







Java基础
1 .String类为什么是final的?
主要是为了“效率” 和 “安全性” 的缘故。若 String允许被继承, 由于它的高度被使用率, 可能会降低程序的性能,所以String被定义
成final.
效率:String a = "aaa"; String b = "aaa";变量a,b指向同一个内存地址,在大量使用类似的字符串时能提高效率。
安全:同一个字符串实例可以被多个线程共享。String不可变便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。2 .String a= “abc” String b = “abc” String c = new String(“abc”) String d = “ab” + “c” .他们之间用 == 比较的结果?
a==b true
a==c false
a==d true
b==c false
b==d true
c==d false
如果final String a= "ab";String b = "abc"; String d = a + "c";则:b==d true 去掉fianl b==d false
如果final String a= run()(run是一个函数return "ab");String b = "abc"; String d = a + "c";则:b==d false
注:String a = new String("abc")涉及到几个对象? 2个
String a = new String("abc")代码执行过程中创建了几个对象? 1个 a
String a = new String("abc")类加载中创建了几个对象? 1个 abc3.重载与重写的区别
重载的规则:
1、在使用重载时只能通过相同的方法名、不同的参数形式实现。不同的参数类型可以是不同的参数类型,不同的参数个数,不同的参数顺序
(参数类型必须不一样);
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
重写的规则:
1、重写方法的参数列表必须完全与被重写的方法的相同,否则不能称其为重写而是重载.
2、重写方法的访问修饰符一定要大于被重写方法的访问修饰符(public>protected>default>private)。
3、重写的方法的返回值必须和被重写的方法的返回一致;
4、重写的方法所抛出的异常必须和被重写方法的所抛出的异常一致,或者是其子类;
5、被重写的方法不能为private,否则在其子类中只是新定义了一个方法,并没s有对其进行重写。
6、静态方法不能被重写为非静态的方法(会编译出错)。4 .抽象类和接口的区别
抽象类特点:抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认
为public;抽象类不能用来创建对象;如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现
父类的抽象方法,则必须将子类也定义为为abstract类。
接口特点:接口中的变量会被隐式地指定为public static final变量(并且只能是public static final变量,用private修饰会报编译错
误),而方法会被隐式地指定为public abstract方法且只能是public abstract方法(用其他关键字,比如private、protected、
static、final等修饰会报编译错误),并且接口中所有的方法不能有
具体的实现
区别:
1.抽象类里可以有构造方法,而接口内不能有构造方法。
2.抽象类中可以有普通成员变量,而接口中不能有普通成员变量。
3.抽象类中可以包含非抽象的普通方法,而接口中所有的方法必须是抽象的,不能有非抽象的普通方法。
4.抽象类中的抽象方法的访问类型可以是public ,protected和默认类型,但接口中的抽象方法只能是public类型的,并且默认即为
public abstract类型。
5.抽象类中可以包含静态方法,接口内不能包含静态方法。
6.抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static
类型,并且默认为public static类型。
7.一个类可以实现多个接口,但只能继承一个抽象类。5.hashtable和hashmap的区别
