







Zeppelin的组成
Zeppelin的基本功能介绍可 参考文章:https://blog.csdn.net/spacewalkman/article/details/62135285
Zeppelin程序的基本结构如下(这里只画出主要部件,方便大家理解):
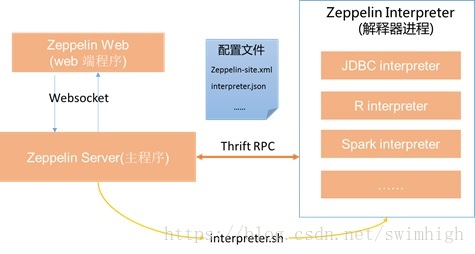
Zeppelin Server: Zeppelin主程序,启动时通过配置,加载war包提供WEB 服务,通过Websocket协议与WEB端程序交互;负责启动解释器进程,并通过apache thrift协议与各种解释器进程通讯。Zeppelin Server接收Web端发过来的用户请求,并响应,当用户需要执行远程解释器段落(paragraph)程序时,Zeppelin Server 通过thrift 远程调用解释器进程执行程序,并返回结果。
Zeppelin Web:与用户交互的WEB端程序,包含登录、NOTE创建、paragraph编辑、执行等功能。
Zeppelin Interpreter:Zeppelin解释器进程,是一系列进程列表,由Zeppelin Server调用interpreter.sh脚本启动,在Zeppelin中除了运行服务器命令(shell)和MarkDown 解释任务之外基本上都是启动单独的进程执行的(SPARK\R…)。
Zeppelin源代码分析
对于Zeppelin的源代码,我们将分为以下三个主要脉络进行分析,把这三个主要脉络了解透彻了,其他代码的熟悉只是时间问题:
脉络一:Zeppelin Server启动过程。(Zeppelin Server功能原理分析及其与Web端的通讯原理)
脉络二:Note 中Paragraph 的执行过程。
脉络三:interpreter的启动及执行过程。(这里仅分析一两种典型的interpreter)
Zeppelin的主要原代码目录如下所示:
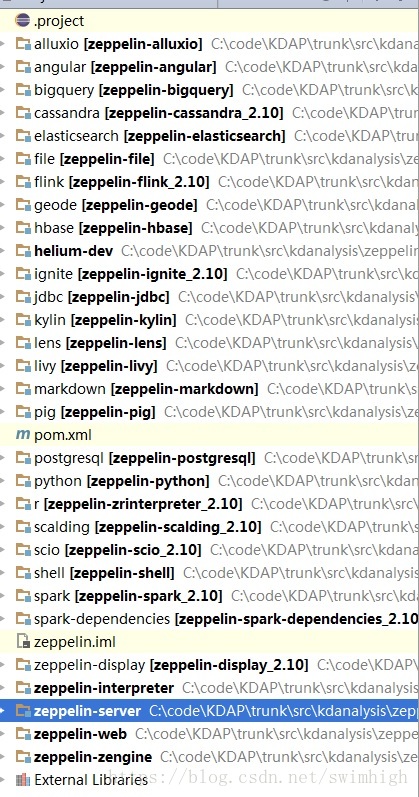
zeppelin-server、zeppelin-zengine 、zeppelin-interpreter、zeppelin-web 目录为zeppelin的主要源代码目录。
Zeppelin Server 启动过程
Zeppelin Server 中的main 函数的主要处理过程如下图所示:

Zeppelin Server 程序的入口类为:\zeppelin-server\src\main\java\org\apache\zeppelin\server\ZeppelinServer.java。
Zeppelin Server 中main的主要函数过程为下图中的红框部分:

主要功能过程就是,根据 zeppelin-site.xml中的配置,启动jetty,并提供Notebook的WebSocket服务,这里需要熟悉Jetty的API使用,以及Jetty websocket编程。
如下图代码所示,WebSocket服务主要由NotebookServer类完成,请求都发到“/ws/” 路径
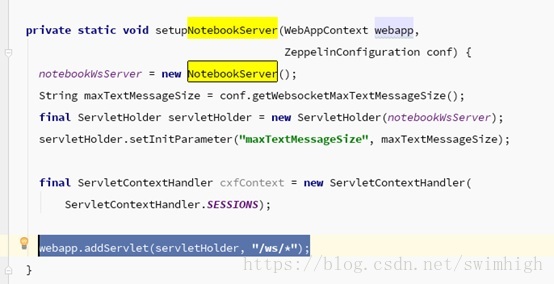
Web 端请求过来的消息通过NotebookServer类中的 onMessage函数进行异步处理:
switch (messagereceived.op) {
case LIST_NOTES:
unicastNoteList(conn, subject, userAndRoles);
break;
case RELOAD_NOTES_FROM_REPO:
broadcastReloadedNoteList(subject,userAndRoles);
break;
case GET_HOME_NOTE:
sendHomeNote(conn, userAndRoles,notebook, messagereceived);
break;
case GET_NOTE:
sendNote(conn, userAndRoles,notebook, messagereceived);
break;
case NEW_NOTE:
createNote(conn, userAndRoles,notebook, messagereceived);
break;
case DEL_NOTE:
removeNote(conn, userAndRoles,notebook, messagereceived);
break;
case REMOVE_FOLDER:
removeFolder(conn, userAndRoles,notebook, messagereceived);
break;
case MOVE_NOTE_TO_TRASH:
moveNoteToTrash(conn, userAndRoles,notebook, messagereceived);
break;
case MOVE_FOLDER_TO_TRASH:
moveFolderToTrash(conn,userAndRoles, notebook, messagereceived);
break;
case EMPTY_TRASH:
emptyTrash(conn, userAndRoles,notebook, messagereceived);
break;
case RESTORE_FOLDER:
restoreFolder(conn, userAndRoles,notebook, messagereceived);
break;
case RESTORE_NOTE:
restoreNote(conn, userAndRoles,notebook, messagereceived);
break;
case RESTORE_ALL:
restoreAll(conn, userAndRoles,notebook, messagereceived);
break;
case CLONE_NOTE:
cloneNote(conn, userAndRoles,notebook, messagereceived);
break;
case IMPORT_NOTE:
importNote(conn,userAndRoles, notebook, messagereceived);
break;
case COMMIT_PARAGRAPH:
updateParagraph(conn, userAndRoles,notebook, messagereceived);
break;
case RUN_PARAGRAPH:
runParagraph(conn, userAndRoles, notebook,messagereceived);
break;
这里面大多数函数都是本地执行,runParagraph 为远程执行函数,通过Thrift调用interpreter进程中的函数。即下一章《Paragraph 的执行过程》所要讲的内容。
Paragraph 的执行过程
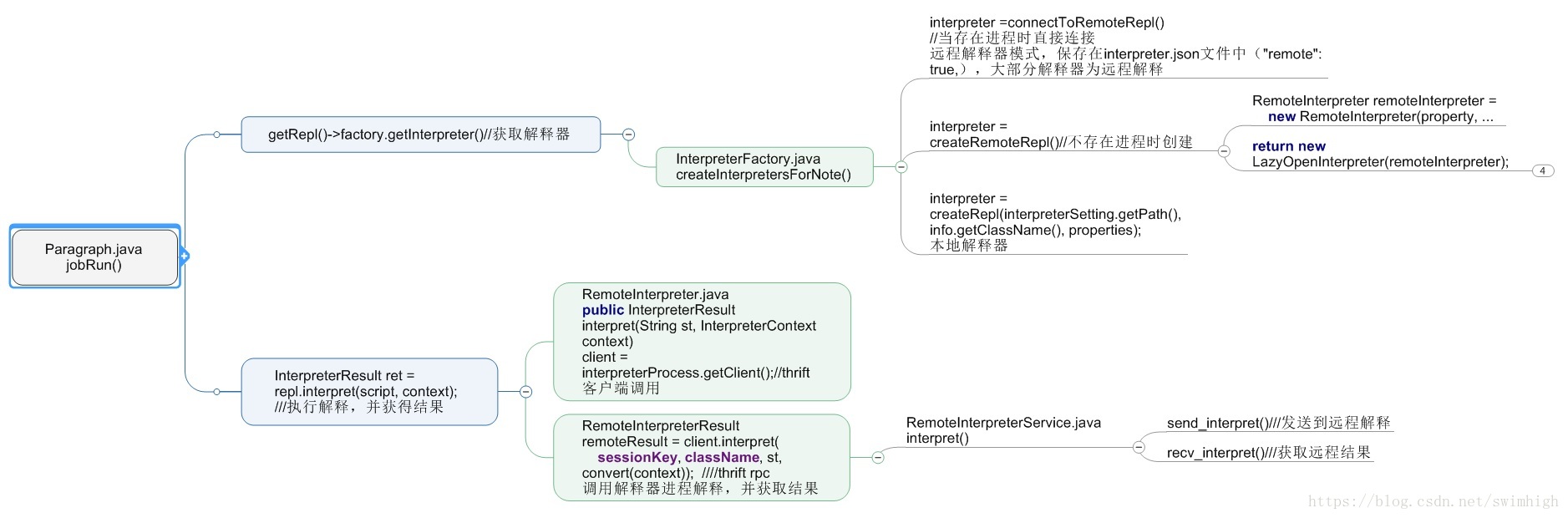

