






对于菜鸡来说完成不容易。在网上看到人家两三天就写完了经常怀疑自己。不过写完也涨了一点点信心。我也并不是全职写这个proj。不过有的时候听着歌敲自己已经捋好逻辑的代码也很开心的。
代码详情见github↓↓
proj2阅读笔记
Overall Spec
have a class named gitlet.Main and that it has a main method
Your Main class should mostly be calling helper methods in the the Repository class.
- a place to store old copies of files and other metadata. All of this stuff must be stored in a directory called
.gitlet((files with a.in front are hidden files. You will not be able to see them by default on most operating systems. On Unix, the commandls -awill show them.)) - All error message end with a period “.”
- There are some failure cases you need to handle that don’t apply to a particular command. Here they are:
- If a user doesn’t input any arguments, print the message
Please enter a command.and exit. - If a user inputs a command that doesn’t exist, print the message
No command with that name exists.and exit. - If a user inputs a command with the wrong number or format of operands, print the message
Incorrect operands.and exit. - If a user inputs a command that requires being in an initialized Gitlet working directory (i.e., one containing a
.gitletsubdirectory), but is not in such a directory, print the messageNot in an initialized Gitlet directory.
- If a user doesn’t input any arguments, print the message
The Commands
文件组织架构
git
git将整个数据库储存在.git/目录下
使用add命令后
.git/objects目录下,git将信息压缩成了二进制文件。
git cat-file [-t] [-p] +filename 其中-t查看object类型是什么 blob? -p查看文件具体内容!!!
blob类型,它只储存的是一个文件的内容,不包括文件名等其他信息。然后将这些信息经过SHA1哈希算法得到对应的哈希值
commit命令后
.git/objects目录下,
**tree类型:**它将当前的目录结构打了一个快照。从它储存的内容来看可以发现它储存了一个目录结构(类似于文件夹),以及每一个文件(或者子文件夹)的权限、类型、对应的身份证(SHA1值)、以及文件名。
commit类型:储存的是一个提交的信息,包括对应目录结构的快照tree的哈希值,上一个提交的哈希值(这里由于是第一个提交,所以没有父节点。在一个merge提交中还会出现多个父节点),提交的作者以及提交的具体时间,最后是该提交的信息。
分支信息储存
在Git仓库里面,HEAD、分支、普通的Tag可以简单的理解成是一个指针,指向对应commit的SHA1值。
HEAD是文件 里面存了 ?????????
Git的三个分区
- 工作目录 ( working directory ):操作系统上的文件,所有代码开发编辑都在这上面完成。
- 索引( index or staging area ):可以理解为一个暂存区域,这里面的代码会在下一次commit被提交到Git仓库。
- Git仓库( git repository ):由Git object记录着每一次提交的快照,以及链式结构记录的提交变更历史。
pro2:
阅读gitbook
https://git-scm.com/book/zh/v2/Git-内部原理-Git-对象
11.2
功能日志11.2
命令
git init
创建目录
在commit class中,初步完成message,timestamp,parent,pathToBlobID。并传入message和parent=null进行初始化。
类
commit
实例
message
timestamp
parent
pathToBlobID
函数
public Commit(String message, List<String> parent)
public String getMessage()
public String getTimestamp()
public List<String> getParent()
public Map<String, String> getPathToBlobID()
public String toByteArray()//转化成二进制?
private String timestamp()//获得时间戳
Blob
实例
refs
content
函数
public Blob(File file)
public static File fromBlob(String SHA, File aimfile)
public void saveblob()
Tree
/*事实上我要存在index里的只有parentTree和treenodes。key再由此生成一个文件名即可* 紧接着就会由key被commit掉,从而记牢了每一个commit node的parentTree和treenodes* 因为key值可以解码出parent tree和treenodes 也就是上一个版本提交的commit key和* 现在存下来的一一对应的blob对象和文件名* /* 更新:不需要!staging area不需要文件名!只需要一个index文件就可以啦!*/
文件组织结构还需要再多想想。
比如tree的parent应该如何处理
代码日记11.3
理解了,sha1作为id,保证唯一性即可,除此之外,commit和blob这种object需要从sha1命名的文件中能够还原出来。sha1和commit的一一对应关系并不重要。
作以下思考:
sha1从object中产生有其必要性,但object需要仅仅从sha1中还原出来吗?
