







本文为博客:东哥带你刷二叉树(纲领篇) | labuladong 的算法笔记的笔记
前言
将二叉树的思想传递至动态规划,回溯算法,分治算法,图论算法!

对于二叉树的每一个结点,我们需要思考的是:如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做?
二叉树的重要性
拿快速排序和归并排序举例子
- 快速排序:二叉树的前序遍历(先确定p,再确定p的左面、p的右面)
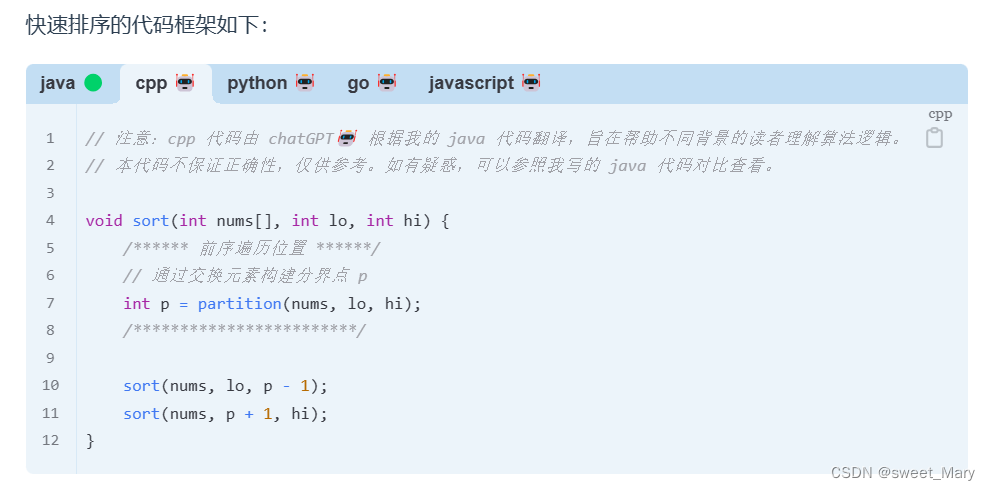
- 归并排序:二叉树的后序遍历(确定左面数组、右面数组,对两部分数组进行合并)
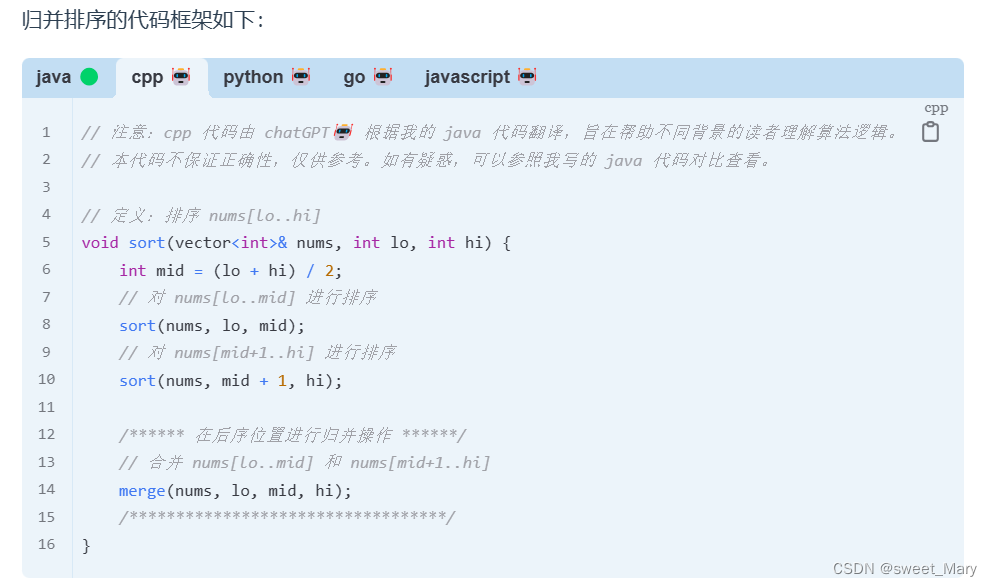
只要涉及递归,都可以抽象成二叉树的问题 (学习完二叉树将继续更新动规,回溯等算法,我们先理解好二叉树的思想)
深入理解前中后序
再推一遍:东哥带你刷二叉树(纲领篇) | labuladong 的算法笔记,写的真的好orz
哈哈,反正我是中枪了~
下面分别给出二叉树、数组、链表遍历的框架,可以思考一下有哪些共同点:
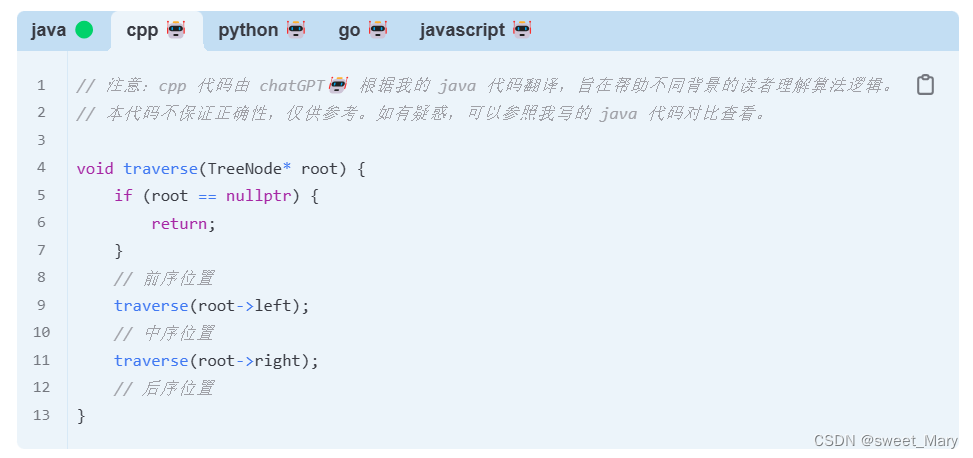