1.继承不同,HaspMap继承AbstractMap,Hashtable继承Dictionary,但都实现Map接口
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, Serializable
2.Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要
使用HashMap的话就要自己增加同步处理了。HashMap可以使用Map<Object, Object> map1 = Collections.synchronizedMap(new HashMap<>())
达到同步效果。
3.Hashtable中,key和value都不允许出现null值;在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为
null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法
来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
4.两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
HashMap遍历的两种方法:
A: HashMap<String,String> map = new HashMap<>();
Iterator<Entry<String, String>> es = map.entrySet().iterator();
while(es.hasNext()){
Entry<String,String> en = es.next();
System.out.println(en.getKey()+" "+en.getValue());
}
B: HashMap<String,String> map = new HashMap<>();
Iterator<String> set = map.keySet().iterator();
while(set.hasNext()){
String s = set.next();
System.out.println(s+" "+map.get(s));
}
5 .哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
6 .Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是
old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。 6.几个Java集合类
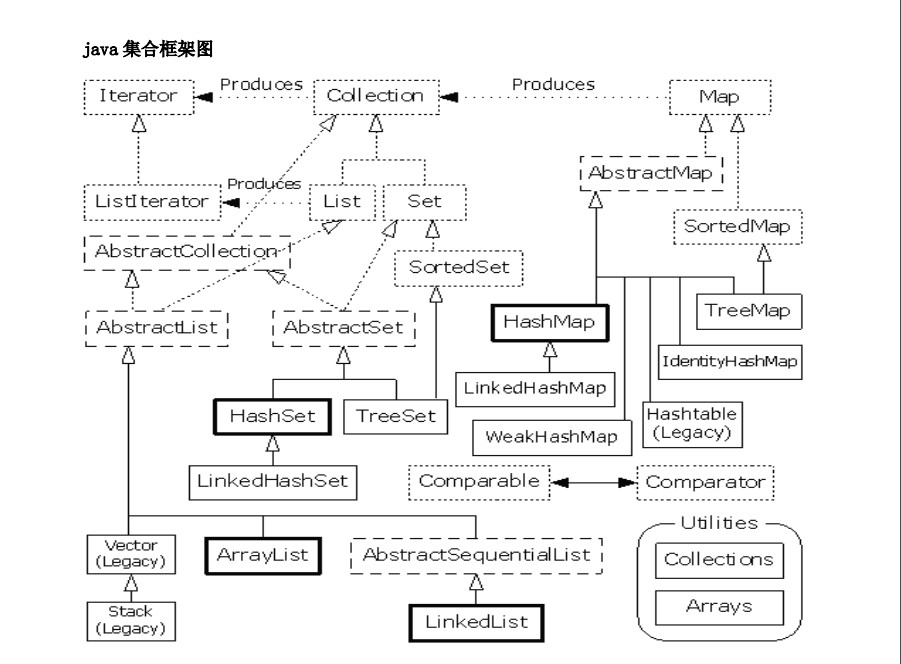
1.HashSet:里面不能存放重复元素,而且采用散列的存储方法,所以没有顺序。
2.HashMap(Hashtable)
3.ArrayList:ArrayList是List的子类,它和HashSet想法,允许存放重复元素,因此有序。集合中元素被访问的顺序取决于集合的类型。如
果对ArrayList进行访问,迭代器将从索引0开始,每迭代一次,索引值加1。
4.LinkedList:一种可以在任何位置进行高效地插入和删除操作的有序序列。允许null元素
5.Stack:Stack继承自Vector,实现一个后进先出的堆栈。
6.vetcor:Vector非常类似ArrayList,但是Vector是同步的。
比较:
1.ArrayList与LinkedList:继承不同LinkedList继承AbstractSequentialList,ArrayList继承AbstractList;ArrayList基于动态数组数据
结构,LinkedList基于链表;对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
2.ArrayList与Vector:都实现了List接口,Vector是线程安全的,ArrayList是非线程安全的,相对来说ArrayList的效率较高;两者的扩容
方式不同,ArrayList是默认扩充为原来的1.5倍,Vector是默认扩容为原来的2倍。
7.string、stringbuilder、stringbuffer区别
String:是对象不是原始类型.为不可变对象,一旦被创建,就不能修改它的值.对于已经存在的String对象的修改都是重新创建一个新的对象,
然后把新的值保存进去.String 是final类,即不能被继承.
