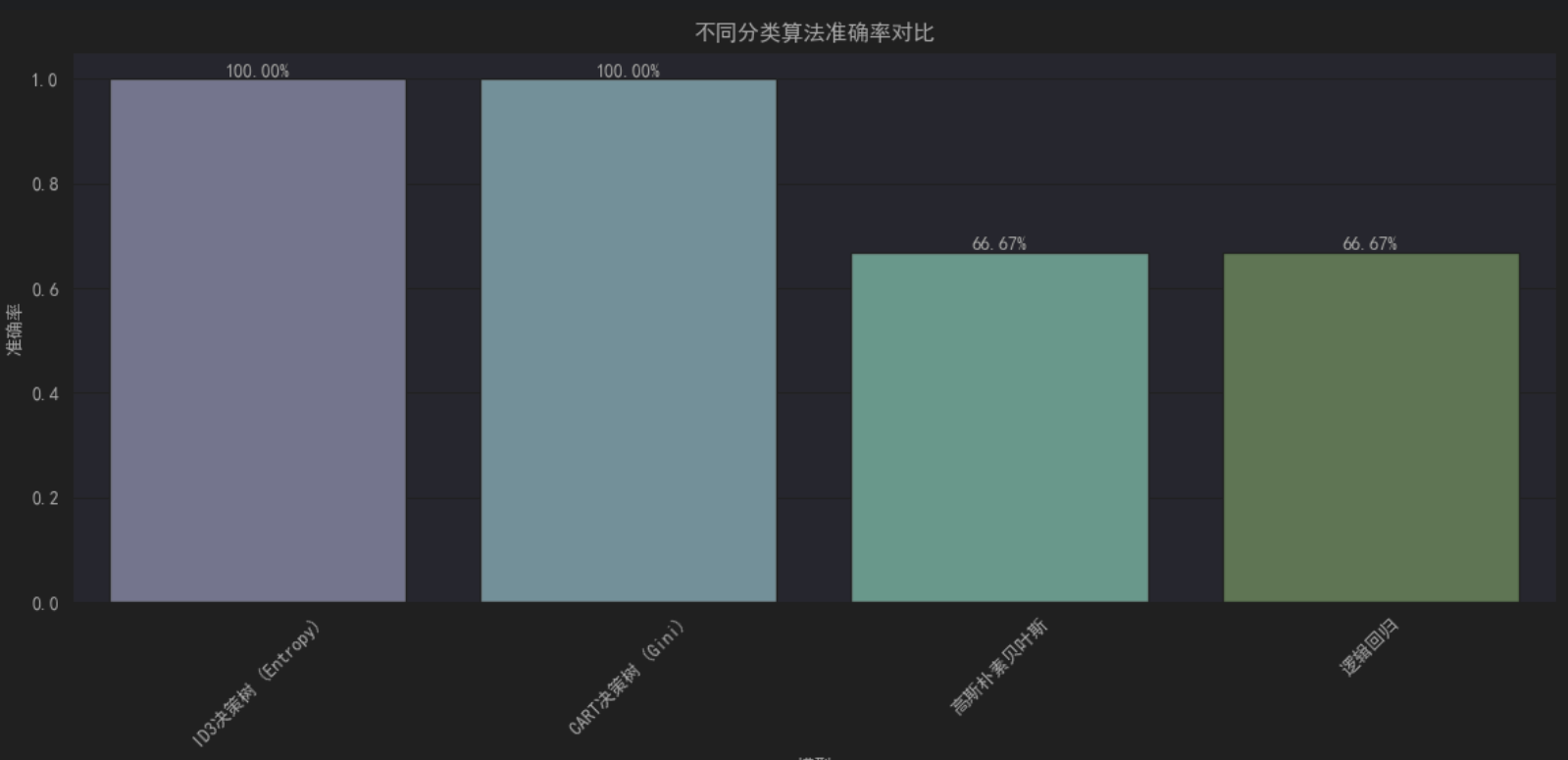
四、实验结果分析
从实验结果来看,决策树算法(ID3 和 CART)在小规模数据集上表现优异。这主要得益于决策树模型通过特征分裂直接拟合数据,对离散特征(如 needed、shipping)的划分十分直观有效,能够较好地捕捉数据中的模式,且在小规模数据情况下未出现明显的过拟合现象。
高斯朴素贝叶斯虽然对小规模数据有一定适应性,但受限于特征间可能存在的相关性(例如 discount 和 review 可能存在关联),其召回率相对较低,反映出该模型在特征独立性假设被违背时性能受限。
逻辑回归作为线性模型,对线性可分数据具有天然优势。然而,本实验数据量较小,未对特征进行标准化 / 归一化处理,这在一定程度上影响了模型性能发挥,使其在特征分布特性上未能达到最佳匹配,导致整体表现稍逊于决策树模型。
五、改进方向展望
本次实验为电商购买行为预测提供了初步探索思路,但也明确了诸多改进方向:
-
数据量扩充:增加更多样本数据,验证算法泛化能力,避免因小规模数据导致的模型性能评估偏差。
-
决策树参数优化:调整决策树参数(如 max_depth),防止过拟合现象发生,在模型复杂度和泛化能力之间寻求平衡。
-
特征工程强化:对特征进行归一化 / 标准化处理,提升逻辑回归等对特征尺度敏感模型的性能;同时深入挖掘特征组合关系,创造更有代表性的特征,进一步提升模型预测能力。
总体而言,本次实验成功对比了不同机器学习分类算法在电商平台购买衣服预测场景下的表现,为后续更深入、更具针对性的算法优化和业务应用奠定了坚实基础。通过不断改进模型和数据,有望实现更精准的用户购买预测,助力电商平台优化营销策略,提升用户满意度和商业价值。
通过网盘分享的文件:含两个实验代码与数据
链接: https://pan.baidu.com/s/1mQmKQIRwJ7IRaZhRMYlrzQ?pwd=1111 提取码: 1111


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