单链表、数组可以递归访问,二叉树这种结构无非就是二叉链表 ,只是无法写成迭代遍历。
所谓前序位置,就是刚进入一个节点(元素)的时候,后序位置就是即将离开一个节点(元素)的时候(这句话非常重要,先从数组、链表的角度想)
举个例子,倒序打印链表元素,你会怎么写代码?用上述第三块代码,我们可以在后续位置添加print语句,即可!正序打印在前序位置添加语句即可。二叉树也是一样,二叉树具有前序位置,中序位置,后序位置,前中后序是遍历二叉树过程中处理每一个节点的三个特殊时间点(这句话堪称我一绝哈哈哈,请反复思考orz)
!!!标重点
前序位置的代码在刚刚进入一个二叉树节点的时候执行;
后序位置的代码在将要离开一个二叉树节点的时候执行;
中序位置的代码在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候执行。
这意味着什么?这意味着你只需要在这个框架上,往前序位置/中序/后序填你想要的代码就可以;这意味着你只需要考虑一个结点就可以(考虑刚刚进入这个节点该做什么,遍历完左子树需要做什么,离开这个节点需要做什么),再回头看二叉树,是不是清晰了很多。再补东哥一句话:你可以发现每个节点都有「唯一」属于自己的前中后序位置。

现在请小朋友回前言再看最后一句话,深思ing
两种解题思路
二叉树题目的递归解法可以分两类思路,第一类是遍历一遍二叉树得出答案,第二类是通过分解问题计算出答案,这两类思路分别对应着 回溯算法核心框架 和 动态规划核心框架。
回溯算法核心框架:没有返回值,靠更新外部变量来计算结果
动态规划核心框架:有返回值,返回值是子问题的计算结果
104. 二叉树的最大深度 - 力扣(LeetCode)再来看这道题,我们用两种写法来写一遍,并且解释为什么代码放在前序/中序/后序位置?
- 我们先来写回溯式算法:
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ void traverse(TreeNode* root,int& depth,int& res){ if(root==nullptr){ return; } //前序位置 depth++; if(depth>res){res=depth;cout<<res<<endl;} traverse(root->left,depth,res); //中序位置 traverse(root->right,depth,res); //后序位置 depth--; } class Solution { public: int depth=0; int res=0; int maxDepth(TreeNode* root) { traverse(root,depth,res); return res; } };depth记录当层高度,res记录最大高度(靠更新外部变量来计算结果),在刚刚进入一个二叉树节点时,深度+1,更新res;在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候,什么都没有改变;在将要离开一个二叉树节点的时候,深度-1。

