







参考
《gcc源码分析》
词法分析
词法分析的过程就是将源代码识别成一个一个的词法符号,并在词法分析的过程中创建一些树节点,用来保存某些词法符号的值(value)。这些需要创建树节点的词法符号主要包括标识符(CPP_NAME)、关键字(CPP_KEYWORD)、数值(CPP_NUMBER)常量等。在后续的语法分析过程中,会将这些AST节点(或者AST子树)根据语法规则链接起来,形成某个函数完整的AST结构。
语法分析
语法分析就是,提前预读两个词法符号的自顶向下的语法推导过程:包括提前预读词法符号,语法分析状态以及上下文信息。
这些信息通常将保存在c_parser 这个结构体当中:
/* A parser structure recording information about the state and
context of parsing. Includes lexer information with up to two
tokens of look-ahead; more are not needed for C. */
typedef struct c_parser GTY(())
{
/* The look-ahead tokens. */
c_token tokens[2];
/* How many look-ahead tokens are available (0, 1 or 2). */
short tokens_avail;
/* True if a syntax error is being recovered from; false otherwise.
c_parser_error sets this flag. It should clear this flag when
enough tokens have been consumed to recover from the error. */
BOOL_BITFIELD error : 1;
/* True if we're processing a pragma, and shouldn't automatically
consume CPP_PRAGMA_EOL. */
BOOL_BITFIELD in_pragma : 1;
/* True if we're parsing the outermost block of an if statement. */
BOOL_BITFIELD in_if_block : 1;
/* True if we want to lex an untranslated string. */
BOOL_BITFIELD lex_untranslated_string : 1;
/* Objective-C specific parser/lexer information. */
BOOL_BITFIELD objc_pq_context : 1;
/* The following flag is needed to contextualize Objective-C lexical
analysis. In some cases (e.g., 'int NSObject;'), it is
undesirable to bind an identifier to an Objective-C class, even
if a class with that name exists. */
BOOL_BITFIELD objc_need_raw_identifier : 1;
} c_parser;
gcc对c语言进行语法分析的入口函数为c_parse_file :
/* Parse a single source file. */
void
c_parse_file (void)
{
/* Use local storage to begin. If the first token is a pragma, parse it.
If it is #pragma GCC pch_preprocess, then this will load a PCH file
which will cause garbage collection. */
c_parser tparser;
memset (&tparser, 0, sizeof tparser);
the_parser = &tparser;
if (c_parser_peek_token (&tparser)->pragma_kind == PRAGMA_GCC_PCH_PREPROCESS)
c_parser_pragma_pch_preprocess (&tparser);
the_parser = GGC_NEW (c_parser);
*the_parser = tparser;
c_parser_translation_unit (the_parser);
the_parser = NULL;
}
预读一个符号
预读一个符号,如果是PRAGMA_GCC_PCH_PREPROCESS,将进行编译的预处理工作,c_parser_pragma_pch_preprocess 为预处理函数。
c_parser_peek_token 会解析出一个token,这时会返回指向下个token的指针:
/* Return a pointer to the next token from PARSER, reading it in if
necessary. */
static inline c_token *
c_parser_peek_token (c_parser *parser)
{
if (parser->tokens_avail == 0)
{
c_lex_one_token (parser, &parser->tokens[0]);
parser->tokens_avail = 1;
}
return &parser->tokens[0];
}
解析一个单独的词法符号时,调用c_lex_one_token
/* Read in and lex a single token, storing it in *TOKEN. */
static void