StringBuffer:StringBuffer在进行字符串处理时,不生成新的对象,在内存使用上要优于String类。所以在实际使用时,如果经常需要对一
个字符串进行修改,例如插入、删除等操作,使用StringBuffer要更加适合一些。是线程安全的
StringBulider:与StringBuffer大致相同,只是不是线程安全的,效率要高于StringBuffer
选择:
如果要操作少量的数据使用String;单线程操作字符串缓冲区下操作大量数据使用StringBuilder;多线程操作字符串缓冲区下操作大量数据
使用StringBuffer8 .java异常
异常类结构层次图:
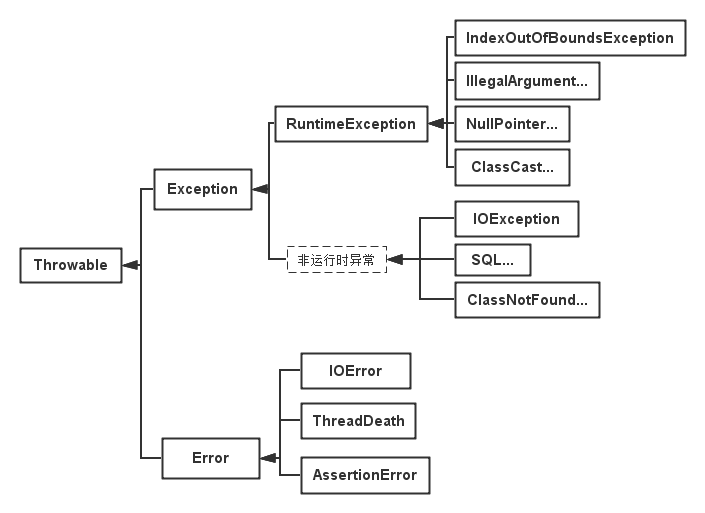
所有的异常类都有一个共同的祖先类Throwable,包含两个子类Exception(异常)和Error(错误)。
Exception:是程序本身可以处理的异常。
Error:是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误表示代码运行时 JVM(Java 虚拟机)出现的问题。
java异常(包括RuntimeException和Error)可分为检查异常与非检查异常。
检查异常:正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而
且一旦发生这种异常状况,就必须采取某种方式进行处理。包括除RuntimeException及其子类的其他异常。
非检查异常:包括运行时异常(RuntimeException与其子类)和错误(Error)。
Exception分为运行时异常和非运行时异常。
运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,
这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。
非运行时异常:是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,
程序就不能编译通过。
注:对于有多个catch子句的异常程序而言,应该尽量将捕获底层异常类的catch子句放在前面,同时尽量将捕获相对高层的异常类的catch子句
放在后面。否则,捕获底层异常类的catch子句将可能会被屏蔽。9 .Object类的方法
equals():指示其他某个对象是否与此对象“相等”。
toString():返回该对象的字符串表示。
wait(): 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待。
notify():唤醒在此对象监视器上等待的单个线程。
notifyAll():唤醒在此对象监视器上等待的所有线程。
hashCode():返回该对象的哈希码值。
clone():创建并返回此对象的一个副本
getClass():返回此 Object 的运行时类。
finalise():当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。10 .hash表、hashCode()与equals()的重写
1.hash算法(hash表的构造方法)
a.直接定制法
b.除留余数发
c.折叠法
d.平方取中法
2.解决hash冲突的方法
a.开放定址法
关键字{23,12,14,2,3,5},表长14,hash函数key%11,则表中存储如下:
地 址 0 1 2 3 4 5 6 7 8 9 10 11 12 13
关键字 23 12 14 2 3 5
b.链地址法
用数组加链表存储
3.重写equals()后必须重写hashCode()的原因
hashCode相同,equals()可同可不同,hashCode()不同,equals()一定不同;反之,equals()相同,hashCode()一定相同,但equals()
不同,hashCode()可同可不同。如定义两个对象的属性值一样即相同时,重写equals()方法实现上述条件,但两个对象的存储地址不同,
hashCode()不重写,导致两个对象的hashCode()不同,则违背了equals()相同,hashCode()一定相同的规则。
注:/*
1.在程序执行期间,只要equals方法的比较操作用到的信息没有被修改,那么对这同一个对象调用多次,hashCode方法必须始终如一地
返回同一个整数。
2.如果两个对象根据equals方法比较是相等的,那么调用两个对象的hashCode方法必须返回相同的整数结果。
3.如果两个对象根据equals方法比较是不等的,则hashCode方法不一定得返回不同的整数。
*/
4.重写(不重写hashCode结果为null)
public class YuanMa {
private String name;
private String age;
