







论文:Medical Image Segmentation Using Deep Learning: A Survey
参考:[医学图像分割综述] Medical Image Segmentation Using Deep Learning: A Survey-CSDN博客
一、背景
- 特征表示的困难:模糊、噪声、对比度低--->CNN
- 属于语义分割(对图像进行像素分类)的范畴:
-
语义分割(Semantic Segmentation):语义分割的目标是将图像中的每个像素分配到一个类别。它关注的是类别,而不区分同一类别中的不同个体。例如,在一幅街景图像中,语义分割会将所有的“车”像素标注为“车”类别,而不区分这些车是不同的个体。
-
实例分割(Instance Segmentation):实例分割不仅将每个像素分配到一个类别,还要区分同一类别中的不同个体。它结合了目标检测和语义分割的特点。例如,在一幅街景图像中,实例分割不仅会标注出所有的“车”,还会区分这些车是不同的个体,给每辆车一个唯一的标识。
-
二、监督学习
1.网络骨干
1)U-Net
参考:U-Net网络结构讲解(语义分割)_哔哩哔哩_bilibili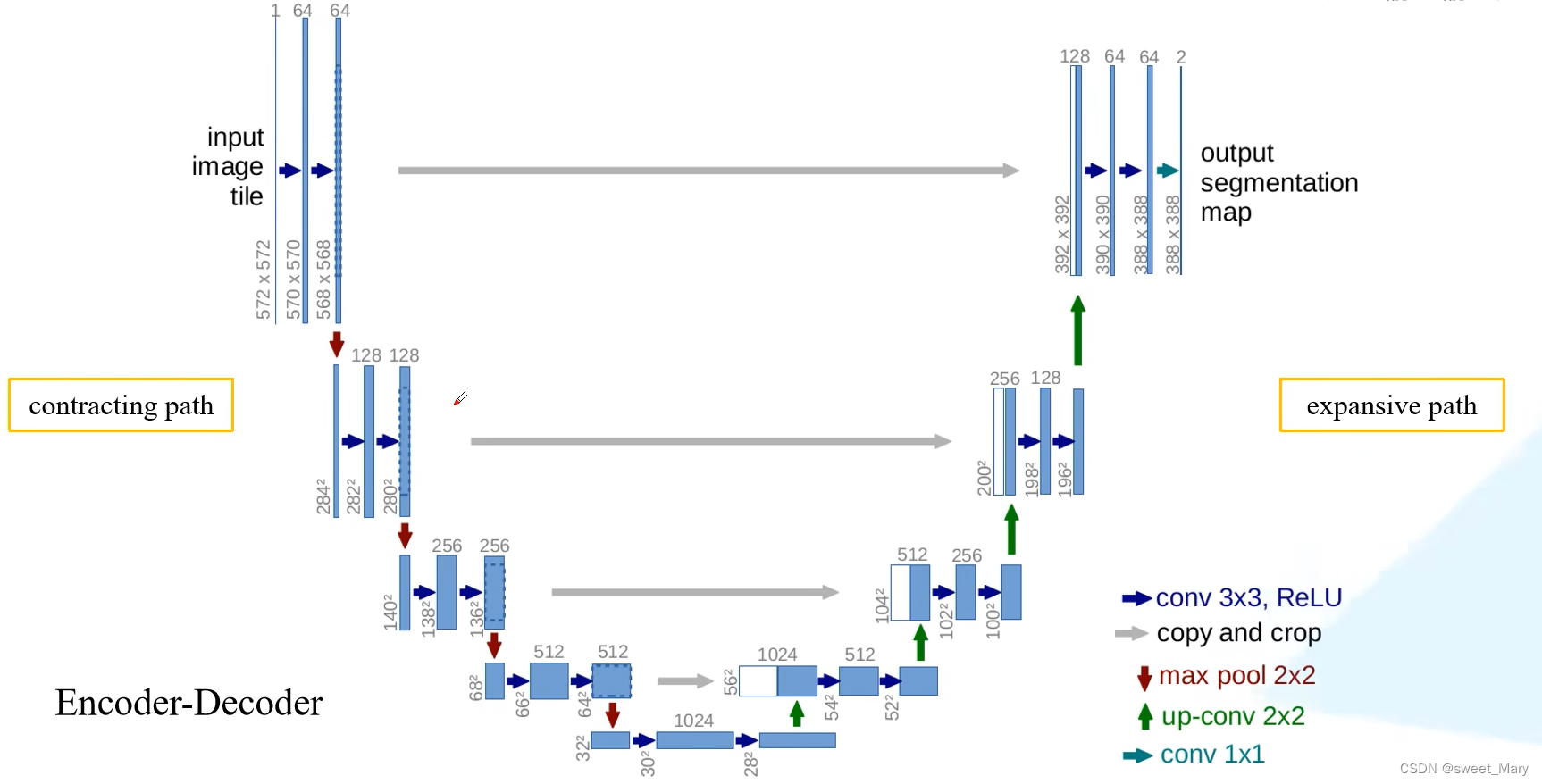
通过跳跃连接,将低分辨率和高分辨率的特征图结合起来,有效地融合了低分辨率和高分辨率的图像特征。
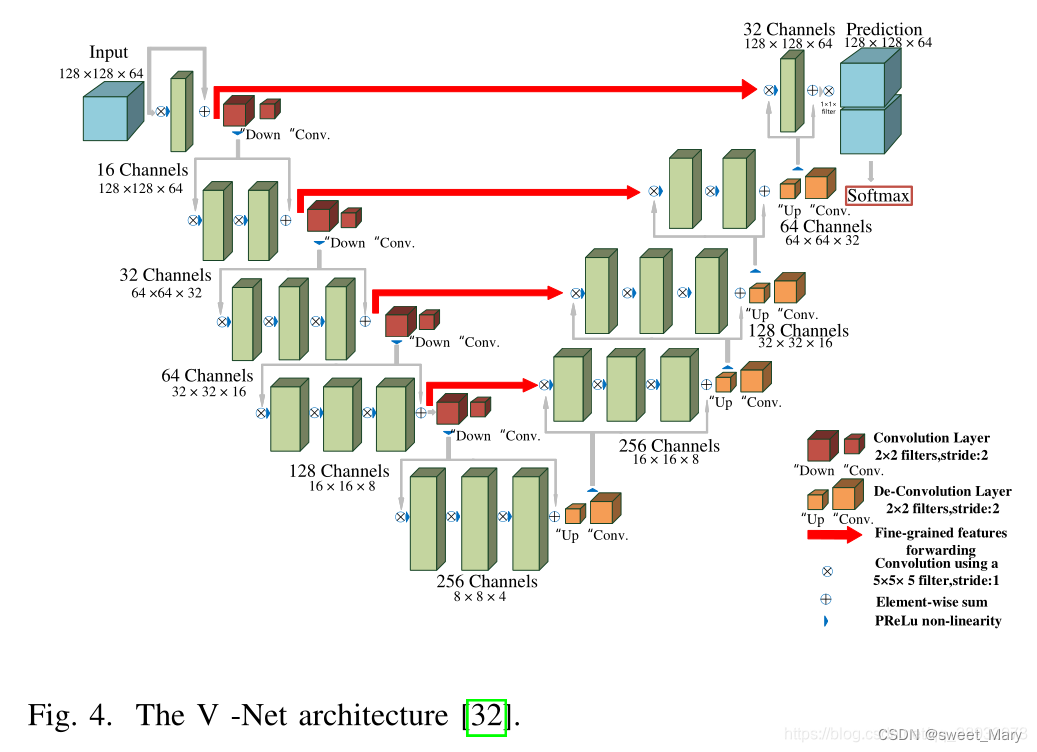
2)3D-Net
全篇为[医学图像分割综述] Medical Image Segmentation Using Deep Learning: A Survey-CSDN博客的笔记~
3D U-Net仅包含3次下采样,不能有效提取深层图像特征,导致医学图像分割精度有限。与3D-UNet相比,V-Net利用残差连接设计更深层次的网络(4次下采样),从而获得更高的性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