c_lex_one_token (c_parser *parser, c_token *token)
{
timevar_push (TV_LEX);
token->type = c_lex_with_flags (&token->value, &token->location, NULL,
(parser->lex_untranslated_string
? C_LEX_STRING_NO_TRANSLATE : 0));
token->id_kind = C_ID_NONE;
token->keyword = RID_MAX;
token->pragma_kind = PRAGMA_NONE;
switch (token->type)
{
case CPP_NAME:
{
tree decl;
bool objc_force_identifier = parser->objc_need_raw_identifier;
if (c_dialect_objc ())
parser->objc_need_raw_identifier = false;
if (C_IS_RESERVED_WORD (token->value))
{
enum rid rid_code = C_RID_CODE (token->value);
if (rid_code == RID_CXX_COMPAT_WARN)
{
warning_at (token->location,
OPT_Wc___compat,
"identifier %qs conflicts with C++ keyword",
IDENTIFIER_POINTER (token->value));
}
else if (c_dialect_objc ())
{
if (!objc_is_reserved_word (token->value)
&& (!OBJC_IS_PQ_KEYWORD (rid_code)
|| parser->objc_pq_context))
{
/* Return the canonical spelling for this keyword. */
token->value = ridpointers[(int) rid_code];
token->type = CPP_KEYWORD;
token->keyword = rid_code;
break;
}
}
else
{
token->type = CPP_KEYWORD;
token->keyword = rid_code;
break;
}
}
decl = lookup_name (token->value);
if (decl)
{
if (TREE_CODE (decl) == TYPE_DECL)
{
token->id_kind = C_ID_TYPENAME;
break;
}
}
else if (c_dialect_objc ())
{
tree objc_interface_decl = objc_is_class_name (token->value);
/* Objective-C class names are in the same namespace as
variables and typedefs, and hence are shadowed by local
declarations. */
if (objc_interface_decl
&& (global_bindings_p ()
|| (!objc_force_identifier && !decl)))
{
token->value = objc_interface_decl;
token->id_kind = C_ID_CLASSNAME;
break;
}
}
token->id_kind = C_ID_ID;
}
break;
case CPP_AT_NAME:
/* This only happens in Objective-C; it must be a keyword. */
token->type = CPP_KEYWORD;
token->keyword = C_RID_CODE (token->value);
break;
case CPP_COLON:
case CPP_COMMA:
case CPP_CLOSE_PAREN:
case CPP_SEMICOLON:
/* These tokens may affect the interpretation of any identifiers
following, if doing Objective-C. */
if (c_dialect_objc ())
parser->objc_need_raw_identifier = false;
break;
case CPP_PRAGMA:
/* We smuggled the cpp_token->u.pragma value in an INTEGER_CST. */
token->pragma_kind = (enum pragma_kind) TREE_INT_CST_LOW (token->value);
token->value = NULL;
break;
default:
break;
}
timevar_pop (TV_LEX);
}
语法分析函数调用关系
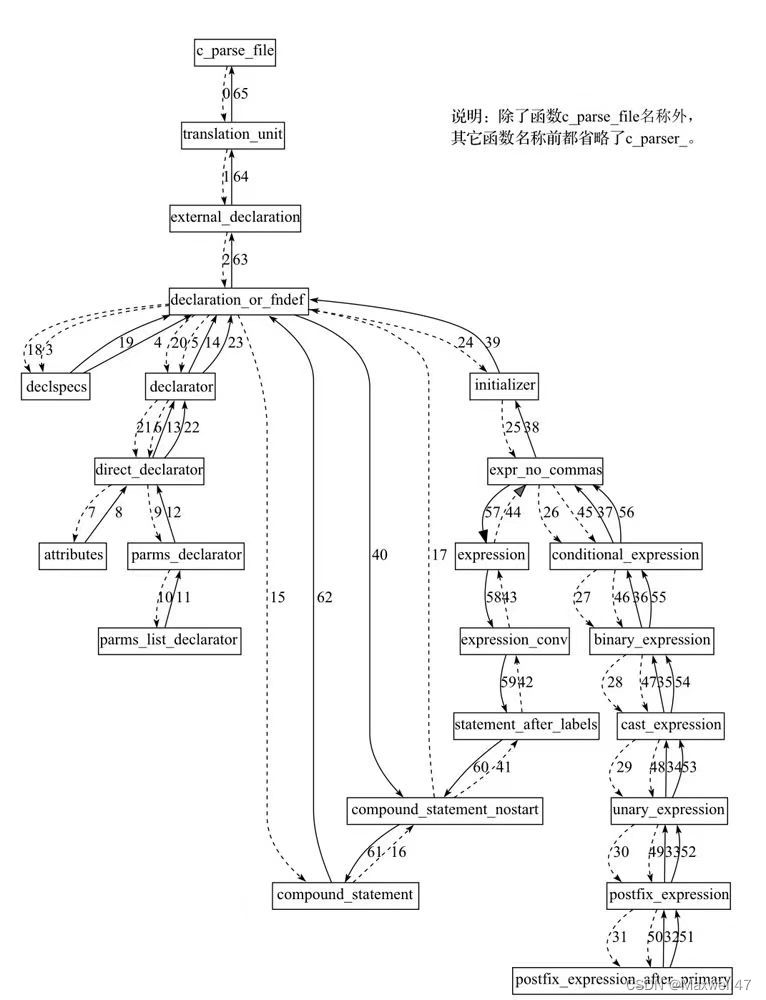
重点函数分析
c_parse_file
函数c_parse_filer如上所述,是C语法分析的入口函数,该函数首先对当前的词法符号进行判断,如果该符号的编译制导类型是PRAGMA_GCC_PCH_PREPROCESS,则调用函数c_parser_pragma_pch_preprocess对进行源代码的预处理,否则,调用函数c_parser_translation_unit()进行语法推导。
c_parser_translation_unit
这个函数是进行语法分析的主流程函数:
















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