不需要,只需要知道我所找的sha1,也就是这个log中的message、timestamp、对应的sha1值,就可以找到sha1命名的object文件,从而还原出一整个object对象比如commit和blob。
关于getObjectById(String id, Class<T> classobject)
传入id和object class,从id文件中读出class的对象
这个错误信息 "no instance(s) of type variable(s) exist so that T conforms to Serializable" 的意思是没有类型变量
T的实例存在,使得T符合Serializable接口的要求。在 Java 中,
Serializable接口用于标记类的实例可以被序列化,即可以在网络传输或持久化到磁盘等场景下进行对象的读写操作。根据你提供的代码片段,假设你在调用
readObject()方法时遇到了这个错误。根据错误信息,可能是readObject()方法的定义要求泛型类型参数T必须符合Serializable接口,但实际传入的类型不满足这个要求。要解决这个问题,你需要确保传入的泛型类型参数
T是可序列化的,即实现了Serializable接口。你可以通过以下两种方式解决这个问题:
确保传入的类型参数
T实现了Serializable接口:public static <T extends Serializable> void getObjectById(String id, Class<T> classObject) { // ... }将泛型类型参数
T限定为可序列化的类型:public static <T> void getObjectById(String id, Class<T extends Serializable> classObject) { // ... }通过上述修改后,你可以确保传入的类型参数
T是可序列化的,从而解决这个错误。请根据你的实际需求选择适当的方式来修复这个问题,并确保传入的类型参数满足
Serializable接口的要求。
不过最后发现在commit中就实现了,但是readObject是在commit class中实现的,就不存在需要在MyUtils函数里进行参数类别的限定。
写到了tree里把新增的文件<String filename, String SHA1ID>作为节点传进去的部分。然后卡住,想到了不优雅的解,不能以一个node形式表示这个addnode。
代码日记11.6
针对节点问题
staging文件到底存什么?存暂时还是blob的东西和待提交的树。
一旦add之后,树已经形成,也就是快照已经初步形成,但是快照没有保存在commit之中。
commit要怎么形成呢?有了现在这一棵树之后?
立足于HEAD指向的上一个commit之上。
纳入现在staging中的tree(读取tree)
是不是就可以了!
不想解决了
啊啊啊啊啊啊啊
代码日记11.7
昨日bug原因:
-
通配符
通配符(Wildcard)是Java中用于表示未知类型的特殊符号。它在泛型类型中使用,允许在不确定具体类型的情况下进行灵活的类型匹配和操作。
通配符使用
?表示,可以分为两种形式:- 无界通配符:
?表示任意类型,相当于? extends Object。- 例如:
List<?>表示一个元素类型未知的列表。
- 例如:
- 有界通配符:
? extends Type或? super Type表示类型的上界或下界。? extends Type表示类型是Type或Type的子类,用于限制类型的上界。? super Type表示类型是Type或Type的父类,用于限制类型的下界。
通配符的主要作用是在泛型类型中提供灵活性,使得可以处理各种不同类型的对象,而不需要关心具体的类型参数。通过使用通配符,可以编写更通用、灵活的代码,提高代码的重用性和可扩展性。
下面是一些通配符的使用示例:
// 无界通配符 List<?> list = new ArrayList<>(); Object obj = list.get(0); // 有界通配符 List<? extends Number> numbers = new ArrayList<>(); Number number = numbers.get(0); List<? super Integer> integers = new ArrayList<>(); integers.add(10); Object obj = integers.get(0); - 无界通配符:
需要注意的是,在使用通配符时,无法往带有通配符的泛型集合中添加元素(除了null),因为编译器无法确定具体类型的安全性。但可以从带有通配符的泛型集合中获取元素,并且可以确保获取的元素是安全的。
问题:不管是commit还是tree都涉及到包含上一个tree的情况。如果是第一个tree怎么解决?