public YuanMa(String name,String age){
this.age = age;
this.name = name;
}
public static void main(String[] args) {
YuanMa yuan = new YuanMa("kkk", "12");
System.out.println(yuan.hashCode());
HashMap<YuanMa,String> map = new HashMap<YuanMa, String>();
map.put(yuan, "1");
System.out.println(map.get(yuan));
}
@Override
public int hashCode() {
return this.name.hashCode()+this.age.hashCode();
}
@Override
public boolean equals(Object obj) {
if(this.getClass()!=obj.getClass()){
return false;
}
if(this == obj){
return true;
}
YuanMa yuan = (YuanMa)obj;
return this.name.equals(yuan.name)&&this.age == yuan.age;
}
}11 .拆箱与装箱
对于Byte,Short,Character,Integer,Long来说通过ValueOf方法创建对象时,如果数值在[-128,127]之间(Character是小于127),便返回
指向已经存在的对象的引用;否则创建一个新的对象。
对于Boolean来说:
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
对于Double与Float来说:
public static Double valueOf(double d) {
return new Double(d);
}
public static Float valueOf(float f) {
return new Float(f);
}12 .hashmap的实现原理,知识点
HashMap的内部实现机制,Hash是怎样实现的,什么时候ReHash:
http://www.cnblogs.com/schbook/p/3585159.html?utm_source=tuicool&utm_medium=referral
HashMap实现原理分析:
http://blog.csdn.net/vking_wang/article/details/14166593
HashMap的工作原理:
http://blog.csdn.net/zheng0518/article/details/4510002513 .IO
IO常见类:
a.字符流:
b.字节流:
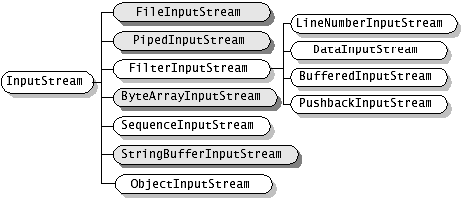
InputStream、OutputStream、Writer、Reader都是抽象类。
递归读取文件加下的文件:
public void startFile(String dirpath){
File[] file = new File(dirpath).listFiles();
for(File f : file){
if(f.exists()&&f.isFile()){
System.out.println(f.getName());
}else{
if(f.isDirectory()){
startFile(f.getAbsolutePath());
}else{
System.out.println("读取错误!");
}
}
}
}
IO详解:
http://www.cnblogs.com/dolphin0520/p/3791327.html14 .线程池
三种常用的线程池:
newCachedThreadPool:较适合没有固定大小并且比较快速就能完成的小任务,缓冲池容量大小为Integer.MAX_VALUE,线程空闲60s就自动销
毁,使用的是SynchronousQueue。
newFixedThreadPool:自定义线程池大小,与线程池最大线程数数值相同,使用的LinkedBlockingQueue。
newSingleThreadExecutor:单线程化的线程池,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行,使用的LinkedBlockingQueue。
ThreadPoolExecutor类(核心类)的构造函数(其他三个都调用了这个来初始化):
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
线程池运行流程:
1.当线程池中线程数(count)< corePoolSize时,创建线程放入池中运行处理任务;