Paragraph(note中的段落)的执行是整个Zeppelin的功能核心,其过程如上图所示(由于这个过程比较深,所以把图拆成了两部分)。
通过上一章中的NotebookServer类中的 onMessage函数进入runParagraph 函数后,最后会执行到Paragraph.java 中的jobRun()函数,jobRun()函数主要分为两个步骤:
1、 getRepl()->factory.getInterpreter()//获取解释器,没有进程运行时,新建
2、 InterpreterResult ret = repl.interpret(script, context); ///执行解释,并获得结果
在新建解释器进程的过程中主要调用InterpreterFactory.java createInterpretersForNote(),具体过程在第二张图中有体现,最终调用 executor.execute(cmdLine,procEnv, this); //apache 的执行库,能启动一个新的JVM里程。
在执行解释的过程中(repl.interpret),主要通过apache thrift协议调用远程interpreter进程的interpret函数,当然也有本地解释器的执行,通过调用本地解释器的interpret函数即可。
这里还有个回应答的过程:
1、 调用解释器返回应答很简单,函数直接返回RemoteInterpreterResult:
RemoteInterpreterResultremoteResult = client.interpret( sessionKey, className, st, convert(context)); thrift rpc 调用解释器进程解释,并获取结果
2、 Web端的应答是异步的,通过unicast可以回复:

Interpreter的启动及执行过程
前面一单中Zeppelin Server在第一次执行runParagraph 函数时,其实就已经将Zeppelin interpreter进程启动了。
关于Zeppelininterpreter的启动和通讯原理(apache thrift),CSDN中已有相关的详细文章,我这里就不再详述了,请参考如下URL:
https://blog.csdn.net/spacewalkman/article/details/69230145
根据不同的interpreter配置,启动不同的进程,Zeppelin interpreter有多种运行模式,同一类型的interpreter可以运行在共享的同一进程,也可以是多个不同的进程,根据具体配置而定。
下面主要分析一个典型的 interpreter以理解其执行过程:
JDBC解释器:[zeppelin-jdbc] 程序目录为:jdbc\src\main\java\org\apache\zeppelin\jdbc\,主类入口为 JDBCInterpreter.java
Zeppelin 的所有解释器(interpreter)类都必须继承自Interpreter 类 :
public class JDBCInterpreter extends Interpreter
JDBCInterpreter 被主程序加载后,会调用open()函数,这个函数基本上是一些配置信息的获取,这里不细讲。
Zeppelin Server在运行Zeppelin interpreter会通过 RPC调用到JDBCInterpreter的Interpret()函数,该函数的主要运行脉络如下图所示:

原理其实很简单,就是先通过JDBC连接数据库(连接过的解释器可直接从连接池获取HANDLE),然后再通过JAVA的API执行SQL。
返回的查询结果,直接通interpreterResult对像返回给Zeppelin Server。
interpreterResult.add(
getResults(resultSet, !containsIgnoreCase(sqlToExecute,EXPLAIN_PREDICATE)));
至此,Zeppelin 的源代码分析告一段落,Zeppelin 运行的主要原理已经明确,希望对从事大数据分析的程序员有所帮助,欢迎大家批评指正!














 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