-
final关键字
final在Java中是一个保留的关键字,可以声明成员变量、方法、类以及本地变量。一旦你将引用声明作final,你将不能改变这个引用了,编译器会检查代码,如果你试图将变量再次初始化的话,编译器会报编译错误。
-
volatile关键字
简而言之是能保证在多线程中维护变量不乱套的关键字。
参考@exuanbo的代码。
tree的完整的初始化方法,取决于add方法。add的时候,首先新增一个blob,这个过程比较简单,对于tree。最重要的事情是形成一个包含新addblob的filename-blob的集合。所以如果commit仅仅只是做了init,就没有commit的tree可以读入!就只能新建一个只含一个addblob的tree。
主要是一堆空指针不知道怎么处理orz。
看了人家的 有点明白了
一个是对于暂存区多次暂存的这个进行处理。但是staging里的added到底从头开始是哪里来的?
噢 是这一步中后面给add添加项目了。
那那,岂不是staging里面没有把add放进tracktree里!!!
代码日记11.8
重新梳理add的工作
git add
在add之后,staging中,add的节点到底有没有在staging完整的track tree中?
究竟是在哪一个地方 继承上一棵树 并且添加add到树里的呢?
- staging area为空
- staging area不为空
代码日记11.9
ok
-
今天整理一下各个关键字初始化的异同
class:用于声明一个类,类是用来创建对象的模板。public、private、protected:用于声明访问权限。public表示公共访问,可以在任何地方访问;private表示私有访问,只能在同一个类内部访问;protected表示受保护的访问,可以在同一个包内和子类中访问。static:用于声明静态成员,静态成员属于类而不是对象,可以通过类名直接访问。transient是 Java 中的关键字,用于修饰类的成员变量。当一个成员变量被修饰为transient时,表示该变量不参与对象的序列化过程。final:用于声明最终的类、方法或变量。最终的类不能被继承,最终的方法不能被重写,最终的变量不能被修改。interface:用于声明接口,接口定义了一组方法和常量,可以被类实现。extends:用于表示继承关系,一个类可以继承另一个类,子类会继承父类的属性和方法。implements:用于表示接口的实现,一个类可以实现一个或多个接口,实现接口的类必须实现接口中定义的所有方法。abstract:用于声明抽象类或抽象方法。抽象类是不能被实例化的类,其中可以包含抽象方法(只有方法声明,没有具体实现)。void:用于声明方法的返回类型,表示方法没有返回值。
-
对于
private final TreeMap<String, String> add = new TreeMap<>();在给成员变量 add 添加 final 修饰符后,将会产生以下后果:
不可重新赋值:final 修饰的变量只能被赋值一次,之后不能再进行重新赋值。在这种情况下,add 成员变量在初始化后不能再被修改。
线程~!安全性:由于 add 被声明为 final,它具有不可变性。在多线程环境下,如果多个线程同时访问 add,不会出现并发修改的问题,从而提供了一定的线程安全性。
编译时常量:由于 add 被声明为 final,如果在编译时已经明确知道它的值,编译器可能会将其视为编译时常量。这意味着编译器可以在编译阶段对 add 的引用进行优化,例如直接替换成具体的值。
可以在构造函数中进行初始化:由于 add 被声明为 final,它可以在构造函数中进行初始化,并且初始化后不能再修改。这可以确保在对象创建后,add 的值保持不变。
需要注意的是,final 修饰符只对 add 这个引用变量起作用,即不能再将 add 指向另一个 TreeMap 实例,但是可以对 add 引用的 TreeMap 实例进行修改。
!!!关于在Main中使用add的时候与repository的非静态属性冲突?(因为add要调用前面private 就不能使用static)
new一个Repository(),然后就是有对象的调用了orz,而不是静态调用。
代码日记11.10
debug梳理
一步一步debug找到了一些简单的错误。
最后解决了为什么看似相同信息却能够两次commit的问题:
- add需要清空
- check add是不是clear的
- add清空之后index文件要保存!
代码日记11.12
今天完成了git log
包括嵌套调用log本身,发现了commitID没有存在对象里(transient掉了)
模式化输出日期(中文改英文)
后面好像修修补补可以自己写完了!