2.当count >= corePoolSize时,将任务存放入缓存队列BlockingQueue<Runnable> workQueue中,有空闲线程时从队列中取出任务并处理;
3.当缓存队列放置满时,扩充线程池处理任务直到达到maximumPoolSize的大小;
4.当count >= maximumPoolSize时,会调用 RejectedExecutionHandler handler来拒绝处理;
5.当count >= corePoolSize时,多余的线程会保持keepAliveTime的时间,如果没有任务来处理时,就销毁线程。
参考:
http://www.cnblogs.com/dolphin0520/p/3932921.html
http://blog.csdn.net/cutesource/article/details/6061229
http://blog.csdn.net/xieyuooo/article/details/871874115 .在一个主线程中,要求有大量(很多很多)子线程执行完之后,主线程才执行完成:
单线程下:
1.join()
2.Future.get()
3.阻塞队列BlockingQueue
多线程:
1.join()
2.Future.get()
3.阻塞队列BlockingQueue
4.CountDownLanch(推荐)
参考:
http://www.jiacheo.org/blog/262
阻塞队列:
支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等
待队列可用,常用于生产者和消费者的场景
常见阻塞队列:
ArrayBlockingQueue:基于数组实现的一个阻塞队列,按照先进先出(FIFO)的原则对元素进行排序,创建ArrayBlockingQueue对象时必须
制定容量大小。有界的
LinkedBlockingQueue:基于链表实现的一个阻塞队列,默认和最大长度为Integer.MAX_VALUE,按照先进先出(FIFO)的原则对元素进行排
序。有界的
PriorityBlockingQueue :支持优先级排序的无界阻塞队列,按照元素的优先级对元素进行排序,按照优先级顺序出队,每次出队的元素都
是优先级最高的元素。无界的
put与offer,take与poll的区别:
put方法用来向队尾存入元素,如果满则等待(阻塞),直至队列可用,offer也是用来向队尾存入元素,如果满则阻塞等待一定时间,时
间到期还未存入成功,则返回一个boolean值false否则返回true;
take方法用来从队首取元素,如果空则等待(阻塞),直至队列中有元素,poll方法用来从队首取元素,如果空则等待一定的时间,当时间期限
达到时,如果取到,则返回null;否则返回取得的元素
参考:
http://ifeve.com/java-blocking-queue/
http://www.cnblogs.com/dolphin0520/p/3932906.html计算机网络
1.http与https的区别,http包含的方法
https工作原理:
1.客户端发起HTTPS请求
2.服务端的配置(证书,即公匙与私匙)
3.传送证书(即公匙)
4.客户端解析证书(客户端TSL完成检验,用公匙对随机生成的值加密)
5.传送加密信息(即随机值,让服务器得到随机值)
6.服务段解密信息(解密得到随机值,对称加密)
7.传输加密后的信息(向客户端)
8.客户端解密信息(获取解密后的内容)
http包含的方法:
1.post:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立
或已有资源的修改。
2.get:请求指定的页面信息,并返回实体主体。
3.head:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
4.put:从客户端向服务器传送的数据取代指定的文档的内容。
5.delete:请求服务器删除指定的页面。
6.connect:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
7.option:允许客户端查看服务器的性能。
8.trace:回显服务器收到的请求,主要用于测试或诊断。2.三次握手
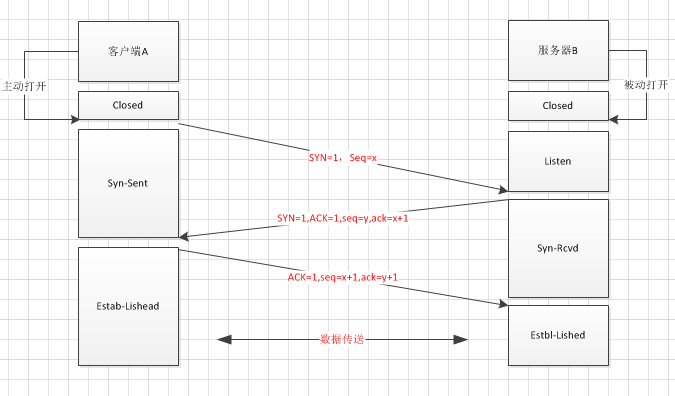
第一次握手:客户端A发送同步位SYN=1,以及选择初始序列号seq=x,同时进入SYN-SEND状态;
第二次握手:服务端B收到客户端的请求保温后,发送报文SYN=1,ACK=1,确认序列号ack=x+1,以及选择自己的初始序列号seq=y,同时进入SYN-RECV状态。
第三次握手:客户端接收到服务端的确认后,发送报文ACK=1,序列号seq=x+1,确认序列号ack=y+1,客户端与服务器进入ESTAB-LISHEAD的状
态,完成三次握手。3.四次挥手
