







1、摘要
上一篇文章我们安装以及配置了伪分布式模式,下面讲解本地模式:本地模式需要将上一篇文章的etc/hadoop下面的配置文件还原为默认解压缩时的配置(除了hadoop-env.sh)本地模式和伪分布式模式都是测试和调试的时候使用的,生产环境用的是全分布式模式。而伪分布式模式又是弥补本地模式的不足(本地模式无守护进程)。下面测试下本地模式:
1、在压缩目录下新建input目录(mkdir input)
2、放入2个文本文件1.txt和2.txt里面分别输入一些单词
3、bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount input output (执行此语句会自动生成output文件夹)执行上面的命令后使用cat output/* ,单词统计结果如下:
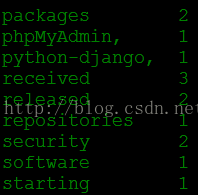
4、 rm -rf output/
5、 mkdir -p /opt/hadoop-2.7.2/playground
6、 拷贝hadoop源码下的WordCount.java(cp /opt/hadoop-2.7.2-src/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java /opt/hadoop-2.7.2/playground)
7、 移除包名package org.apache.hadoop.examples;
8、 bin/hadoop com.sun.tools.javac.Main playground/src/WordCount.java
9、 jar cf wc.jar WordCount*.class
10、 bin/hadoop jar wc.jar WordCount input output
11、 cat output/*















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