(除了merge
代码日记11.13
解决了add和commit中的两个小问题
-
重复添加一模一样文件 不会新增blob,也没有提示
- 增加了报错词
-
add文件、commit后继续add文件,再commit竟然可以重新commit。说明add仍然进行了。找问题,发现在staging重新加载的时候,setTrackedTree时,从上一个Commit文件中读取tree失败。为什么不在staging中存下追踪的trackTree呢?不知道。存了的话就是信息冗余。staging理论上只存增减的文件,在需要使用tracktree时从HEAD读取SHA后再找到commit复制trackTree就好了。
-
commit只存了一个文件??
一开始怀疑是putAll的问题,发现不是,putAll是可以添加所有的treemap的
然后发现是readObject并没有直接智能的把文件读到this.class里,而是空空的读取,这是不行的。
看起来还不错。
初步完成了rm
但是没有解决的是:错误输入的结果输出 或许还有其他未知的不完善的地方。
代码日记11.14
java不可以在函数定义中提供默认值,java里只能,
一种常见的方法是使用方法重载。通过定义多个具有不同参数数量的方法,并在其中的某些方法中提供默认值,可以实现在不传递参数时使用默认值的效果。
今天写checkout
不知道为什么只有最后一种是成功赋值了的?
一开始因为设置了静态变量,所以前两个都不起作用。
取消了refs和contents的static关键字后第二个起作用。
第一个应该如何修改呢?
// Blob checkoutBlob = new Blob(blobSHA);
// Blob checkoutBlob = readObject(getObjectfileById(blobSHA), Blob.class);
Blob checkoutBlob = Blob.readBlob(blobSHA);
代码日记11.15
完成find
如何判断是blob还是commit?
在chatgpt指导下,用以下函数来check Object文件夹里的文件是commit.class还是blob。
public static boolean ifObjectisCommit(File file){
try {
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
Object obj = in.readObject();
in.close();
if (obj instanceof Commit) {
return true;
} else if (obj instanceof Blob) {
return false;
} else {
return false;
}
} catch (IOException | ClassNotFoundException excp) {
throw new IllegalArgumentException(excp.getMessage());
}
}
代码日记11.16
加了一个find的报错。
写了printGloballog
代码日记11.17
对照gradescoper添加了checkout的报错,和一些小问题
还剩branch、merge、status这几个大的。
branch写了
checkout branch…
目前的想法是 1.先check当前目录是否跟踪(或者看当前目录文件的文件是否都有blob)
2.然后全删了
3.然后读取commit复原commit里的文件。
↑但都没实现
借助gpt按照:
- 获取给定分支的最新提交(commit)。
- 获取该提交中的所有文件。
- 遍历这些文件,将它们复制到工作目录中,覆盖已经存在的文件。
- 检查当前分支是否与给定分支相同。如果不同,更新当前分支为给定分支。
- 检查当前分支中被追踪的文件是否在给定分支中存在。如果不存在,删除这些文件。
- 清空暂存区(staging area),除非当前分支与给定分支相同。
来实现
但是这个删除文件这一步有点问题,主要因为在check文件是否都追踪的时候有一些杂项文件干扰。
写不动了×2
改不动了orz
代码日记11.20
修改了reset
rm和add以及commit中的一些逻辑。
但是关于rm file的一些逻辑没写好,按道理应该能rm add里的文件,但是grader测试会输出no file;
把MASTER→master
代码日记12.5
• 增加了:Failure cases: If the file is neither staged nor tracked by the head commit, print the error message No reason to remove the file.
• 写了rm-branch
• 更改了style
问题:
grader37:reset
代码日记12.12
看reset
似乎branch本身只是新建一个分支,并不改变当前分支是哪个,也就是不改变head(完成)
- 28 29 31 37 38除了status理论上都解决了,也就是关于checkout和reset的一些bug。主要是对于给定一个sha是不是commit object的判断,也没有大问题,之前忘记切割
- 以及这个37相当的离谱,说好了reset 的时候有unstage要报错的! 前一步刚刚add,后一步reset竟然不给输出,那我就没办法了。
代码日记12.14
-
完成了status🎉
-
解决了reset1的bug,感谢知乎评论:
至此,基础部分除了merge都完成了,今年之内完成有望!