- 再来写动规式算法:(一样的模版,只不多在位置上加的东西不同)
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: int maxDepth(TreeNode* root) { if(root==nullptr){return 0;} //前序位置 int left=maxDepth(root->left); //中序位置 int right=maxDepth(root->right); //后序位置 return max(left,right)+1; } };为什么要在后序位置放代码呢,我们只考虑当前节点,高度是max(左子树高度+该结点,右子树高度+该结点),即max(left,right)+1。 所以知道左子树和右子树的高度才能知道该结点的高度,所以我们在后序位置放置代码。
是不是稍微有了一点感觉~
- 二叉树的前序遍历
我们依据这两种思路考虑一下二叉树的前序遍历,耳熟能详的是回溯式写法,也就是没有返回值,靠更新外部变量来计算结果,那么如何用动规式写法来书写呢(考虑一下哦:有返回值,返回值是子问题的计算结果),有思路吗?
一棵二叉树的前序遍历结果 = 根节点 + 左子树的前序遍历结果 + 右子树的前序遍历结果
有没有想到归并排序,只要得到根节点,得到左子树的前序遍历结果vector1,右子树的前序遍历结果vector2,把他们拼一起就好了!很巧妙吧,代码如下:
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: vector<int> preorderTraversal(TreeNode* root) { vector<int> res; if(root==nullptr){return res;} //前序位置 res.push_back(root->val); vector<int> left=preorderTraversal(root->left); //中序位置 res.insert(res.end(),left.begin(),left.end()); vector<int> right=preorderTraversal(root->right); //后序位置 res.insert(res.end(),right.begin(),right.end()); return res; } };
东哥总结:
后序位置的特殊之处
前序位置的代码只能从函数参数中获取父节点传递来的数据,而后序位置的代码不仅可以获取参数数据,还可以获取到子树通过函数返回值传递回来的数据。一旦你发现题目和子树有关,那大概率要给函数设置合理的定义和返回值,在后序位置写代码了。
543. 二叉树的直径 - 力扣(LeetCode)写一下这道题体会一下
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int res=0;
int diameterOfBinaryTree(TreeNode* root) {
dp(root);
return res;
}
int dp(TreeNode* root){
if(root==nullptr){return 0;}
//前序位置
int left=dp(root->left);
//中序位置
int right=dp(root->right);
//后序位置
res=max(res,left+right);
//cout<<left<<' '<<right<<' '<<res<<endl;
return max(left,right)+1;
}
};以树的视角看动归/回溯/DFS算法的区别和联系
动归/DFS/回溯算法都可以看做二叉树问题的扩展,只是它们的关注点不同:
- 动态规划算法属于分解问题的思路,它的关注点在整棵「子树」。
- 回溯算法属于遍历的思路,它的关注点在节点间的「树枝」。
- DFS 算法属于遍历的思路,它的关注点在单个「节点」
首先来看动态规划(看一下代码框架是否类似,注重的是否是子树)
二叉树:
动态规划:

接下来看回溯
回溯算法遍历的思路,它的着眼点永远是在节点之间移动的过程,类比到二叉树上就是「树枝」
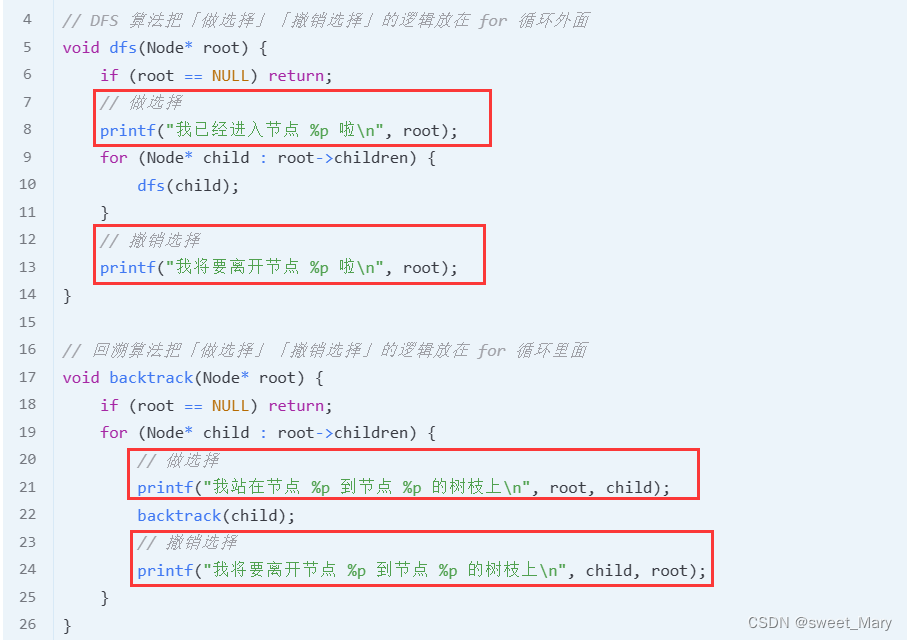
多叉树遍历:(注意看一下printf的位置)
回溯法:(注意看做选择/撤销刚才做的选择位置)

最后看dfs(和回溯很类似,区别在于做选择/撤销刚才做的选择的位置)
二叉树遍历:
dfs:

有注意回溯法和dfs的区别嘛?(后续博客会更加深入,这里先有个了解啦)
 真的很难orz(接下来我们走四个博客,大概都是和二叉树有关的)
真的很难orz(接下来我们走四个博客,大概都是和二叉树有关的)















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