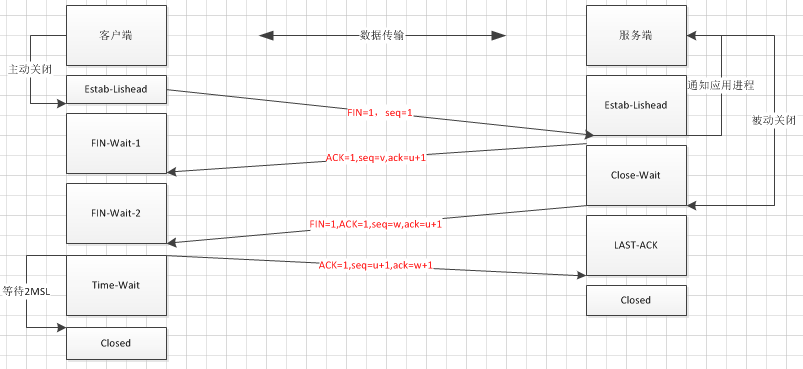
注:第一趟连接是FIN=1,seq=u
第一次挥手:客户端A发送关闭tcp连接请求报文,Fin=1,序列号seq=u(u为前面已发送的数据的最后一个字节的序列号加1);
第二次挥手:服务端接收到客户端的请求保温后,并返回一个ACK,确认序列号为ack=u+1,自己的序列号ack=v(v为前面服务端B已发送的数据的最后一个字节加1),服务端B进入CLOSED-WAIT状态;
第三次挥手:客户端A接收到服务端B的确认消息后,断开与服务器B的连接,但服务器B依旧与客户端A相连,服务器B发送的消息客户端A依然能接受,服务器B发送报文ACK=1,Fin=1,自己的序列号seq=w(半关闭状态下可能又发送了一些数据),确认序列号ack=u+1。
第四次挥手:客户端A接收到报文后,发送确认报文ACK=1,自己的序列号seq=u+1,确认序列号ack=w+1,客户端A进入TIME-WAIT状态,经过两个最大报文生存时间后关闭连接。
TIME-WAIT与CLOSE-WAIT的含义:
CLOSE-WAIT:发起TCP连接关闭的一方称为client,被动关闭的一方称为server。被动关闭的server收到FIN后,但未发出ACK的TCP状态是
CLOSE_WAIT。
TIME-WAIT:发起socket主动关闭的一方,socket将进入TIME_WAIT状态。TIME_WAIT状态将持续2个MSL(Max Segment Lifetime),在Windows下默认
为4分钟,即240秒.
TIME-WAIT持续2个最大报文生存时间的原因:
1.保证TCP协议的全双工连接能够可靠关闭(确认服务端接收到报文FIN)
2.保证这次连接的重复数据段从网络中消失(避免新老连接使用同一个端口造成数据的混淆)4.tcp与UDP的区别
1.基于连接与无连接;(tcp是面向连接的协议,udp是无连接的协议)
2.对系统资源的要求(TCP较多,UDP少);
3.UDP程序结构较简单;
4.流模式与数据报模式 ;
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。
详解:http://www.cnblogs.com/bizhu/archive/2012/05/12/2497493.html5.post与get的区别
1.原理不同:get方法的HTTP请求不会修改服务器信息,是安全方法;post方法可能会修改服务器上的资源的请求,是不安全的方法。
2.请求方式不同:get请求的数据会暴露在地址栏中,而post请求则不会,将请求放在http包的包体中。
3.安全性不同:post的安全性要比get的安全性高Mysql数据库
1.索引的分类
1.普通索引
2.唯一索引
3.主键索引
4.组合索引2.数据库事物特性
1.原子性:事物中的操作不可拆分,要么全部执行要么全部不执行。
2.隔离性:并发的事物相互隔离,不能相互干扰。
3.一致性:事物的执行不能破坏数据库的一致性,事务执行后,数据库应该从一个一致性的转台转换为另一个一致性的状态。
4.持久性:事物一旦提交,对数据的状态变更应该被永久保存。3.数据库的隔离级别(Mysql)
1.脏读(提交未读):当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会
造成两个事务得到的数据不一致
2.不可重复读(提交已读):不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间
隔,被另一个事务修改并提交了。
3.幻读(可重复读):不可重复读保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。但是,如果另一个事务同时提交了新数
据,本事务再更新时,就会发现了这些新数据,貌似之前读到的数据是幻觉,这就是幻读。
4.串行化:所有事务只能一个接一个串行执行,不能并发。
串行化级别最高,执行效率最低,对并发性的影响最高,Mysql中默认隔离级别为可重复读(Repeatable read),各个级别解决的问题:
1.脏读:级别最低,什么都无法保证
2.不可重复读:可避免脏读
3.可重复读:可避免脏读,不可重复读
4.串行化:可避免脏读,不可重复读,可重复读4.关系型数据库与非关系型(nosql)数据库的区别
1.nosql将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,查询速度nosql较快。
2.nosql的存储格式是key,value形式、文档形式、图片形式等等,关系型数据库只支持基础类型。
3.关系型数据库具有固定的表结构,扩展性差。
4.nosql不提供关系数据库对事务的处理。














 3107
3107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