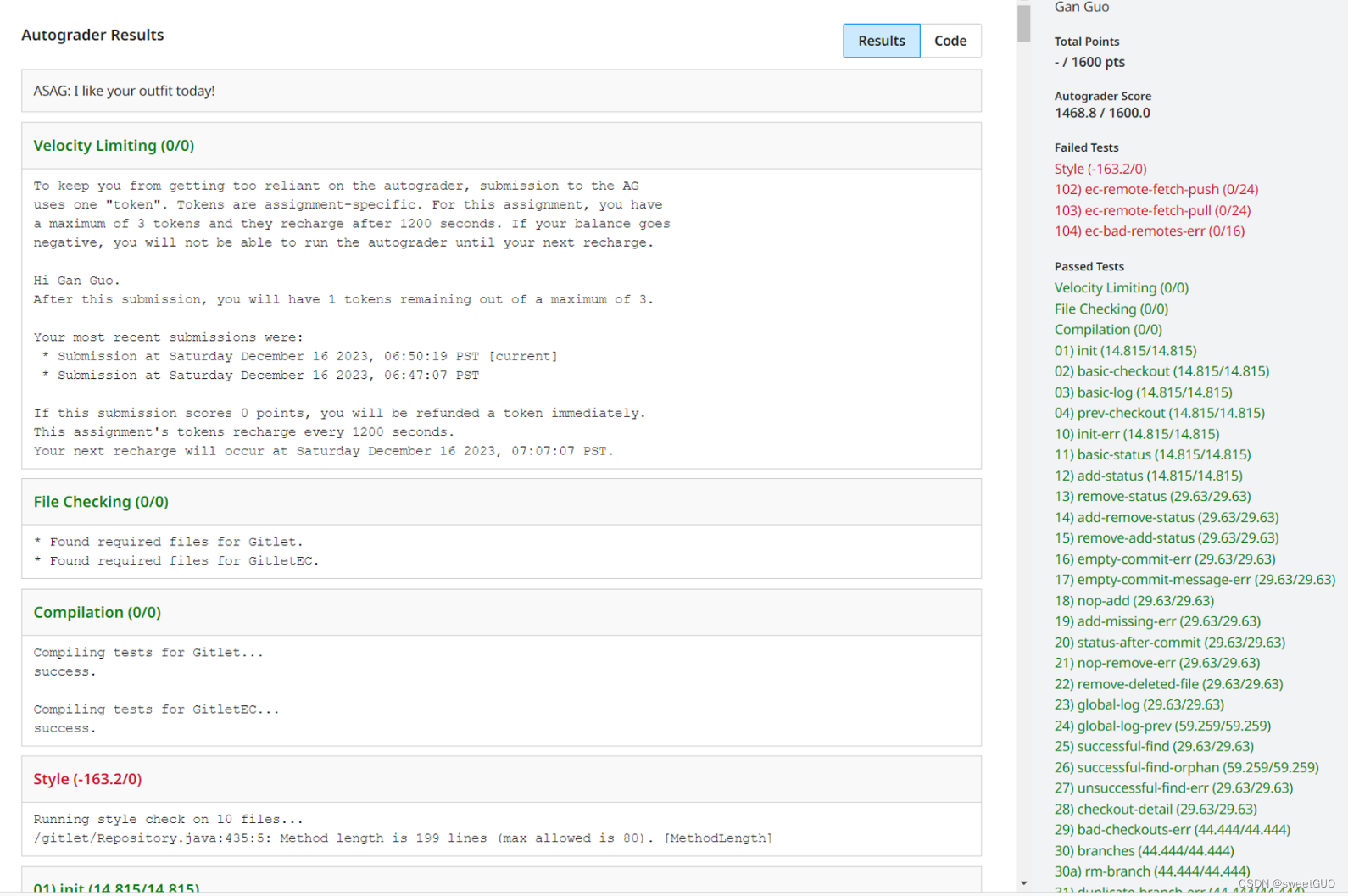
12/16吭哧吭哧好久
写完了md















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









